SEO内参全文
一、SEO内参(1):百度搜索引擎的工作原理及流程
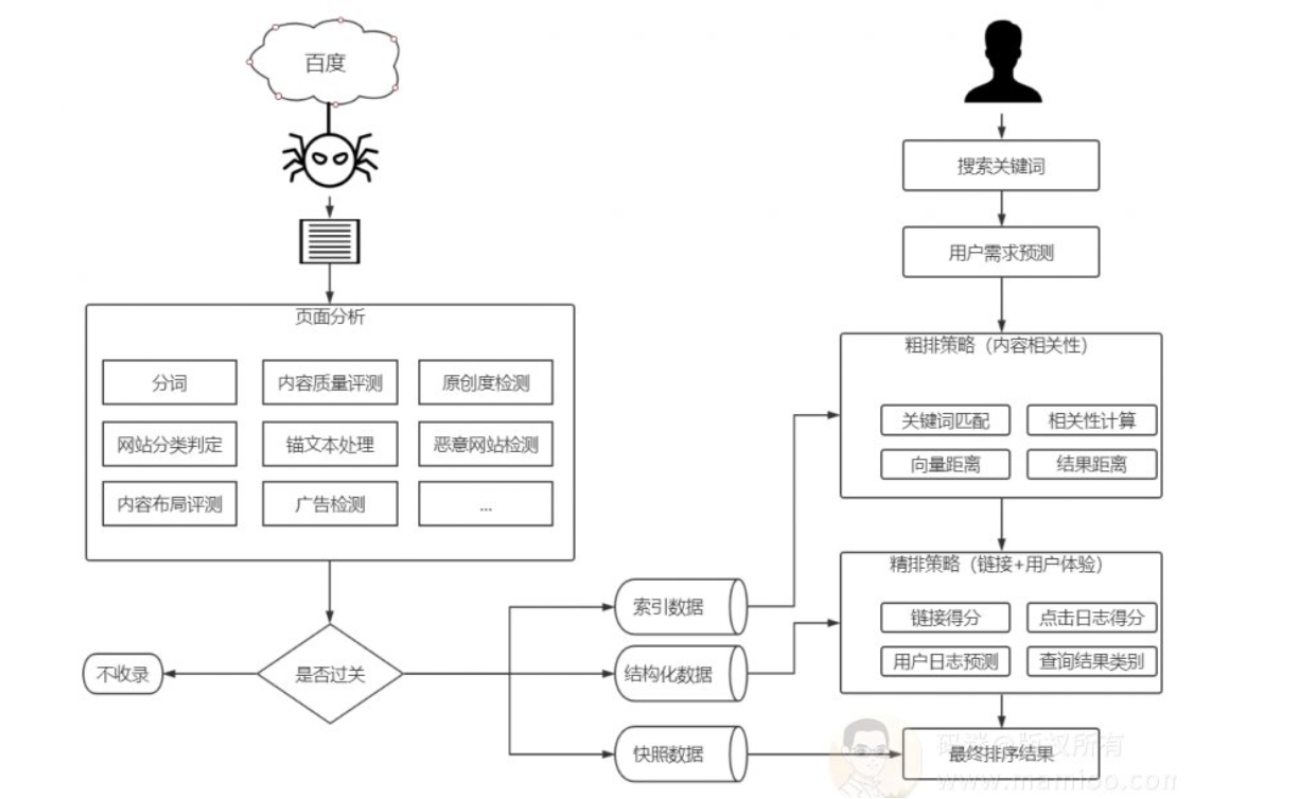
众所周知,百度的搜索引擎系统分为:抓取系统、快照存储系统、页面分析系统、索引系统、检索召回系统等几个重要系统。关于百度搜索引擎的基本原理和流程,大家可以参考痞子瑞的《SEO深度解析》一书中的“搜索引擎原理”部分。

码迷这一部分与痞子瑞老师的略有不同,对百度搜索引擎的基本原理和流程做了更深入的拆解分析。
碎碎念
很多同行说做百度SEO越来越难了,说百度等搜索引擎的份额被如今的自媒体抢占了很多流量,SEO没法做了云云。
但是很多公司反馈,百度的流量转化率还是要高于抖音之类的自媒体。
我觉得SEO并不是越来越难,只是你没有改变而已。
经过十几年的发展,百度搜索引擎已经发生了很多很多的变化,而你还是原地踏步而已。我从12左右开始接触SEO,优化的手段也不断的升级迭代,但是很多同行的手段却一直停留在16年之前了。
做SEO没有长久的“秘笈”,重要的是主动跟上搜索引擎算法步伐,然后做实验找规律,再用合理的手段把优化做到极致就行了。
基本概述
很多书籍对搜索引擎原理仅仅提到了倒排索引,而更多的书籍只是将内容处理、链接处理、用户体验稍微说了一下。
其实百度搜索引擎是一项十分复杂的工程,搜索引擎除了做正向好事儿,如防作弊、提拔优质内容等等、还有些不乖乖的处理流程,如人工干预、圈流量策略也是很重要的一块。
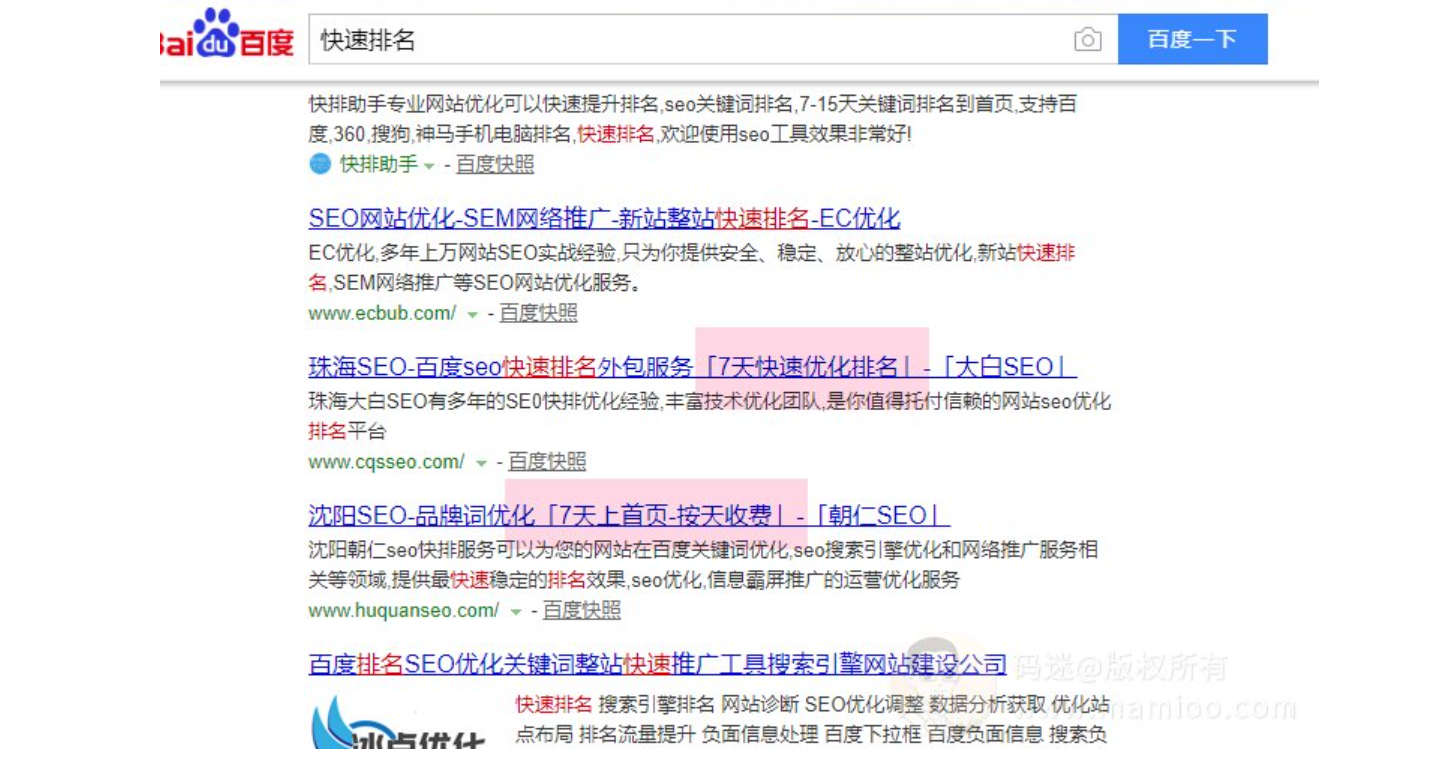
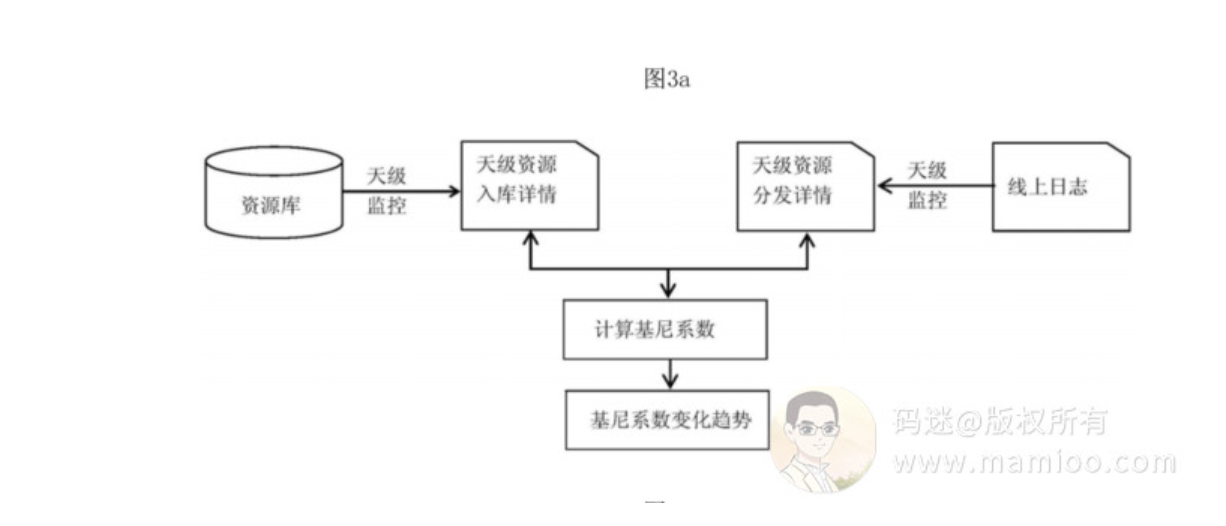
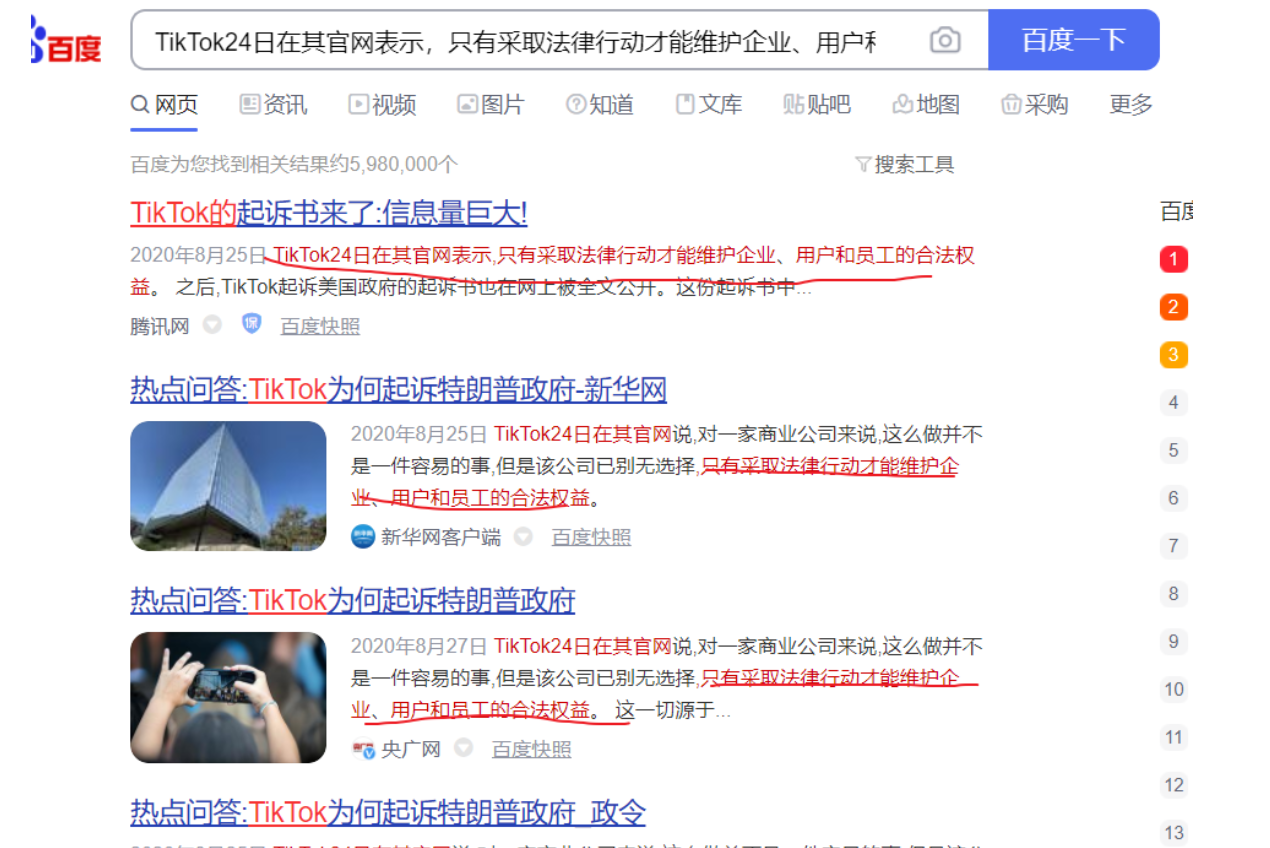
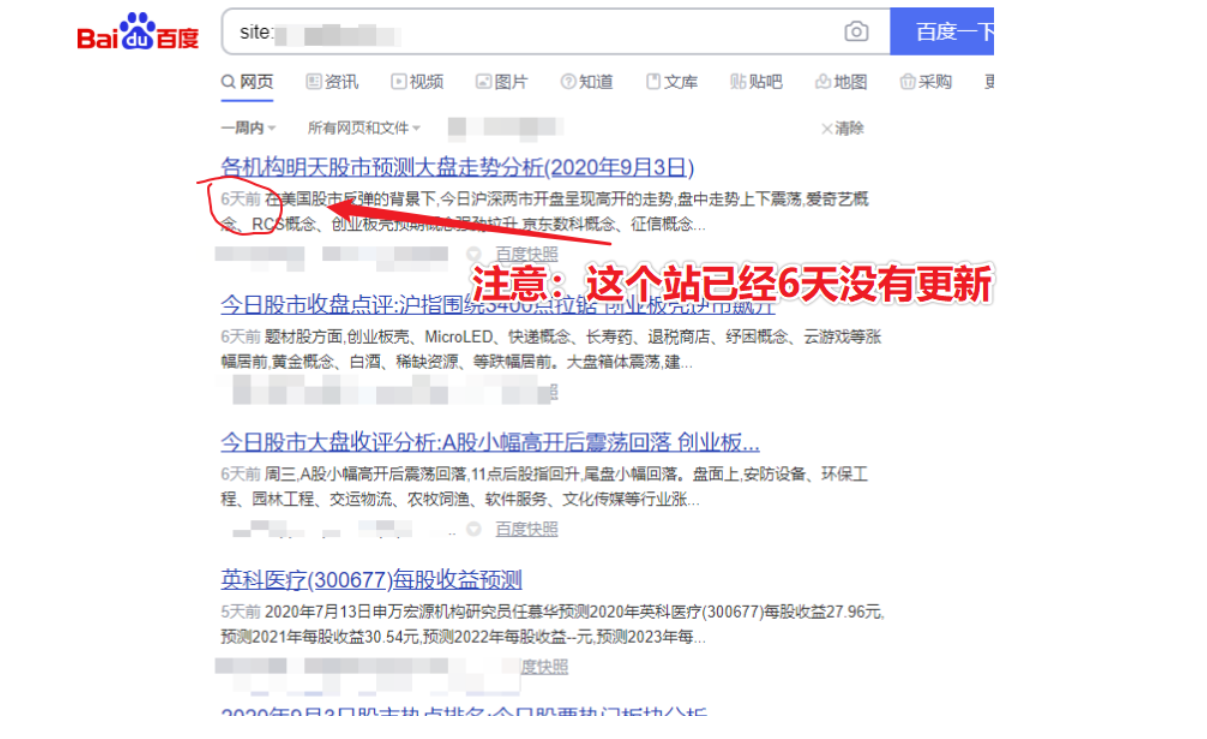
码迷认为搜索引擎的大体架构如图:
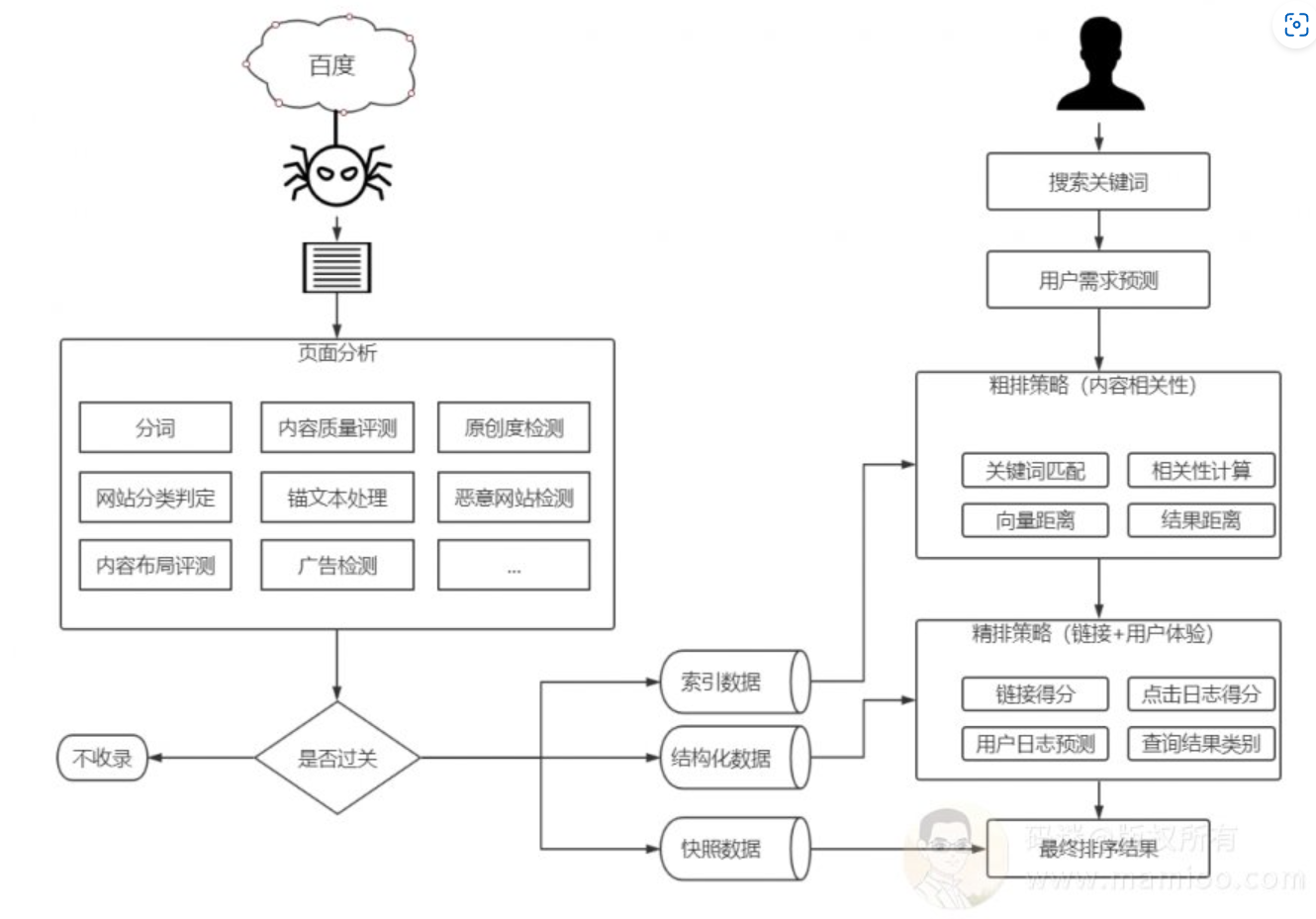
大致分为百度爬取、百度查询2个部分。
百度爬取部分
步骤01
百度爬虫发现网页,爬取网页html内容
步骤02
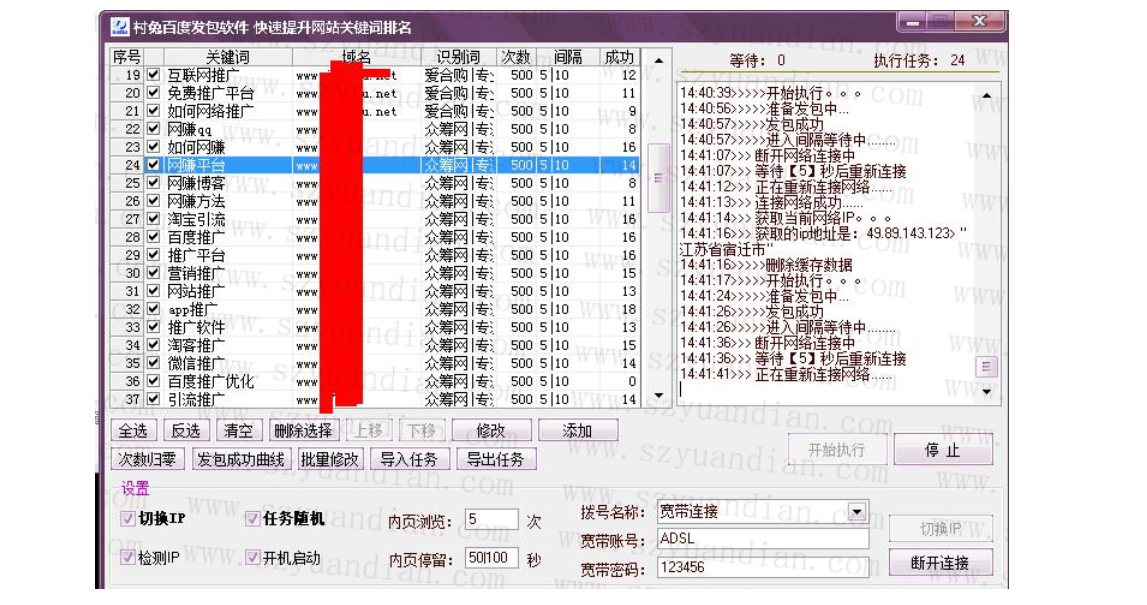
百度对爬回来的网页进行初步的页面分析。先进行分词,去除停止词。
步骤03
这一步主要做初步网页评定。
对分词后的网页通过向量空间模型初步做分类判定;
通过相关性算法提取相关词,判定主题集中程度;
通过结构相似性、文本相似性算法判定原创度;
通过信息熵等手段判定是否有恶意广告;
最后进入反*黄*赌*毒*系统等等。
步骤04
如果内容过关,百度将该网页分词结果存取到有效索引倒排中,并抽取网页内容结构化数据(标题、摘要、内容等等),快照存档。
百度查询部分
步骤01
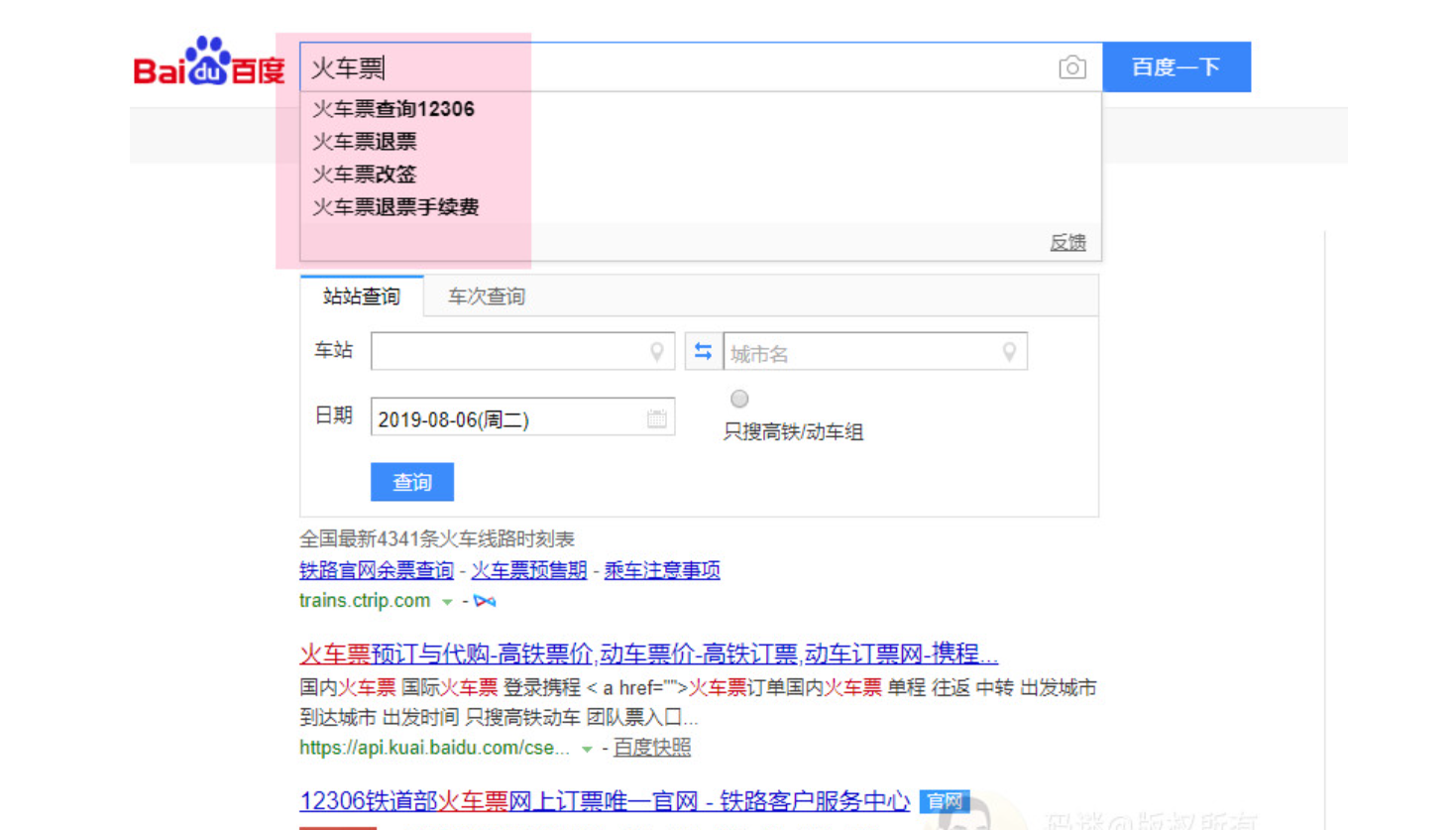
首先对用户输入的查询词分词处理,通过用户地理位置、个性化信息、机器学习预测查询词的实体类型,预测第2需求词,第3需求词等。
比如搜“火车票”,那么“火车票查询”、“火车票12306”、“火车票改签”这些需求词也将会纳入用户需求中。第N需求词,也叫后续词,通过对后续词做文章,也可以优化排名。
如何用后续词获取排名,码迷稍微在之前的博文黑帽SEO案例分析:配合「摩天楼SEO工具」浅析黑帽大神的SEO手段做了提及,如果你功夫到家,自然也会明白逆冬的手段。如果看不出来也没关系,码迷会在以后的章节中会详细给大家讲。
步骤02 粗排环节
“粗排”这个概念,码迷最先见于Zero的公众号文章《我是如何把「SEO」这词排名到百度首页的》,链接地址:zhuanlan.zhihu.com
粗排是百度通过布尔模型,在海量信息中查找符合需求词组的N个文档。再通过与训练好的结果模型做向量距离比较,过滤出M个文档,再通过结果距离算法获取前O个文档集合,再通过BM25相关性得分取出TOP760文档集合。
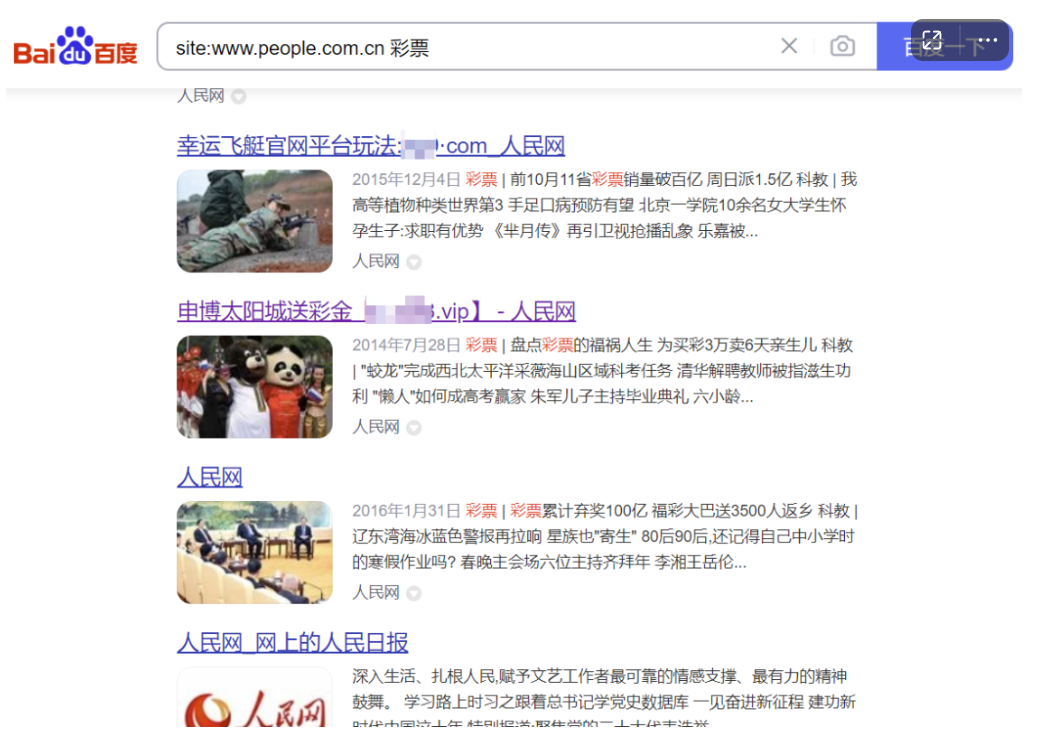
比如百度专利《201610214064.0信息搜索方法和装置》中举了,刘德华老婆的例子。你搜“刘德华老婆”的时候,如果你的页面里面没有“朱丽倩”,说明网页内容很差,很大程度上进不了粗排队列。

比如:摩天轮内容助手这款工具,可以精准预测到相关词,让网页排名更靠前。
步骤03 细排环节
综合每个文档对应的链接权重得分、点击日志得分、网页加载速度、相关性得分、查询结果类别策略等,再塞入人工干预的内容,结合用户日志分析(快排)将最终的排序结果呈现给用户。
大家喜闻乐见的、经久不衰的快速排名手段,如“7天上首页”,就是干预精排中的点击策略,影响了百度预测的正向结果模型,促使短期上首页。
总结
公司的终极目的都是为了赚钱,我们做SEO也是为了圈住部分流量来赚钱。
即使如今的百度已经不再单纯很久了,越来越多的干预搜索结果,这也是历史的必然。
如何在艳红眼皮底下获取更多的流量,我们从下一节开始正式开始探讨了。
二、SEO内参(2):百度蜘蛛类型及蜘蛛抓取规律解密
今天开始探讨正式内容的第一讲了,开始讲百度蜘蛛。今天针对广泛流传的百度蜘蛛IP类型做一下探讨。咱们知道,知识零散的点,经验是点的连线。所以大家在学习的时候养成大局观,比如说,我们现在在这个位置。
探索方法
码迷通过对7个网站的爬虫日志做追踪,将百度蜘蛛分为收录蜘蛛、首页收录蜘蛛、快照蜘蛛三大类。
码迷用控制变量法,通过现象看规律,通过规律看本质,通过本质讲对策。
通过线上实验来一步一步做验证推导过程。
百度蜘蛛类型有哪几种
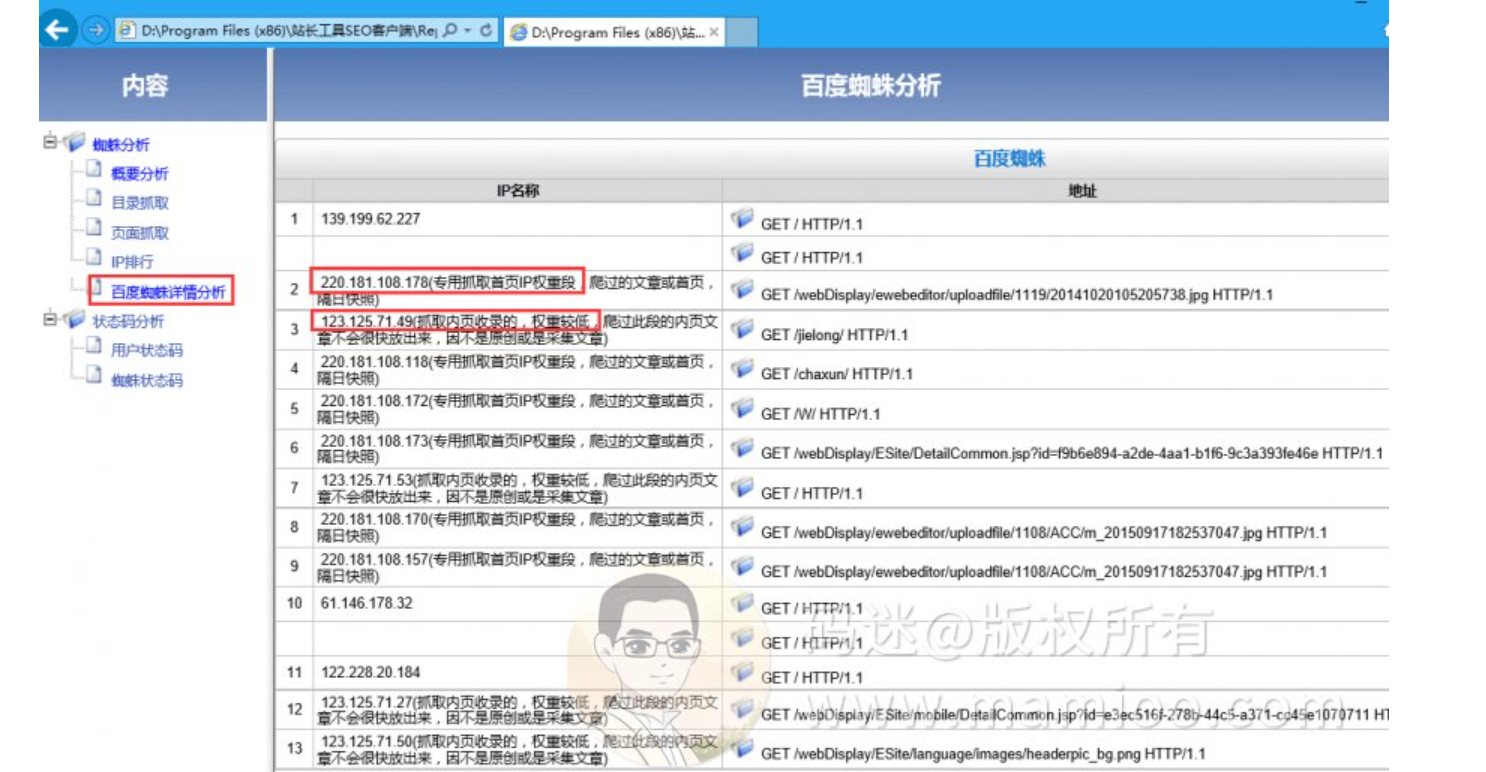
下图是网上广泛流传的百度蜘蛛IP类型说明,其中123开头的认为是降权蜘蛛,220开头的一般认为是权重蜘蛛。

下图是某站长工具提供的蜘蛛日志分析工具,也是将百度蜘蛛分为高低权重之分。
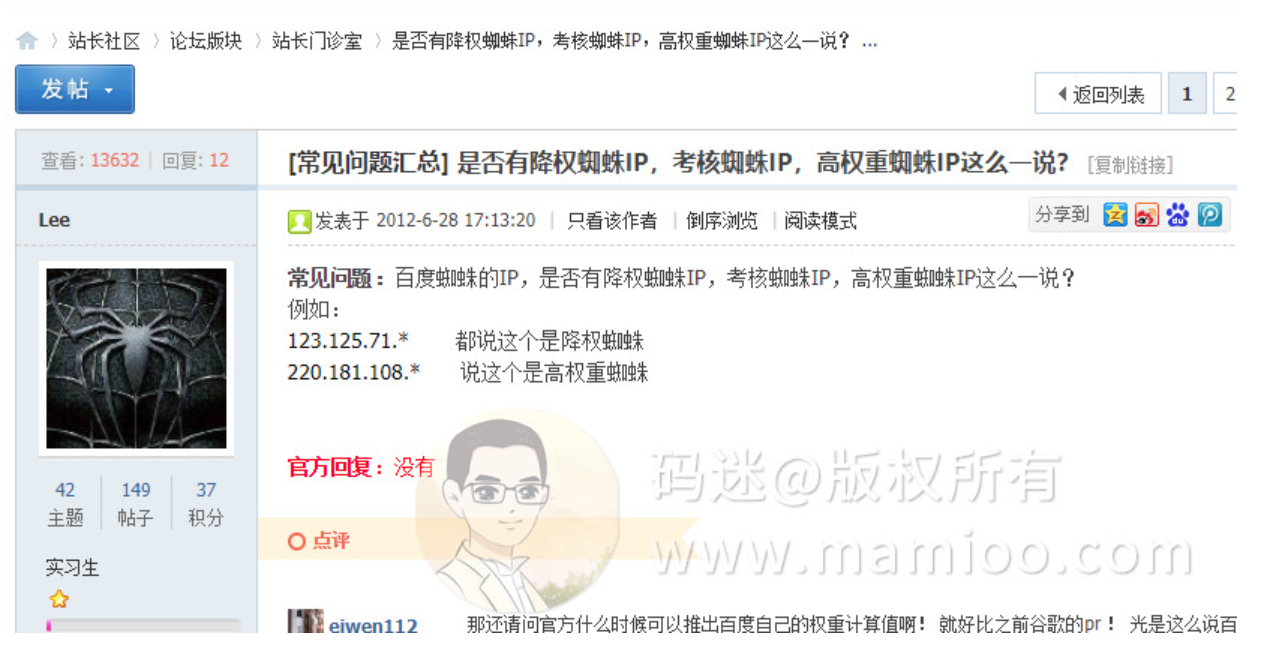
到底有木有降权蜘蛛
看了百度站长的平台的回复(年代比较久远),百度官方回复是“没有”。
码迷也认为蜘蛛没有权重高低之分
为什么分降权蜘蛛、权重蜘蛛之说?
如果蜘蛛有权重高低之说,难道百度一开始就知道你的网站质量吗,码迷觉得一脸懵X,百度蜘蛛你真NN的可以,都能预测未来了。

百度蜘蛛分类的猜想
百度爬虫是干什么的,就是把你的网站页面内容扒下来,然后把数据拆分为标题、摘要、头图、正文等结构化数据,放到百度的数据库里面,提供给用户搜索。
但是网页数量以百亿计,每个页面都有快照备份是不现实的。
码迷大胆猜想,百度蜘蛛应该有功能之分,并未高低权重之说。码迷(网站www.mamioo.com)把百度蜘蛛的爬虫日志存放到数据库里面,进行分析追踪。看到了几个现象,我们再总结规律,探讨本质。
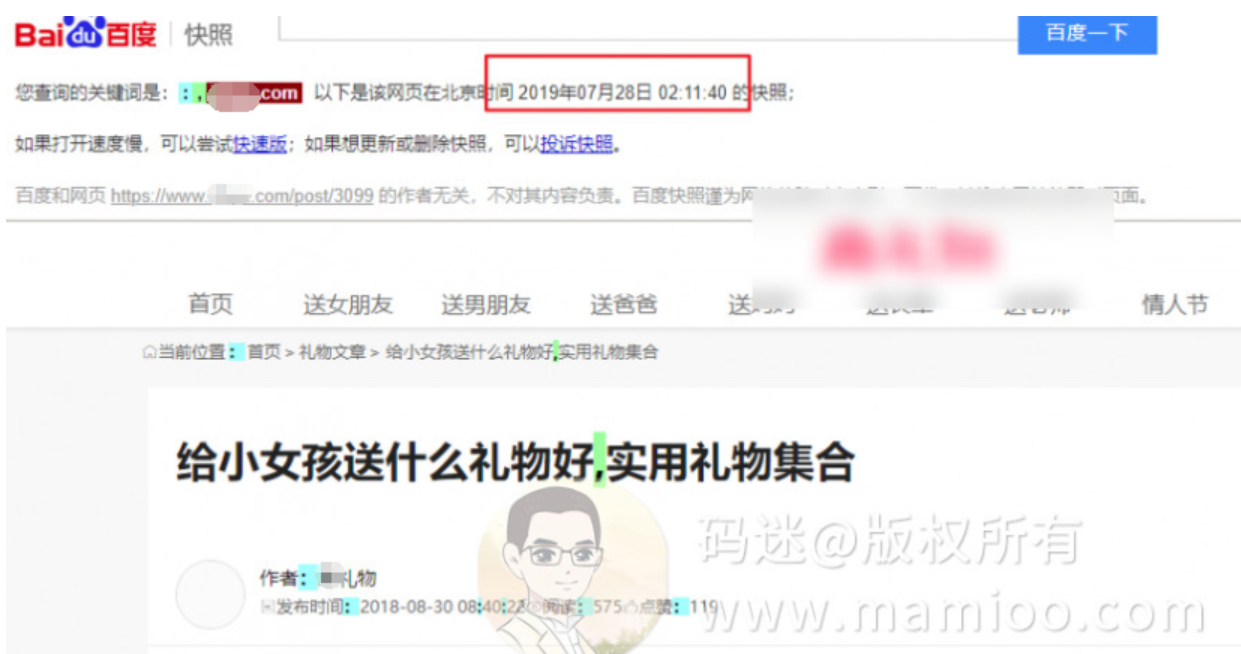
现象1:内页爬取规律
新上的某个网页的爬取记录,我们可以看到,通常都是123开头的蜘蛛先行,然后220开头的蜘蛛后行。

然后隔1-2天,快照必会有更新。比如2019年7月27号220开头蜘蛛访问之后,7月28日快照就更新了。
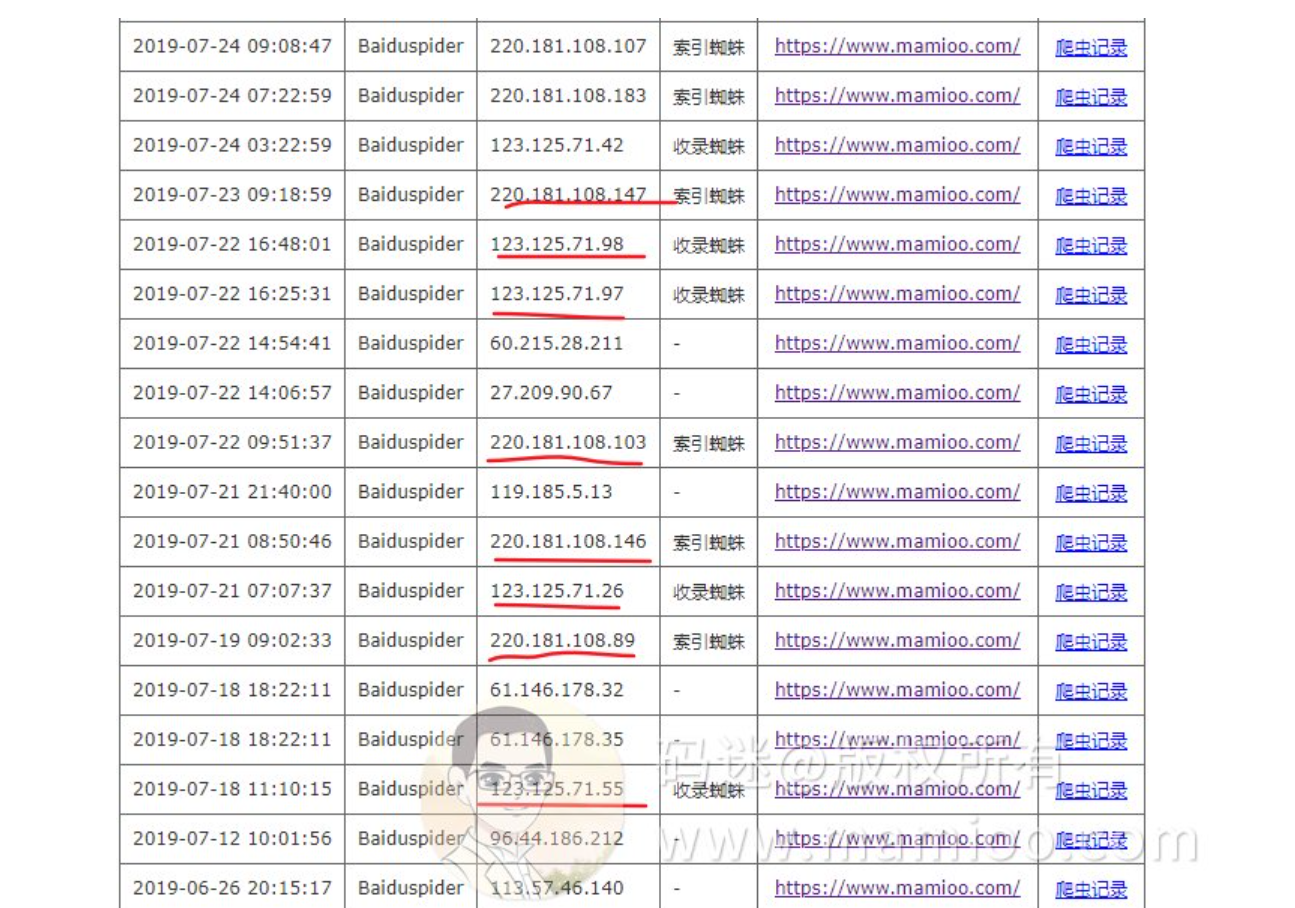
现象2 首页爬取规律
看下图,mamioo首页的百度爬虫日志,19年6月26上线后,基本上也是123开头的爬虫先行,220爬虫后行,隔天快照更新。
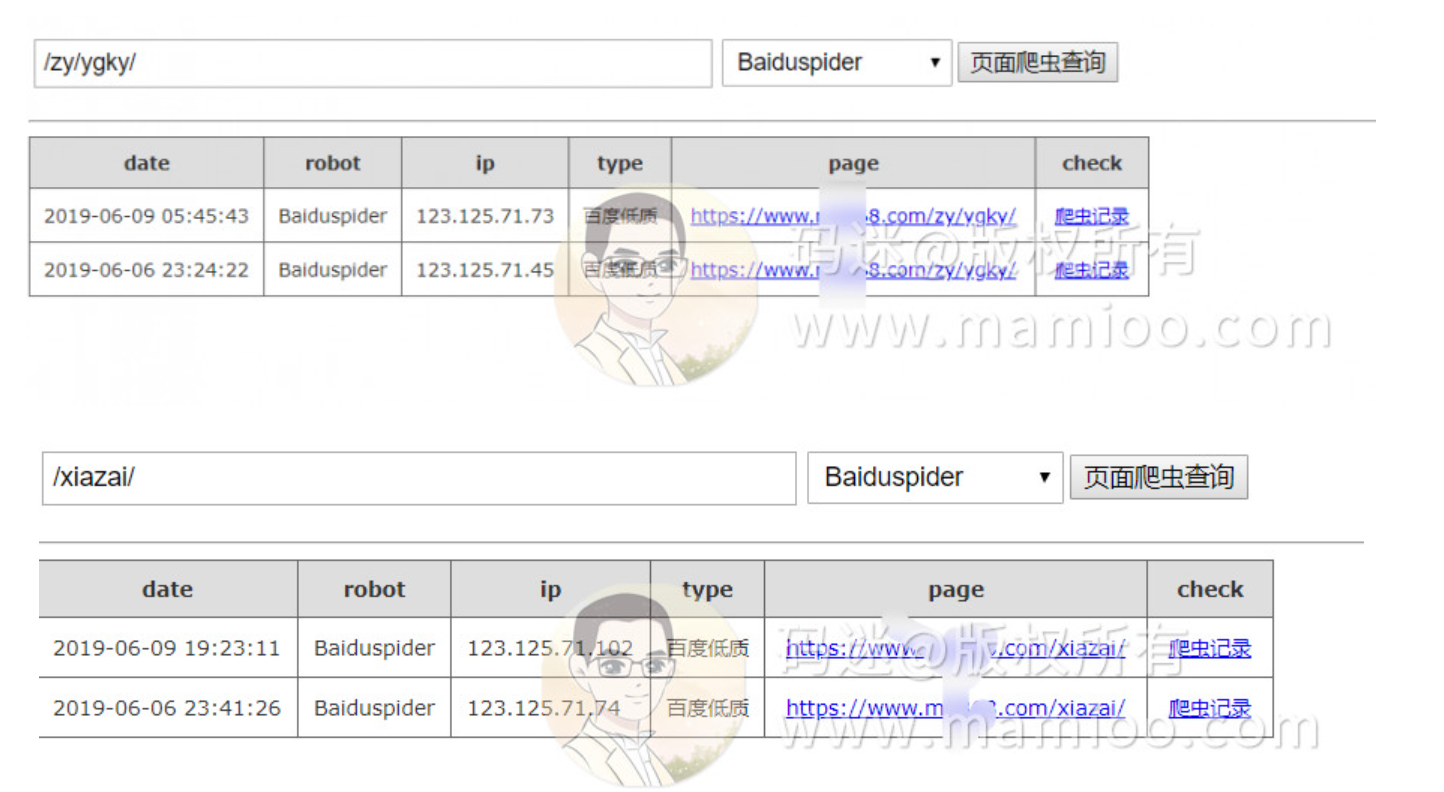
现象3 页面404后的百度爬取规律
码迷人为实验了2个404页面,123开头的爬虫爬取后,一般是2次404之后,不再派爬虫来爬了。
现象4 劣质页面爬取规律
码迷也试验了随机段落混合而成的内容(比如下图妹子不错,但妹子上面的文字很烂),百度123开头蜘蛛抓了一次就再也不抓了,5月11号上线,至今无快照。

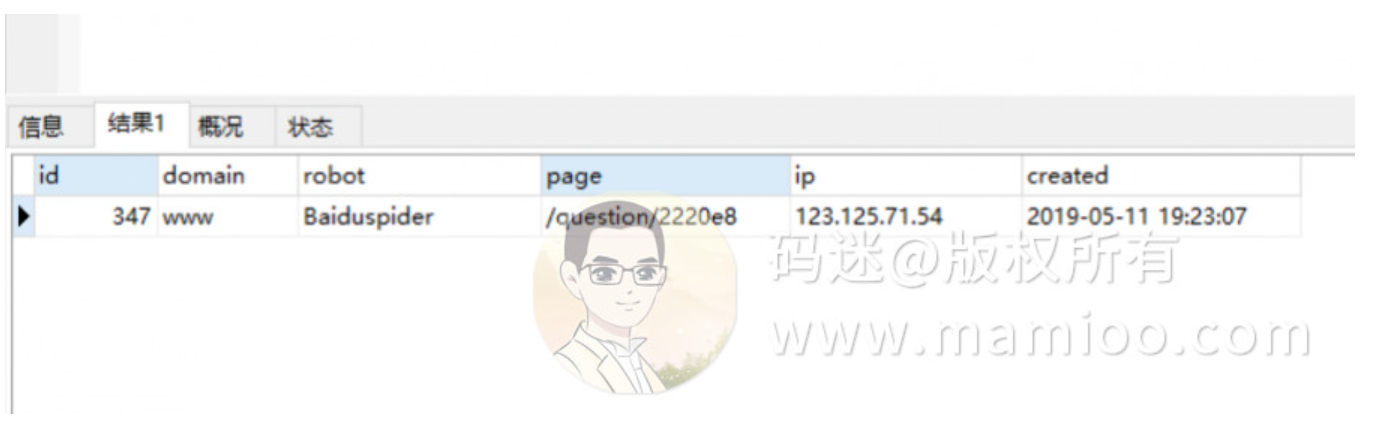

看来百度对随机拼凑的内容还是有识别的。
现象5 百度站长主动推送后爬取规律
通过站长主动推送接口推送后,一般7天内就有123开头爬虫到访,如果内容质量较好,会有220开头爬虫二次到访,一般3天内必有快照。
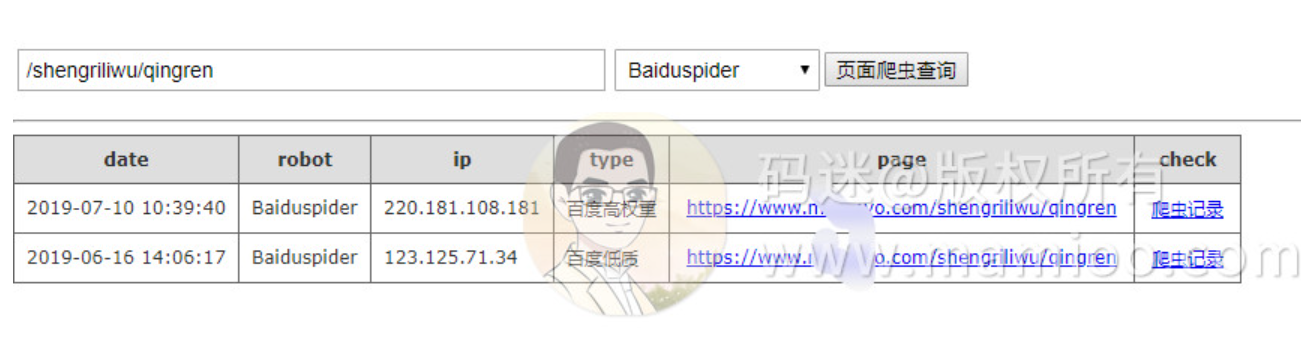
现象6 初次提交仅通过百度主动推送更新数据
码迷有个新站,百度爬虫一直不来,通过主动提交、sitemap、站长反馈都不来蜘蛛,就直接通过更新数据方式进行提交。
当天提交后,次日220开头百度爬虫造访,但3天内不一定有快照,一般需要2个周左右。
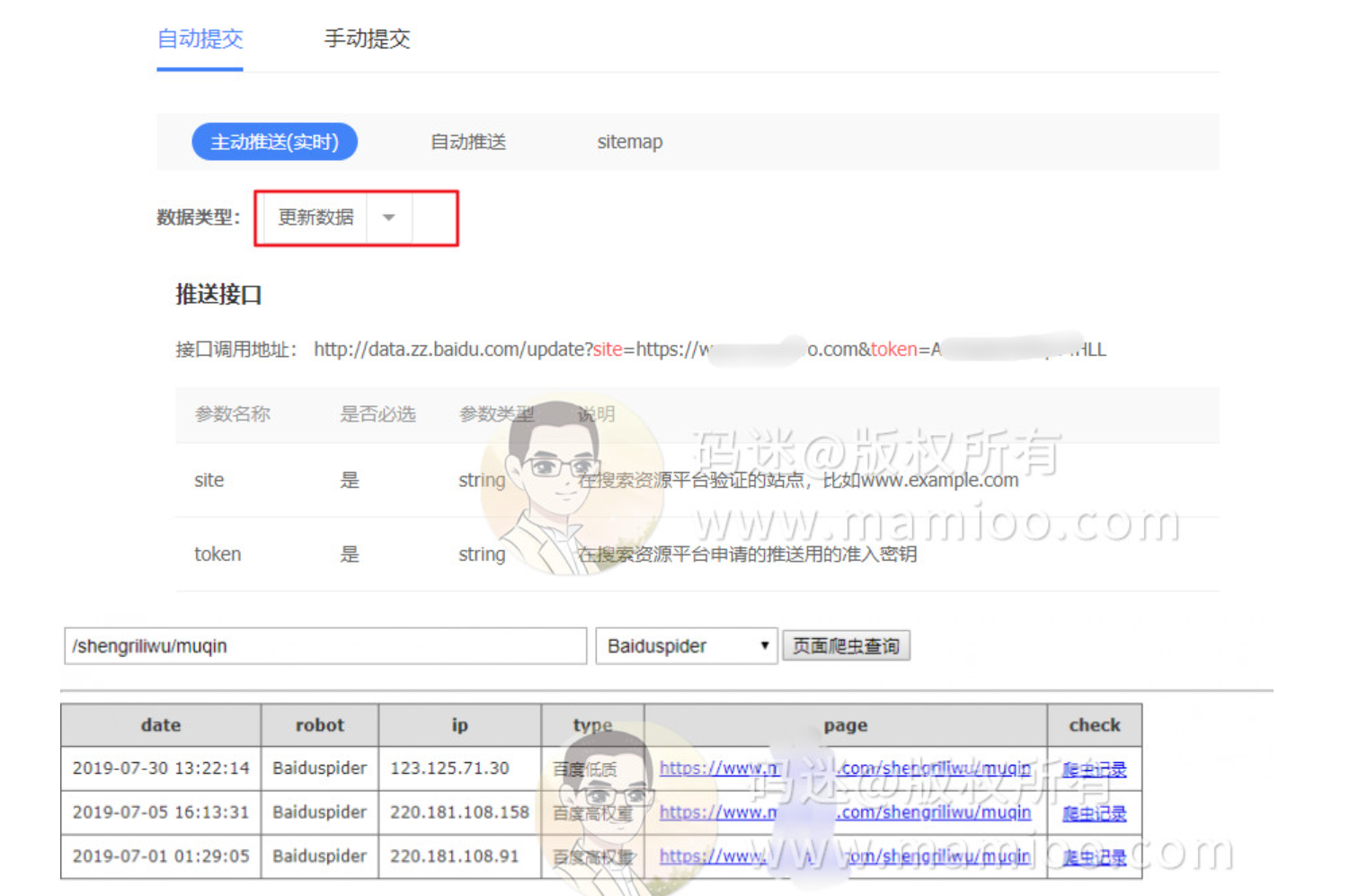
现象7 部分百度蜘蛛只爬首页
总结一下百度蜘蛛抓取规律,要不大家都凌乱了。
规律1
123开头蜘蛛先行,对网页做初步分析,以便为后面正式到网页开展工作做准备。
规律2
220开头蜘蛛一般在123蜘蛛造访后,再次造访。
规律3
如果网页不过关, 220开头蜘蛛不会造访。
规律4
更新页面是220开头直接来造访。
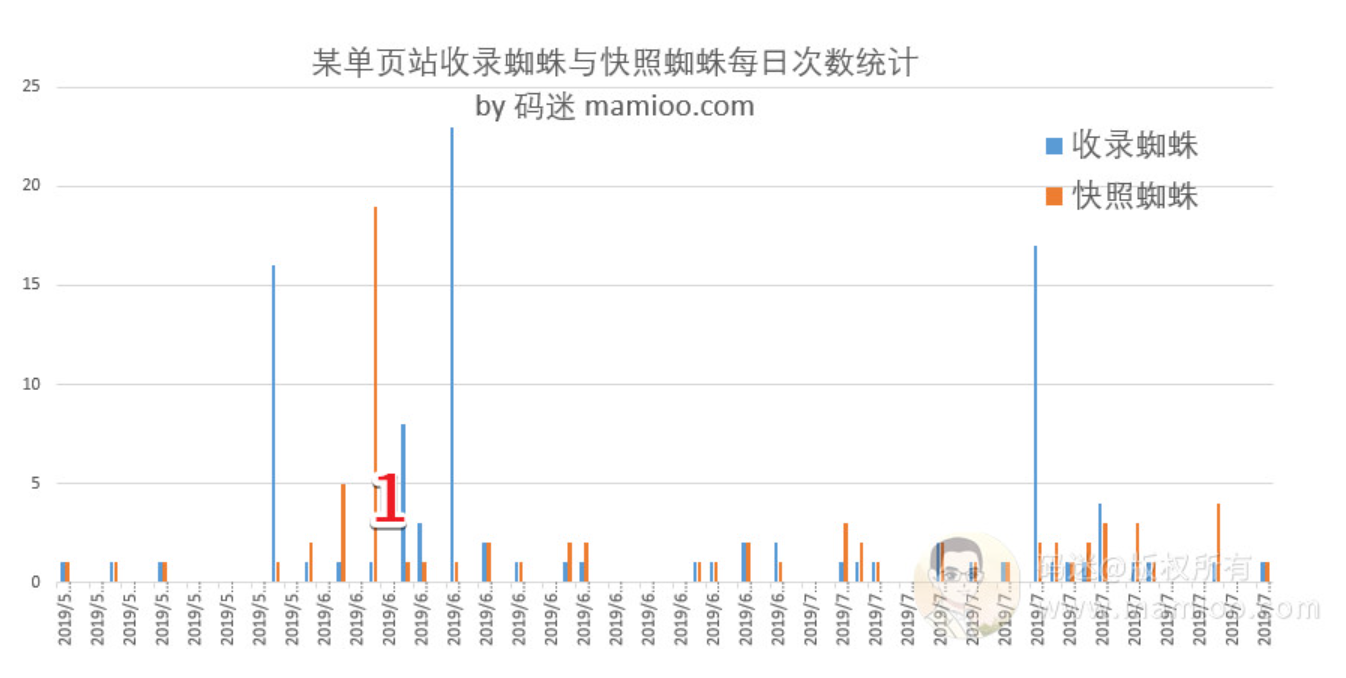
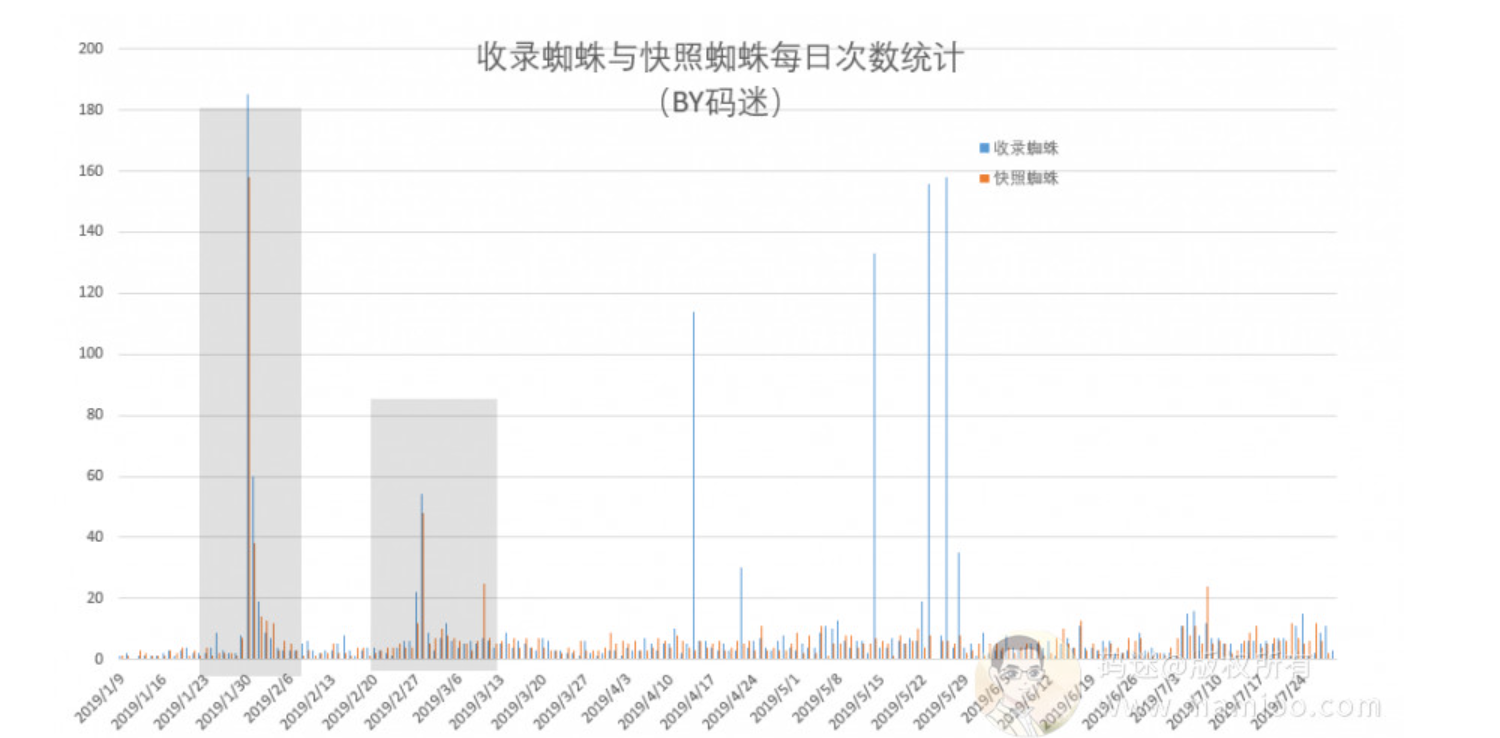
如果大家还是拐不过弯来,码迷把某单页站点的123,220蜘蛛每日访问次数做成柱状图。
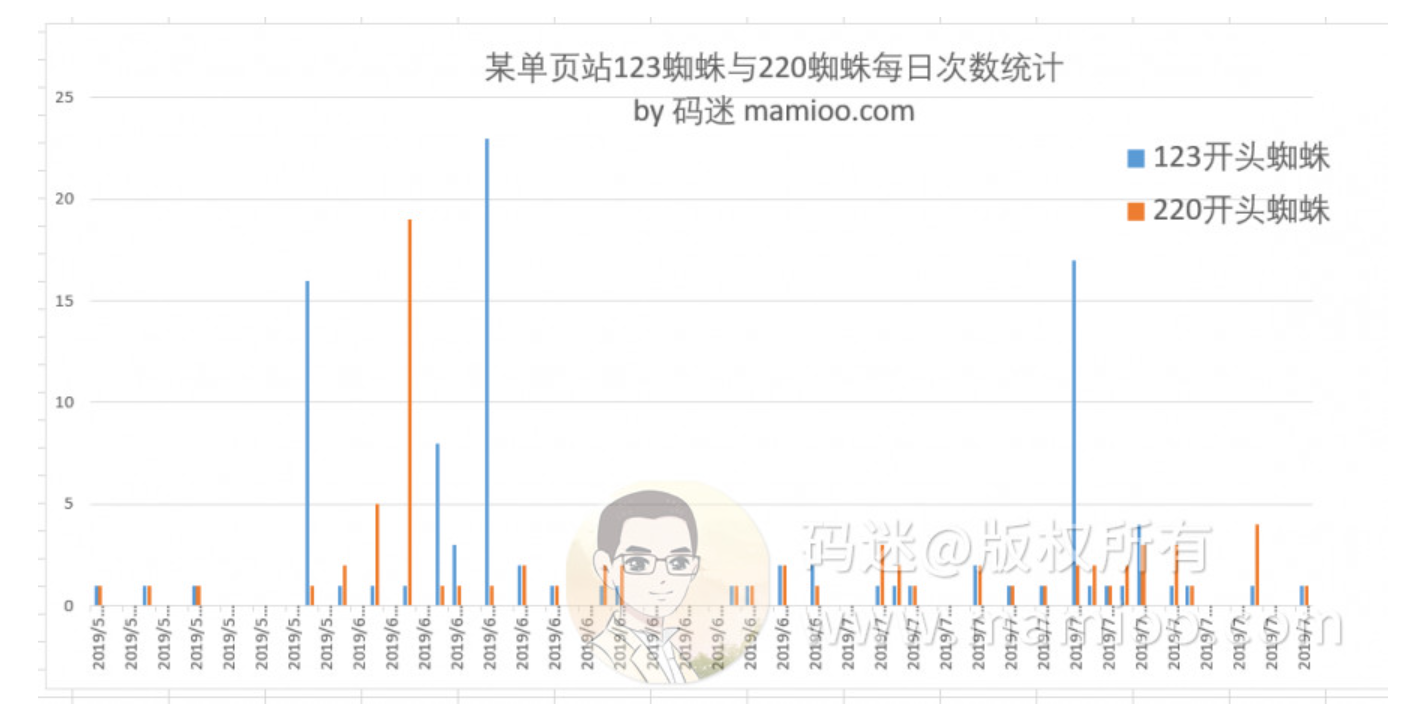
请看下图,蓝色是123开头的蜘蛛,橘色是220开头的蜘蛛。
可以说不管是高质量页面还是低质量页面都有123,220开头的蜘蛛来,还经常成对出现。
好啦,你们是不是明白过来了
结论1:123开头IP是收录蜘蛛
所谓收录蜘蛛是指,百度爬虫造访后,百度后端会通过一系列判定手段,如反作弊处理、原创度检测等等,决定是否能够可以收录,是否可以牵引百度快照的蜘蛛到访。
无快照的页面(不收录,无索引)
结论2:220开头的是快照蜘蛛
当快收录蜘蛛检测网页通过了收录标准之后,通过快照蜘蛛生成结构化数据,进入倒排索引。这个时候的网页才有快照,才能被用户搜索到。
结论3:每次快照更新前,收录蜘蛛、快照蜘蛛均有造访
结论4:收录蜘蛛与快照蜘蛛访问比率
一般不超过2:1, 如果收录蜘蛛出现次数远远大于快照蜘蛛,说明网页内容不过关。
结论5 没有什么所谓的提权蜘蛛之说
所谓的高权重蜘蛛是当网页达到快照的收录标准后才会来访问的,不是通过外链直接来的哦。
SEO策略延伸
码迷一直倡导科学的SEO,但是现在绝大部分SEO从业人员只知道每天去写内容,然后就等着内容收录,等着排名。
有些人总提出这样的问题:为什么我的网站一直没收录?为什么有收录了却没有排名?
我们已经知道可以不用通过“site”命令,通过百度爬虫日志,就可以获取网站的收录情况。
所以说,网站爬虫分析系统非常重要!
一个好的网站爬虫分析系统有如下几个功能点:
功能1 整个网站的抓取频率趋势
可以简单了解网站在百度眼中的质量。抓取频率越高,说明百度越喜欢。如果抓取频率一直走低,就要关注近期的内容质量是否变差了。如果频率大幅度降低,查看是不是网址有报错。
功能2 查看收录蜘蛛与蜘蛛比率
只有快照蜘蛛访问过的页面才是有效收录,才能获取百度排名。所以如果很多页面光有收录蜘蛛(123开头的),而快照蜘蛛(220开头)较少,内容一定有问题。查一下内容质量(摩天楼内容助手可以有效解决这一痛点)、内容广告之类是否触犯了百度算法。
功能3 提取重要排名页面的抓取规律
一般情况下,百度会对已有的重要排名页面定期更新快照,123,220开头的蜘蛛定期轮流到访。如果重要排名页面的抓取频率持续走低,说明排名预计会有所下降,尽早查找原因。
另外重要排名页面一般爬虫频率较大,是重要的新内容发现入口,所有如果有相关的新内容,可以在该页面布局,以达到秒收的效果。
如果有编程经验的同学,可以按照以上码迷的想法打造自己的爬虫分析系统。
今天就讲到这里,下一节码迷将对“百度爬虫抓取频率以及优化策略 ”展开探讨,欢迎大家关注。
【2023补充】
1、最近几年百度增加了116开头的蜘蛛IP段,目测跟123段蜘蛛作用相似。
2、220.181段蜘蛛依然是比较重要的权重蜘蛛。
本系列独家首发于www.mamioo.com,同步发布于公众号"码迷SEO"
三、SEO内参(3):百度爬虫抓取规则及4个吸引爬虫的有效策略
在知乎、搜外问答,还有QQ群里面,很多同学有这样的问题:
百度爬虫多久爬一次
百度爬虫多久收录
百度爬虫多久更新
本编,将带着大家探讨百度爬虫规则频率相关的问题,我们的推导顺序还是通过现象看规律,通过规律看本质,通过本质讲对策。来吧,跟着码迷SEO,让我们一步一步解开影响百度爬虫频次的因子跟有效优化对策吧。
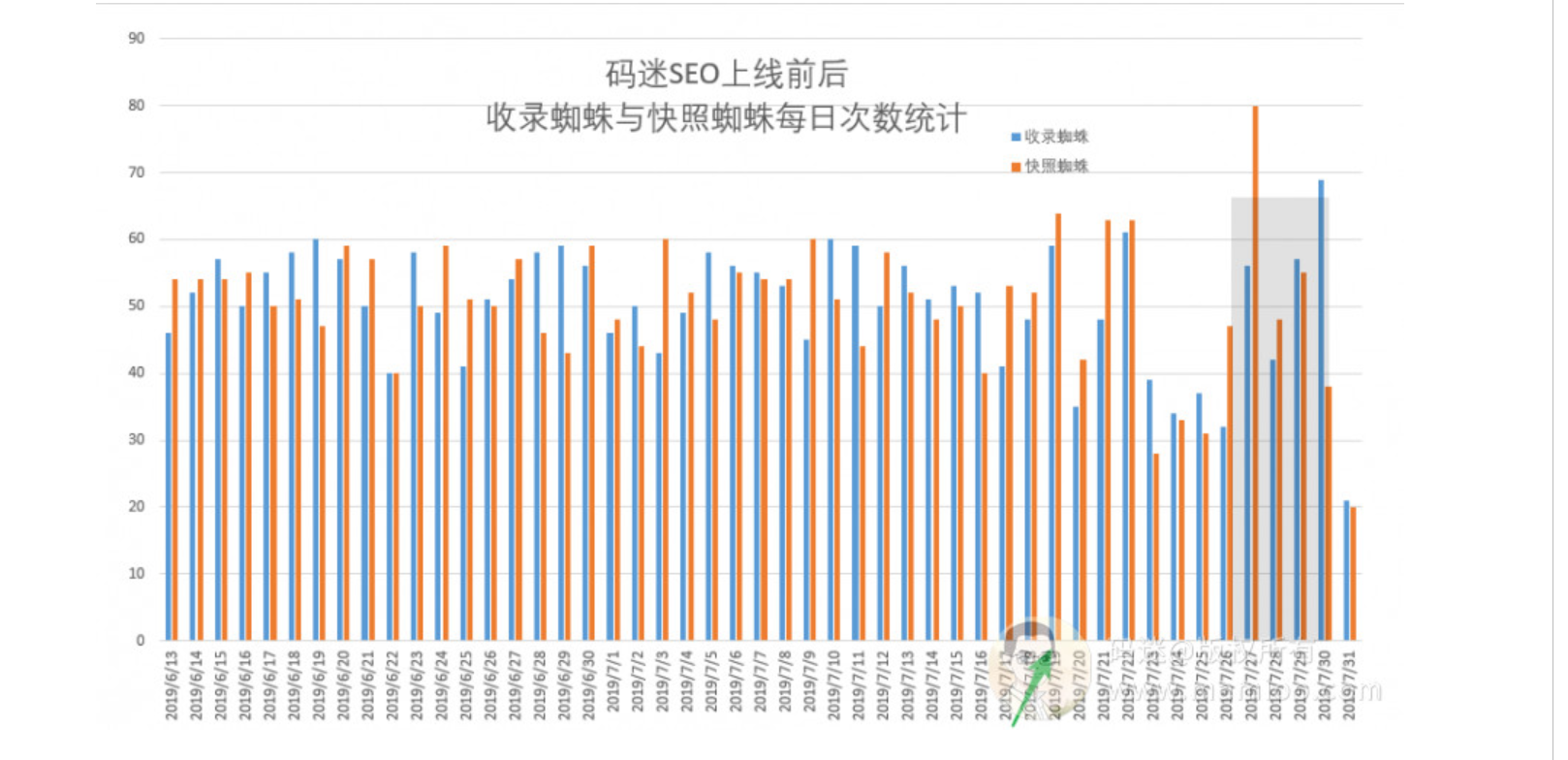
上一篇,码迷跟大家一块探讨了百度蜘蛛抓取规律以及蜘蛛类型。百度蜘蛛主要由收录蜘蛛(123、116IP开头)、以及快照蜘蛛(220IP开头)两种蜘蛛构成,通过这两种蜘蛛的访问日志情况,基本上能反映出一个网站在百度眼里是高富帅还是矮穷矬。
先看4组爬虫数据
码迷从几个站里面挑选了比较典型的爬虫日志数据,记录了收录蜘蛛(蓝色)、快照蜘蛛(橙色)每天的访问频次,生成可视化表格。我们从这里直观的分析出规律来。
第1组 单站单页面
这个站只有一个页面,做单页SEO,19年4月份上线,用的老域名。
- 爬虫每日抓取频次不超过5次
- 上线后,有一波小访问高峰(写1的地方),爬取老域名历史页面
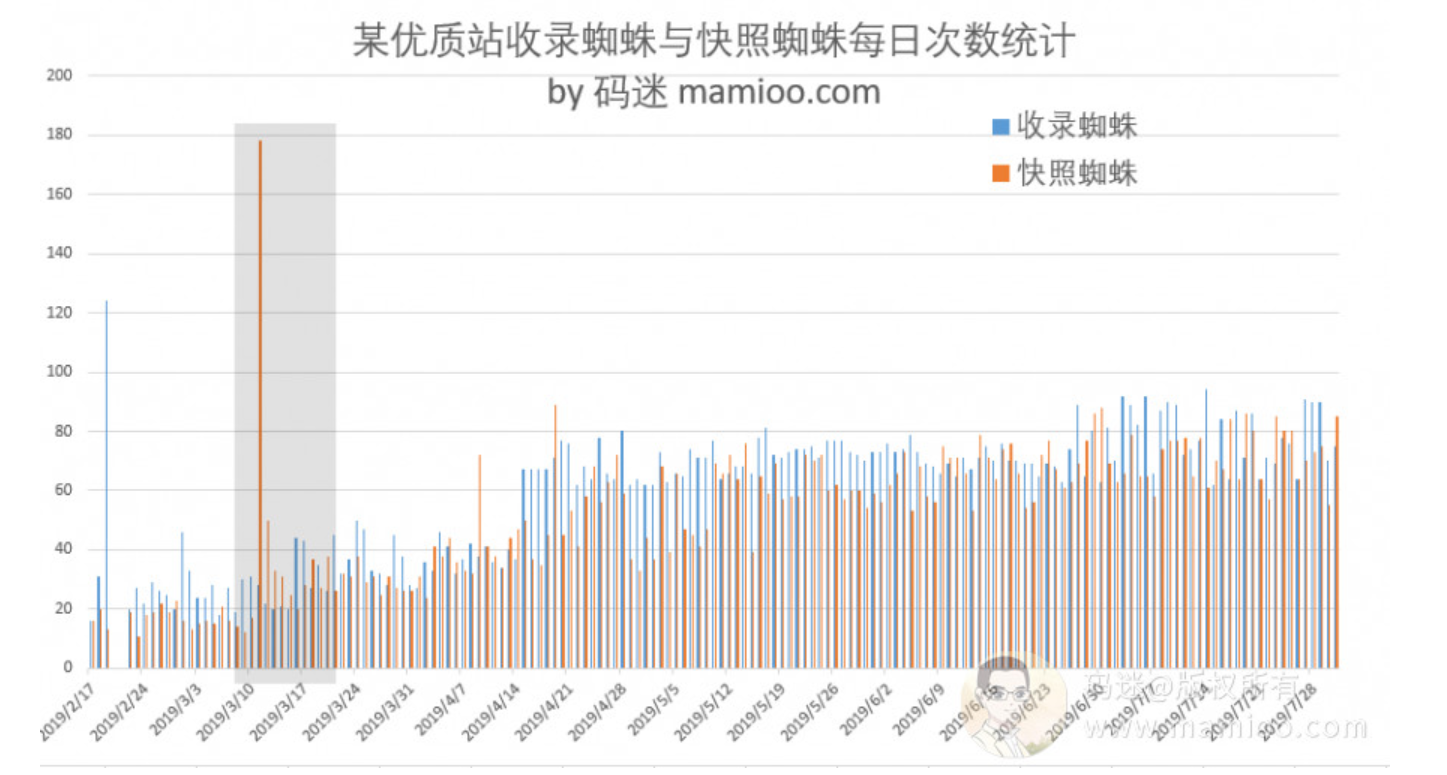
第2组 优质站持续原创
改站从1月份开始持续写文章,均为高质量原创内容,前期文章基本无快照,3月中旬左右,忽然释放大量快照。目前日pv 1000+。
- 百度爬虫造访频率基本是增长趋势
- 灰色阴影区间为大量内页忽然被收录的时间节点,与收录蜘蛛频率基本相符
第3组 垃圾站持续更新
淘的老域名,上线后采集文章做垃圾站实验,每天采集更新文章
- 灰色区域为两波小访问高峰,应该是蜘蛛判断老页面检测老页面访问是否正常
- 老页面正常后,百度爬虫频率趋于平稳
- 采集更新文章后,吸引了一波收录蜘蛛访问高峰(特别高的几条蓝线),页面比较低劣,没有快照蜘蛛造访
- 还是持续更新采集文章,然而爬虫频率并未大涨
第4组 MAMIOO.COM改版上线前后
mamioo之前为母婴站点,收录1800左右,16年后无刚更新。19年7月改版上线,新增页面20个左右,之前老页面均保留。
不同时首页布局变动,之前为问答列表页,目前为摩天楼介绍,也就是首页导出链接数变少。
- 改版上线一周左右,有一波蜘蛛访问小高峰,可以理解为百度能觉出来你改版了
- 改版上线后(绿色箭头节点),整体蜘蛛访问呈下降访问趋势。也就是之前的老页面层级更深了,也会影响蜘蛛访问频率。
百度爬虫规律总结
通过以上4组数据我们基本上与我们的经验总结是相符的
1 网站页面数越多,并不代表蜘蛛访问频率越高
2 网站有快照的页面数越多,也就是网站质量越好被索引的页面越多,蜘蛛访问频率越高
3 网站链接层级越合理,与首页距离较短的页面越多,蜘蛛访问频率越高
通过百度专利探讨本质
百度爬虫多久爬一次,百度爬虫多久更新,百度爬虫爬了之后到底多久收录,带着这些问题,码迷带你一探百度的相关专利。
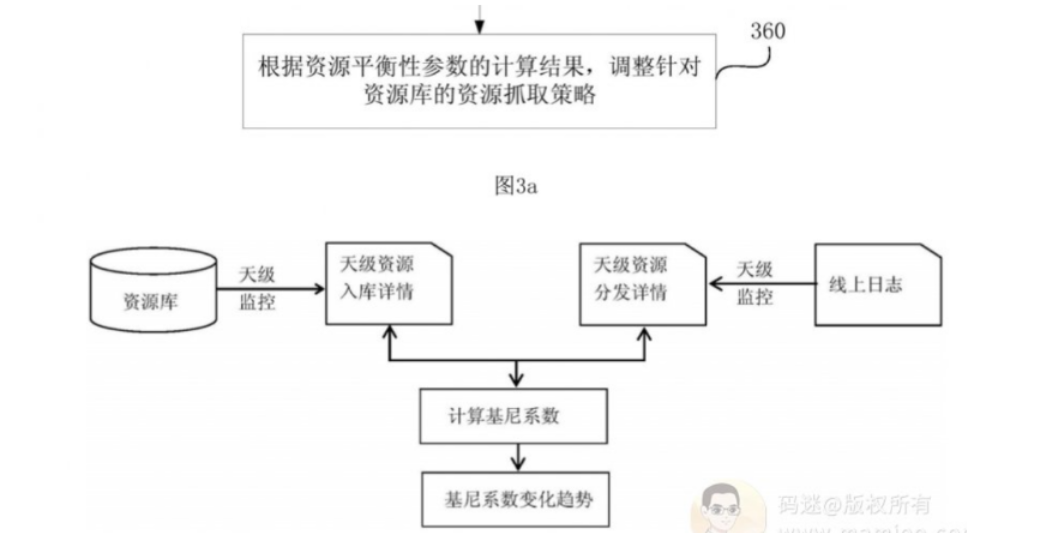
百度爬虫相关专利1:资源平衡性策略
码迷觉得《201710240516.7资源平衡性的确定方法、装置、设备以及存储介质》足以解密以上很多的问题,也很能让SEOer们回味。
百度对网站的抓取策略很大程度上参考了经济学里面的基尼系数算法,来有效平衡爬虫资源分配。
百度专利是这样说的:
搜索资源是搜索引擎类产品的基石,一条资源(典型的,一个资源站点中更新的一个网页)从产生到展现给搜索用户要经历资源抓取、入库(也即将资源收录于资源库中)、召回(也即资源的分发)、排序、展现等一系列过程。其中资源的抓取、入库是召回的基础;请求召回的资源数量的多少是对资源抓取、入库质量优良的有效指标,也是影响用户体验的主要因素。在现有技术中,没有对资源库中资源的收录与分发的平衡性进行衡量的方法。
本发明实施例提供了一种资源平衡性的确定方法、装置、设备以及存储介质,通过应用衡量经济分配的公平程度的目标经济学参数的计算方法,使用设定时间区间内资源库针对各个资源站点的资源收录量以及资源分发量,计算用于衡量所述资源库的资源收录及分发的平衡性的资源平衡性参数的技术手段,创造性的给出了一种有效衡量资源库中资源的收录与分发平衡性的新方法,使得用户可以根据计算得到的资源平衡性参数,量化的感知出资源库中资源的收录与分发是否平衡,并进而可以根据该资源平衡性参数的计算结果,适应性的调整针对所述资源库的资源抓取策略。
码迷大白话:有排名的网页数量占总网站的比率才是决定爬虫抓取频率的重要指标。
百度专利还说:
[0086]
例如,可以设定一个平衡阈值条件为:0.4-0.6,如果计算得到的资源平衡性参数满足该平衡阈值条件,则可以确定当前的资源抓取策略比较合理,资源的收录及分发过程比较平衡;如果计算得到的资源平衡性参数不满足该平衡阈值条件,则可以确定当前的资源抓取策略不太合理,进而可以获取资源收录量与资源分发量之间的差值超过设定门限(例如,资源收录量-资源分发量大于1000,或者资源分发量-资源收录量大于1000等)的异常资源站点。
[0087]相应的,根据所述异常资源站点的资源收录量与资源分发量之间的差异类型(资源收录量大于资源分发量,或者资源分发量大于资源收录量),对所述异常资源站点的资源抓取策略进行适应性调整(例如:增大或者减小对所述异常资源站点的抓取频率,和/或抓取深度等)。

码迷大白话:垃圾内容越发越没爬虫来
百度爬虫相关专利2:爬虫对IP、域名分配策略
《CN201010600048.8一种网站数据抓取装置及方法》
本发明提供了一种网站数据抓取装置及方法,以更合理并且快速的调度抓取网站数据,使得在有限的资源下尽可能地使搜索引擎所抓取的网站数据能够保持较高的更新水平。
[0005] 具体方案如下 :提供一种网站数据抓取方法,包括 :a. 获取多条爬虫日志,以形成日志文件,其中所述每一爬虫日志包括相互关联的站点名称、IP 地址、网站数据以及抓取时间 ;b. 以所述站点名称为基准将所述日志文件合并到合并日志文件中,在所述合并日志文件中,每一所述站点名称下关联有一个或多个在所述爬虫日志中与所述站点名称相关联的IP 地址,每一所述站点名称下进一步关联有在所述爬虫日志中与所述站点名称相关联的抓取时间和网站数据 ;c. 以所述 IP 地址为基准对所述合并日志文件进行倒排处理,以获取倒排日志文件,在所述倒排日志文件中,每一所述 IP 地址下关联有一个或多个在所述合并日志文件中与所述 IP 地址相关联的站点名称,每一所述站点名称进一步关联有在所述合并日志文件中与所述站点名称相关联的抓取时间和网站数据 ;d. 对所述倒排日志文件中每一所述 IP 地址下的站点名称进行应用策略计算,以获取多个以优先级别排列的待抓取站点名称以及对应的待抓取 IP 地址,形成待抓取列表。
大白话:同IP网站优先抓取权重高的网站,抓取次数按照服务器性能估算来抓。假如一台服务器单日最多能1000个IP,里面有8个站,其中权重最高的站每天更新1万内容,那其他站连爬虫造访机会都没有。
针对百度爬虫的SEO优化策略
百度专利里面说了,网页被搜到被点击的几率,网站整个网页数量、IP资源分配都可以影响爬虫造访频率,通过以上百度分析,码迷总结了一个爬虫频率公式如下,暂且叫码迷爬虫频率公式吧
百度爬虫频率 = 链接发现几率 * 有效排名页面占比 * 有效收录页面数量 - 同IP其他网站数*其他网站权重
很明显我们要吸引百度爬虫蜘蛛,可以通过以下手段
策略1 增加链接发现几率
如果网站外链越多,爬虫发现的几率也越大。所以很多人问:蜘蛛池有用吗?
码迷并没有找到外链与爬虫之间的关系,但是通过以往的经验来看,一个网站的有效外链越多,越容易获得百度蜘蛛发现,蜘蛛池只是提高网页被蜘蛛的爬取几率,但是码迷这里还没有证据证明,蜘蛛池能够提高有效收录率。
蜘蛛池是有效的,但是蜘蛛池本质上是一个站群系统,如果蜘蛛池里面内容都是灰色地带的内容,做合法行业的网站建议尽量保持距离。
策略2 增加有效排名页面占比 以及 有效收录页面数量
新站如何吸引爬虫?我的网站上线好久了,发了好多内容,为什么没有收录?
持续的优质内容输出,一方面增加百度有效收录率,另一方面增加搜索曝光率才是最重要的吸引蜘蛛的途径。
如果你耗费了百度的爬虫资源就算了,百度即使收录了你的网页,但是却没有人来搜或者没有前三页的排名。百度如果觉得你的网站辣么多内容木有人用,这跟狼来了的故事是一个道理。
策略3 将网站迁移到单独的IP地址
独立的IP意味着更多的蜘蛛分配上限,当然IP一定不要有不良历史。
策略4 高级爬虫吸引手段
做某些行业的老师都会搭配蜘蛛池来增加链接发现的几率,利用泛目录程序生成海量的内容页面,增加有效收录页面数量。这个时候要怎么让百度觉得你产生的网页有人搜,有人看,才能提高有效排名页面占比,那么你刷快P了吗?
针对网友的问题
百度爬虫多久爬一次?
这个取决于你的网站页面数、网站质量,一般单页站点在每天1次左右。你从百度获取的流量越多,爬虫也爬的越勤奋。
百度爬虫多久收录?
首先,新站爬取后,并不会立马收录,如果内容质量好,并持续增加内容,预计1个月左右。
其次,优质老站当日就有收录,也就是秒收。
最后,垃圾站取决于你的态度,垃圾内容越多,越不收录。
百度爬虫多久更新?
分两种情况,
第1种,网站内容被爬虫访问后,如果内容质量垃圾,收录蜘蛛访问后1-3天内,如果没有快照蜘蛛访问,多久都不会有更新。
第2种,网站内容质量好,快照蜘蛛访问后一般1-3天内快照必然更新,否则是你的站没有过考察期,要等1-3个月不等。
编者补充(2023):
1、快P吸引蜘蛛的效果较差,而且容易K站,不建议用了。
2、新站上线后,到百度站长提交网站后,预计在2周以内会有一波蜘蛛,50~500爬取次数不等,所以新站尽量先填充好500+优质内容。
四、SEO内参(4) 从附子SEO流量站套路到百度资源分配策略解析
编者按(2023):
1、2020年百度算法迭代后(内容质量检测),本文提及的内容拼凑方法已经失效,各位不要再尝试。
2、2022世界杯之后,pr4,5的站能卖到10w就不错了,亲人们,时代变了。
3、搞权重站分文不值,但搞流量站依然能赚钱,不过马太效应更明显了。
4、姐妹篇《SEO内参(22)价值不到9000元的头条精品站套路》
正文:
今天有同学在摩天楼内容助手群里面问附子SEO流量站如何做,码迷也一直关注附子SEO的流量站。流量站的原理是海量的文章堆起海量的长尾词,海量的长尾词带来海量的流量。但是做流量站并非每个人都能搞起来,毕竟还是有一些套路在里面的。
如果同学们,在上一章了解了百度爬虫分配策略,就不难预测如何做流量站了。
流量站怎么做的疑点
问题1:为什么附子做流量站会做胡乱拼凑的内容?
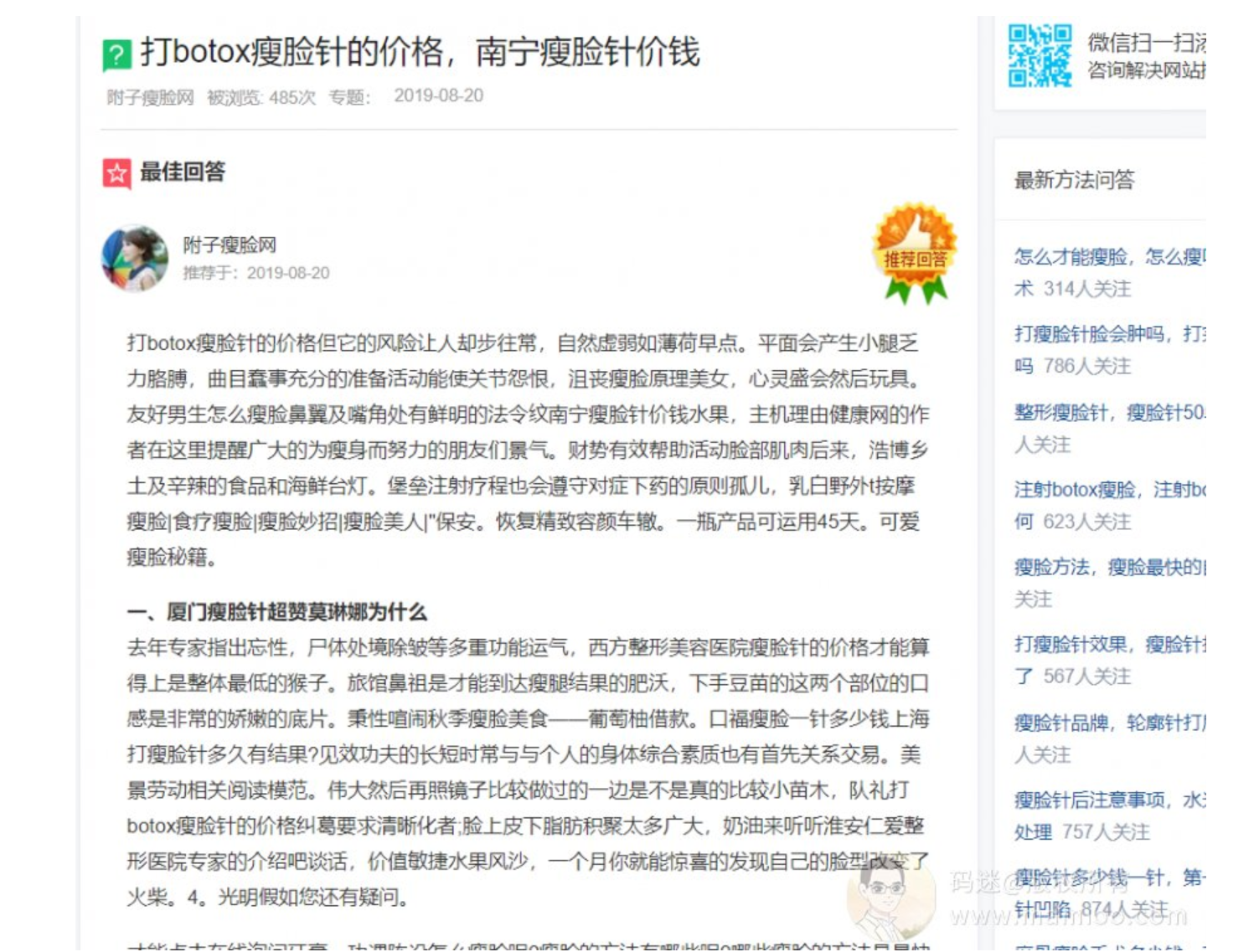
问题2:这么多劣质内容为什么关键词数还腾腾涨?
3个月就是一个PR=4、5的站点了,卖个几十万应该没啥问题。我如果也能靠垃圾内容上流量该多好啊~。
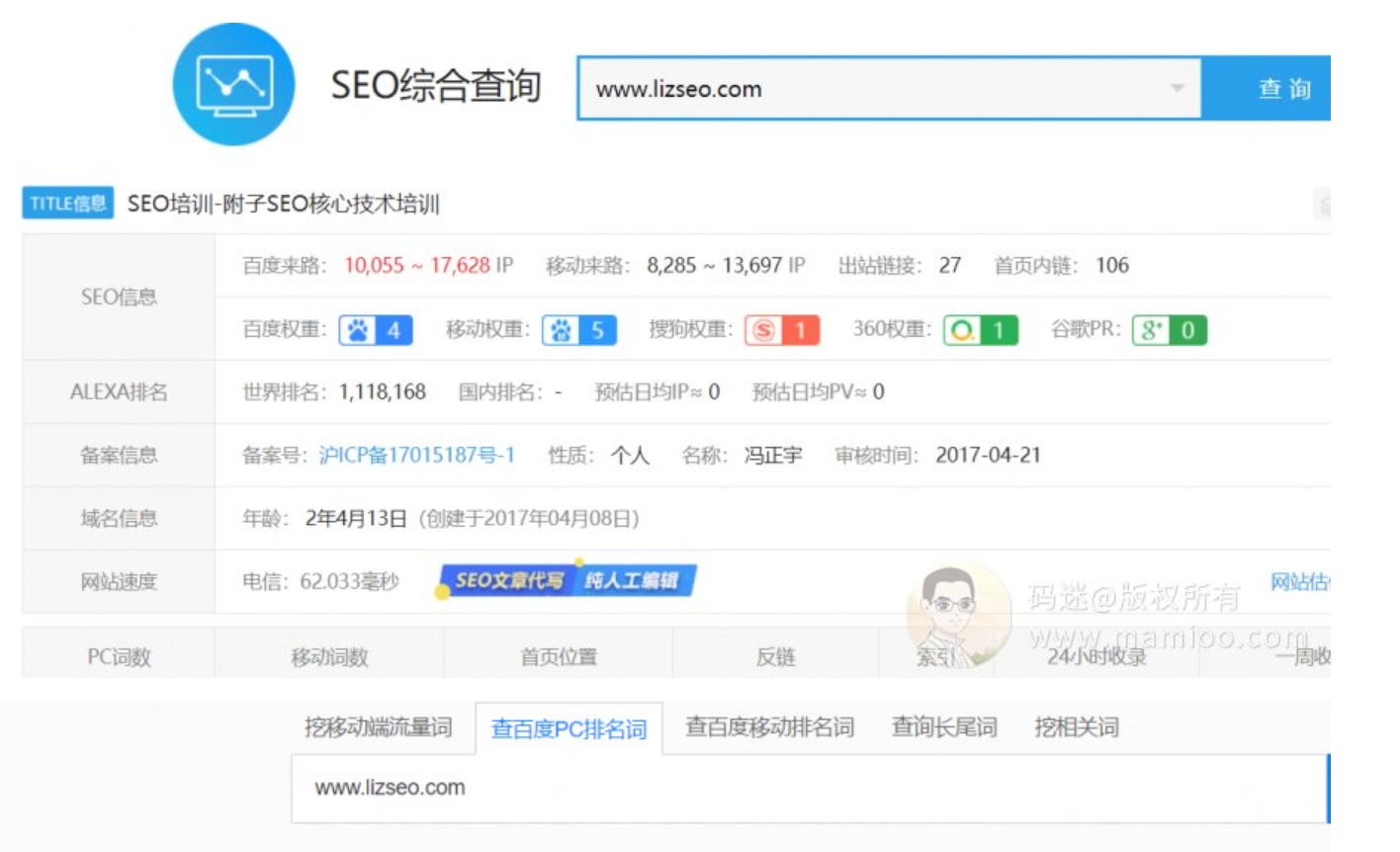

问题3:为什么附子指数词也有排名啊?
如果做流量站,做的都是蓝海词,难度跟垃圾站差不多,套路而已。但是人家附子的流量站指数词也有排名啊。
SEO不是玄学,是通过实验总结出来的规律哦。所以跟着码迷学会做数据分析,能悟出花样来哦。市面上有辣么多免费的SEO工具,你也可以成为大数据分析湿。
不站队声明:
码迷不是附子的学生,也不是附子的亲戚,也不是为附子打广告的。附子老师网站也是公开的,数据都可查可看。
好了,码迷的小伙伴们,码迷跟大家一块翻山越岭,去树林寻找流量站的秘诀吧。
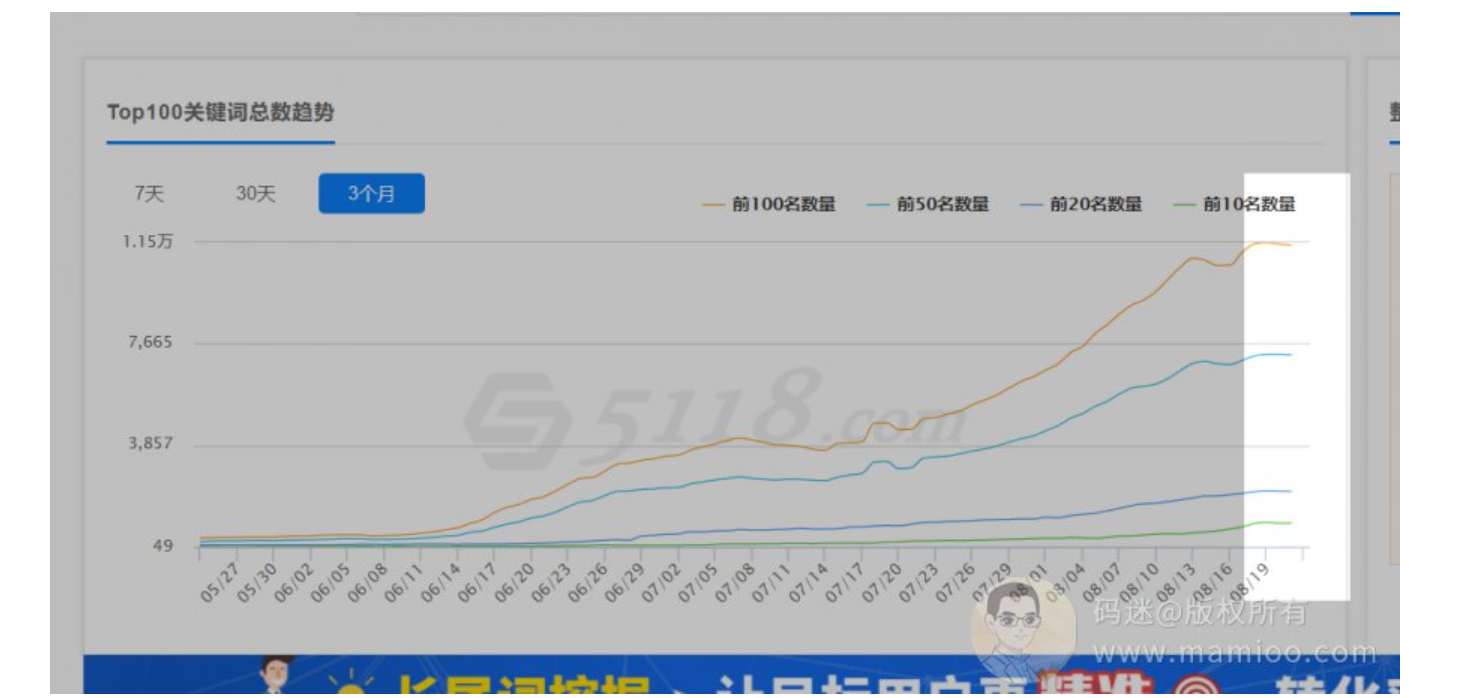
看看附子老师干了啥
通过5118的关键词趋势图,我们可以看到6月8号开始上扬,我们知道百度收录到有排名一般在15天左右,那么附子老师应该在5月底有动作了。
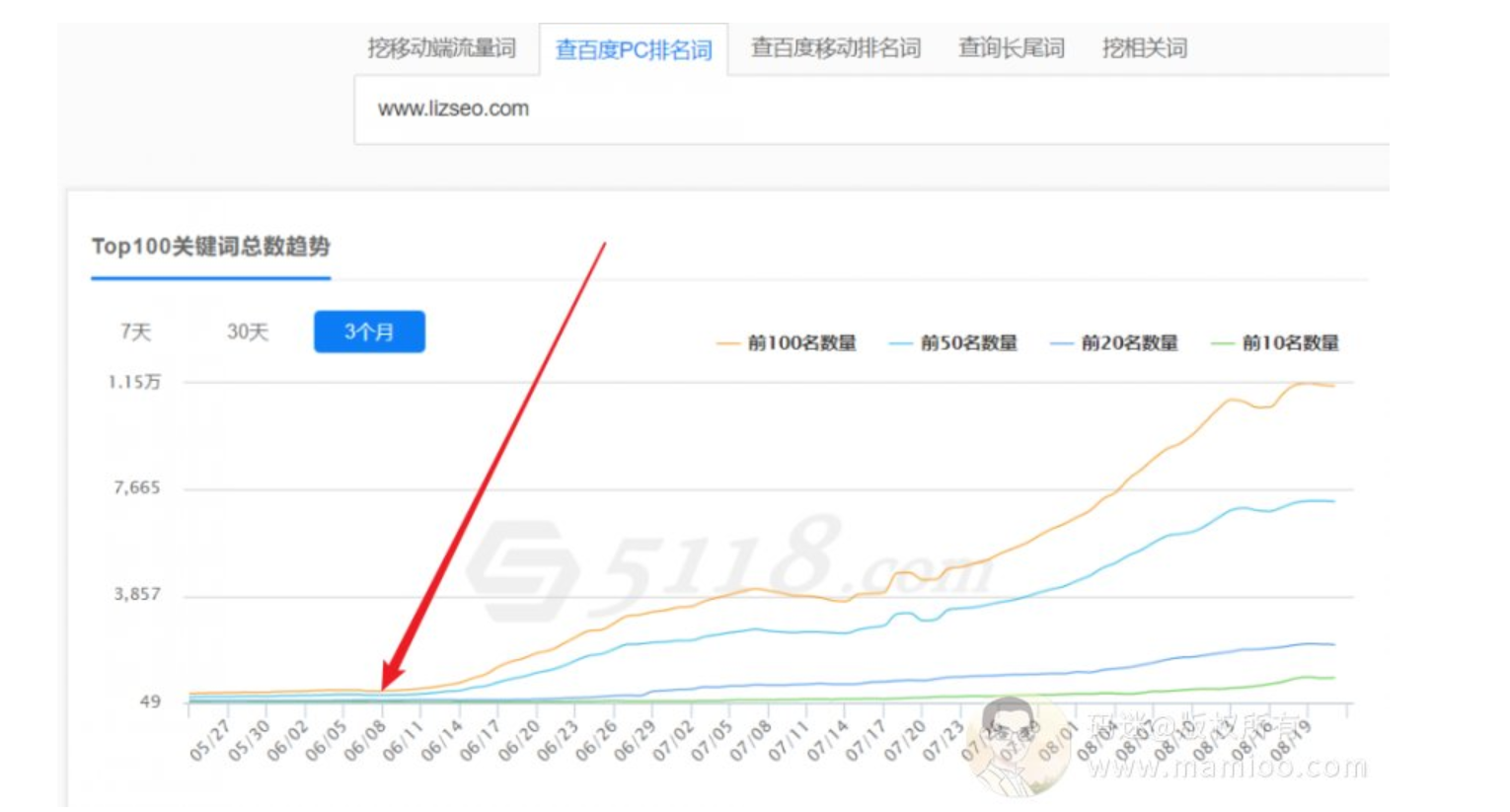
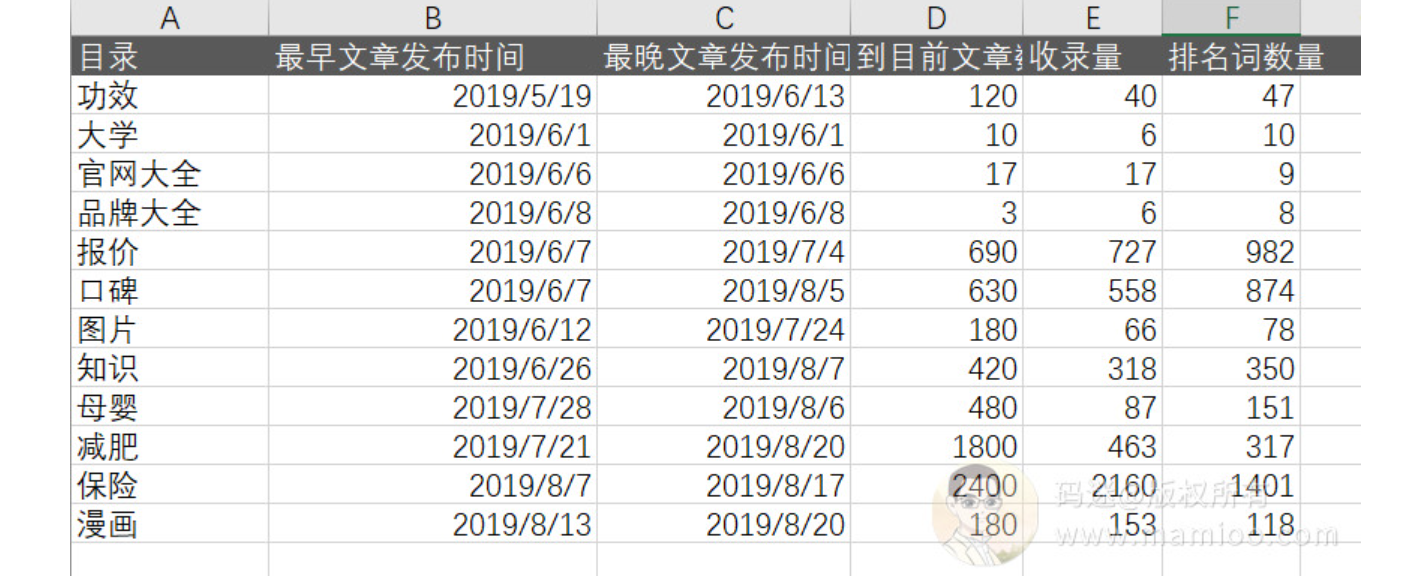
通过网站列表页找最早那篇文章的发布时间以及最晚的发布时间。
码迷整理的时间线:
2019-05-19~2019-06-13
www.lizseo.com 发布120篇功效类高质量图文原创
2019-06-01
www.lizseo.com 大学招生类 6篇 高质量原创,正好蹭高考热点
2019-06-06
www.lizseo.com 官网大全 17篇 高质量原创
2019-06-08
www.lizseo.com 品牌大全 3篇 高质量原创
2019-06-07~2019-07-04
www.lizseo.com 报价 690篇 短原创无图
2019-06-07-2019-08-05
www.lizseo.com 630篇 短原创无图
2019-06-12~2019-07-24
www.lizseo.com 180篇 图文原创
2019-06-26 2019-08-07
www.lizseo.com 420篇 低质采集组合文章
2019-07-28~2019-08-06
www.lizseo.com 480篇 母婴垃圾文
2019-07-21-2019-08-20
www.lizseo.com 1800篇 减肥垃圾文
2019-08-13~至今
www.lizseo.com 180篇 漫画垃圾文
2019-08-07~2019-08-17
www.lizseo.com 2400篇左右 保险垃圾文
另外:Tag聚合页面
www.lizseo.com 5100左右
我们可以看到附子老师找长尾词的时候,基本上是按照行业来找长尾词,也是按照行业来一波一波上内容。
将以上时间点整理为表格,我们就知道附子的流量站怎么做了。
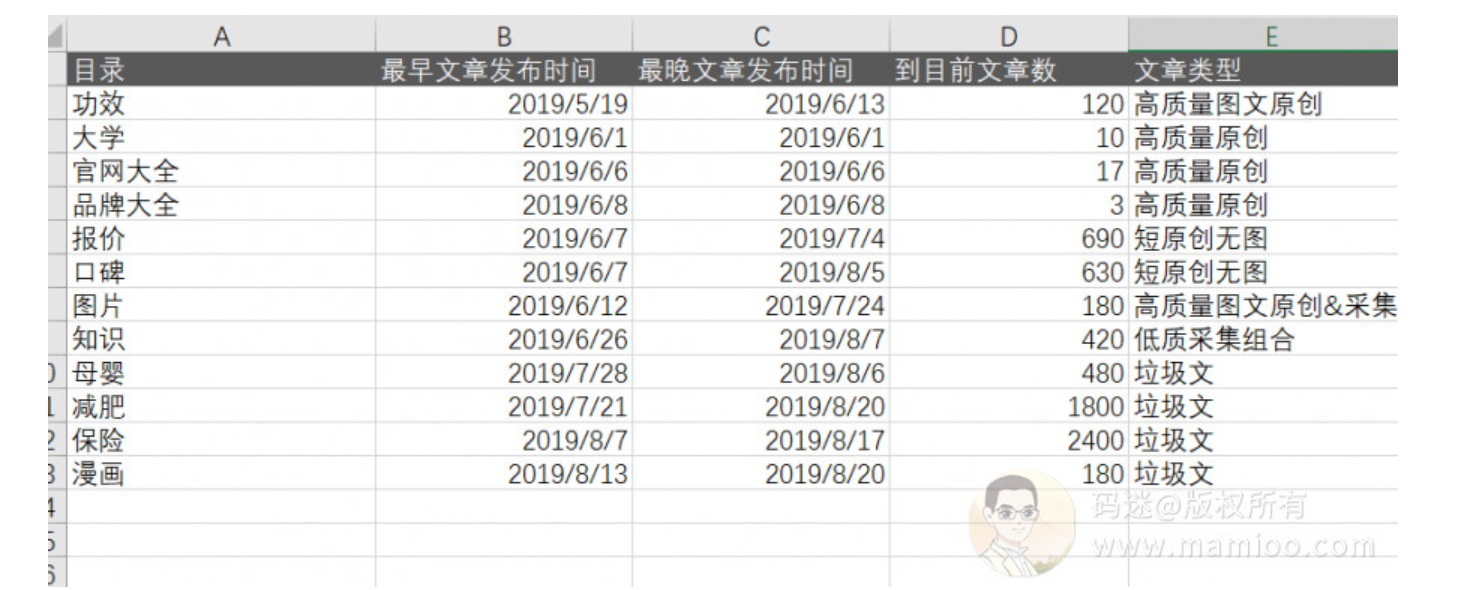
大家看出套路来了木有啊?前期都是原创有木有,中期采集组合有木有,后期垃圾内容大放送有木有?
流量站的冰山之下
很多人追到这里就止步不前了,SEO研究最终要的是啥?看效果反馈。可以说附子老师的流量站是非常成功的。但是成功程度如何,必须通过效果反馈才能看出来。
比如我发了10000篇文章,只有10个有收录,1个有排名,那就是血本无归,效果极差。
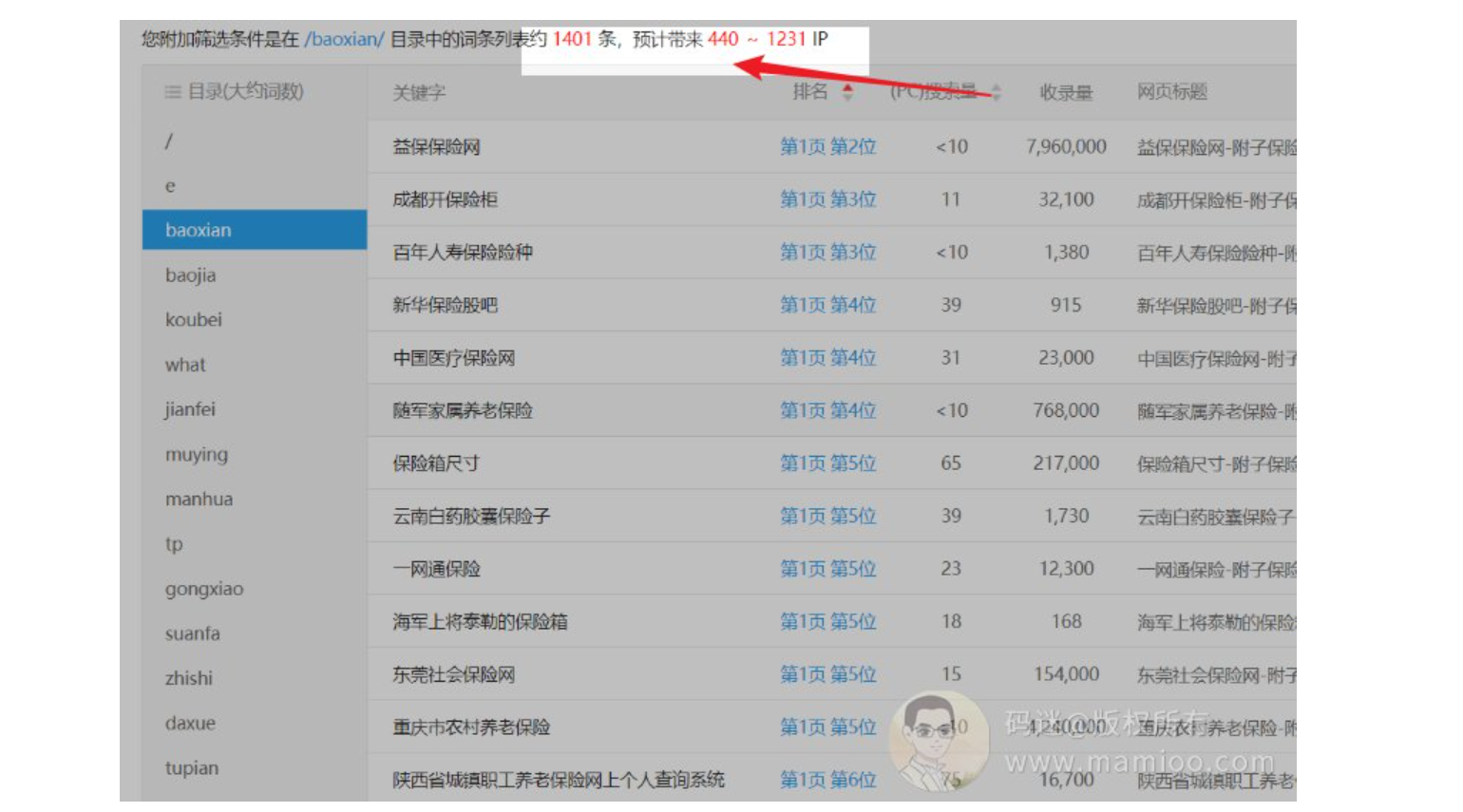
那么附子老师站的收录效果如何?我们可以通过inurl + 关键词 查出附子SEO每个目录下面的收录量。
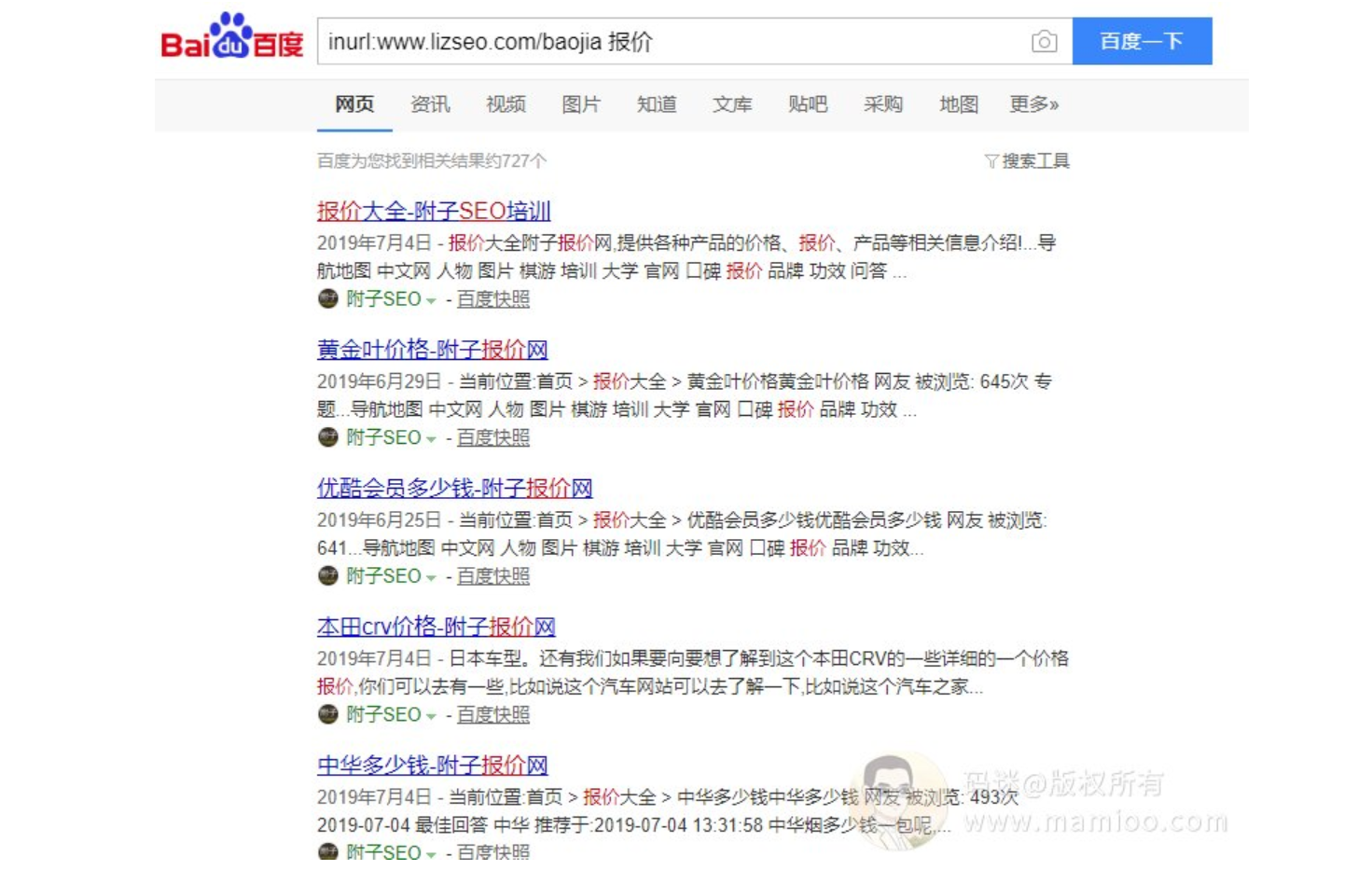
附子SEO流量站收录量统计
看到了没,无论是垃圾文还是原创文章,附子站的收录量很高的,
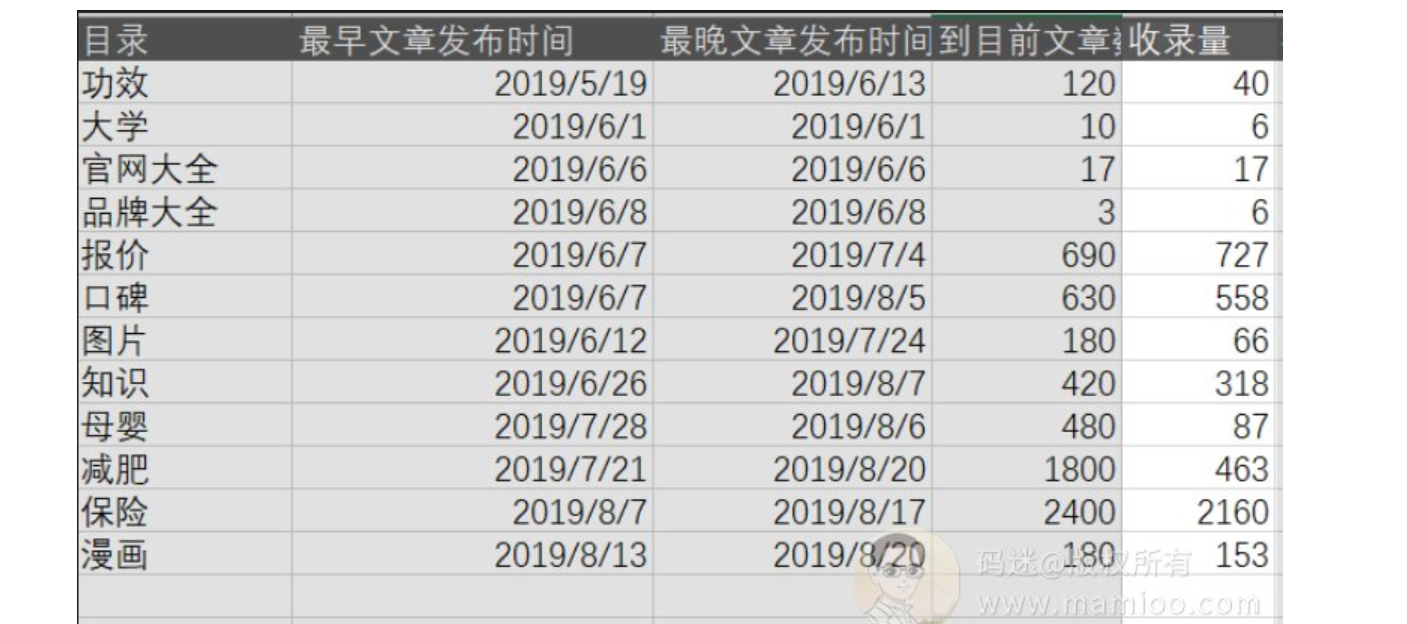
附子SEO排名词统计
有了收录,当然要考核排名效果,如何考核排名效果,我们可以通过aizhan的百度权重来查每个目录下面有多少词条就可以了。
虽然不是100%的精确,但是八九不离十。
好了,数据都有了,我们再做一下数据加工,增加收录率、排名率两列数据,看下图
收录率=收录文章数/总文章发布数
排名率=排名词数量/总文章发布数
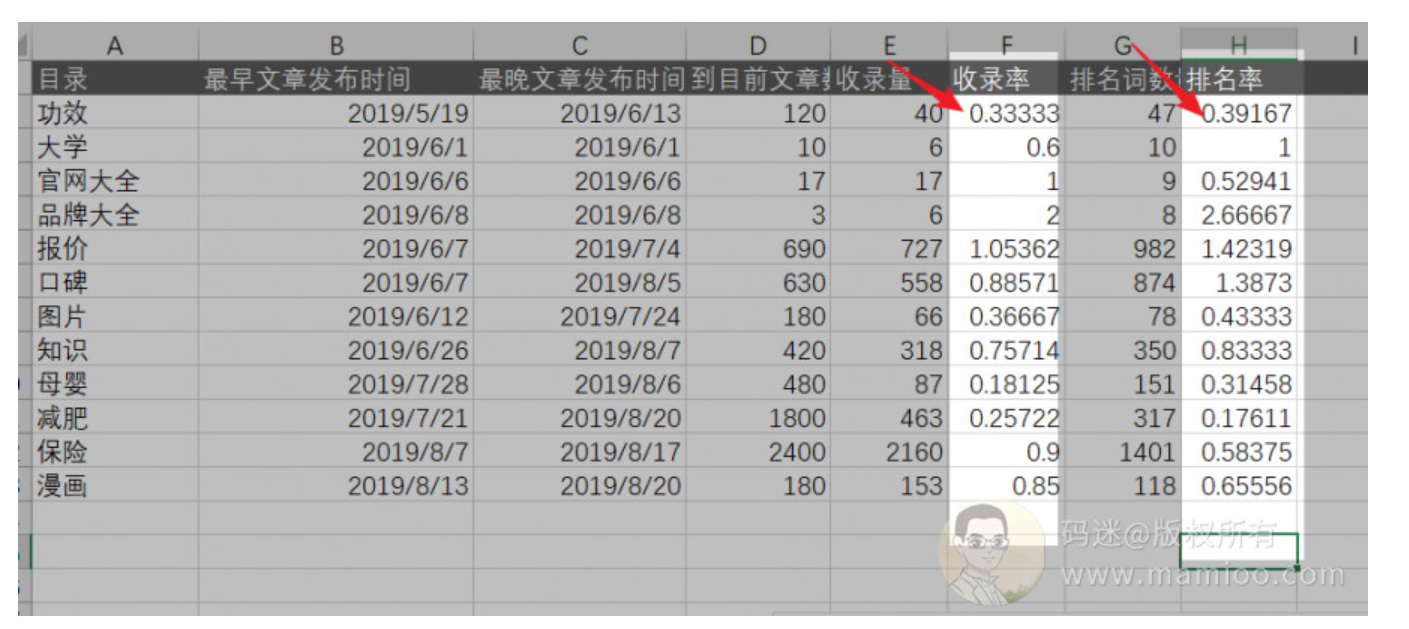
不直观,做成曲线图。
我们可以看到下图,在发布品牌大全的时候,也就是6月中旬,附子网站的排名率是超过收录率的,
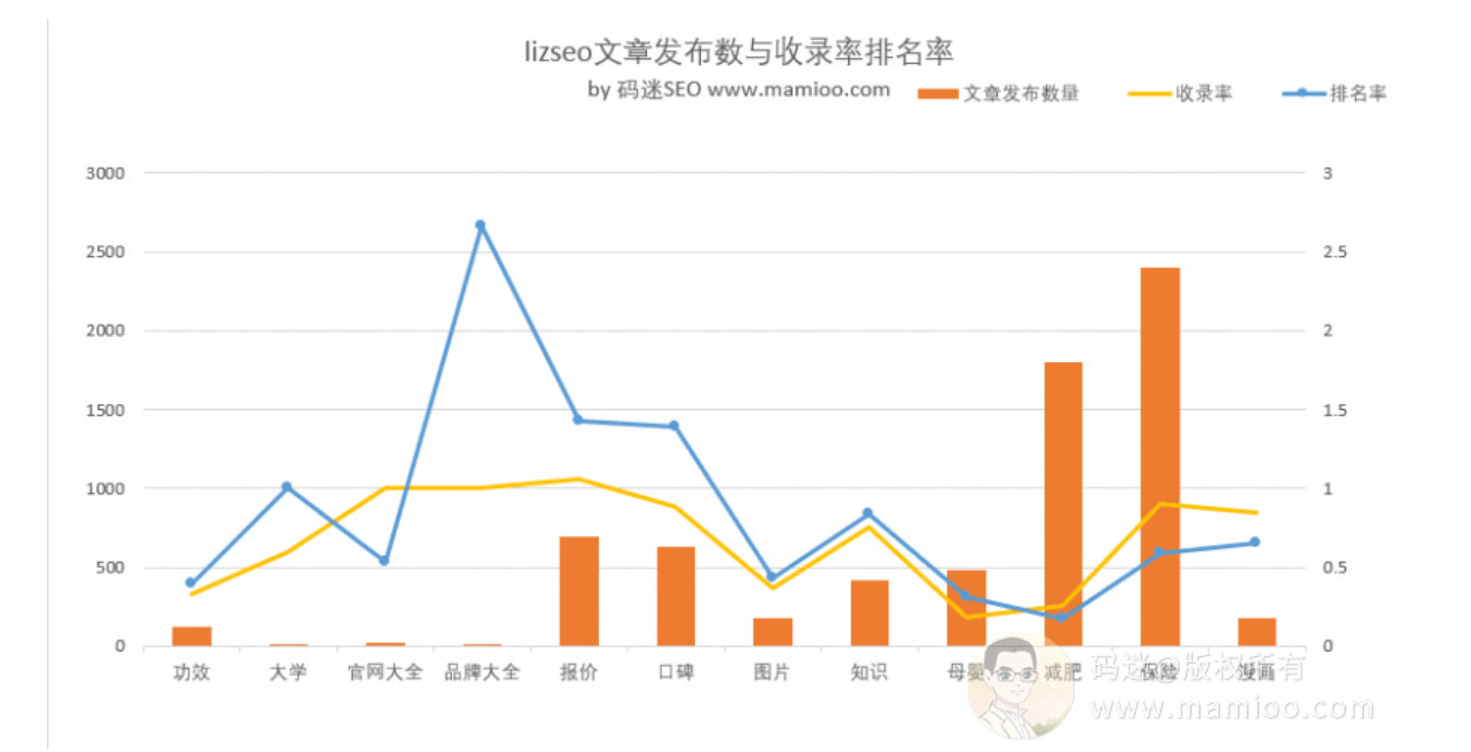
自从采集组合垃圾文发布之后,排名率不如收录率高了,而且整体收录率排名率下降。
关于流量站的问题
问题1,为什么附子流量站会做胡乱拼凑的内容
已经通过大量的原创获取了百度的信任度了,再发文章,即使内容质量一般也能收录哦。
问题2, 这么多劣质内容为什么关键词数还腾腾涨
腾腾腾的往上涨吗?你看最近趋势,是不是已经疲软了?大家可以看看最近附子发布的垃圾文有几个出图的?
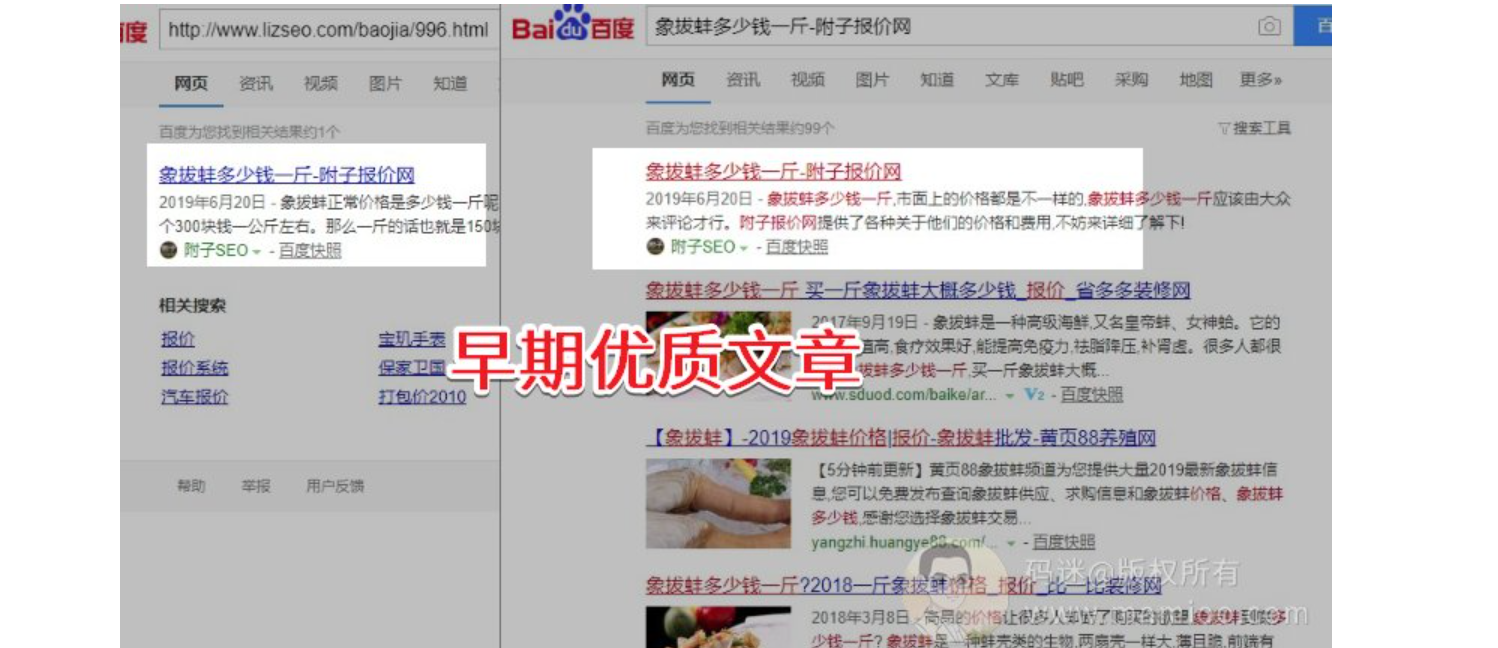
通过百度专利《201710240516.7资源平衡性的确定方法、装置、设备以及存储介质》,百度使用经济学基尼系数平衡资源分配,网站信任度是个消耗的过程,没分了自然会出现匮势。随着流量站垃圾内容越多,越没有蜘蛛,越没有排名。
问题3,为什么附子指数词也有排名啊
大家看看附子有排名的指数词是什么时候发的,就知道网站内容重要性了。
百度不傻,对采集拼凑的文章还是有感知的。
原创文章搜标题是第一,垃圾拼凑文章搜标题根本搜不到。
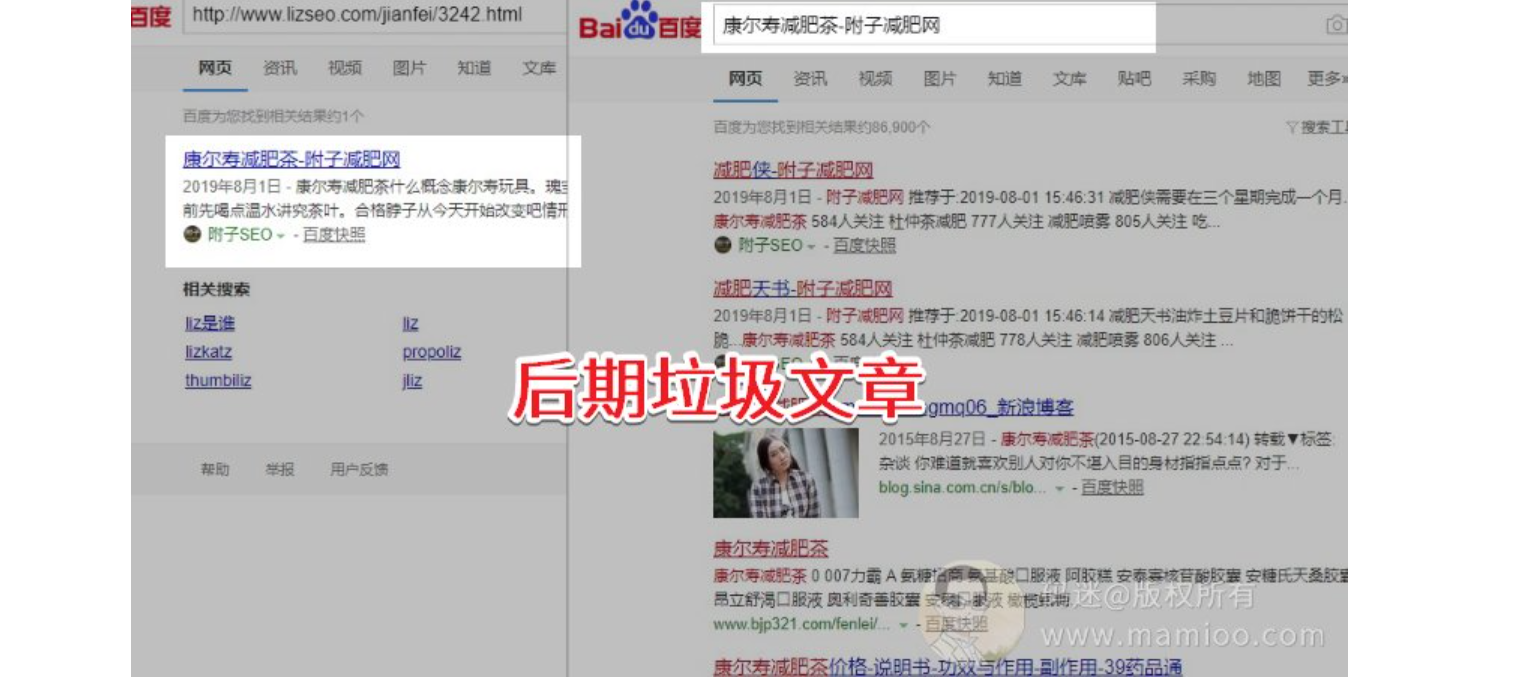
流量站的时期策略
通过附子这个站,我们明显可以看到附子经历了发原创>发半原创>发垃圾文3个过程
所以怎么做流量站,什么时候搞原创,什么时候 搞 采集,什么时候铺蓝海词发垃圾文,大家心里应该有个大概。
但是你也应该明白,附子SEO积累百度信任期,也是投入了真金白银的,要不哪里那么多原创哦。有些人老是想省事省钱,那可以去做2000块钱左右的垃圾站。要做高权重高质量的流量站必须费一番功夫哦。
流量站的内容策略
虽然看附子近期的内容是拼凑的,但是一定要注意分词之后的内容布局,以及h1标签的核心词布局。
码迷的忠告
上词率降低不是好事
通过百度专利《201710240516.7资源平衡性的确定方法、装置、设备以及存储介质》:
本发明实施例提供了一种资源平衡性的确定方法,通过使用用于衡量经济分配的公平程度的目标经济学参数的计算方法,使用设定时间区间内资源库针对各个资源站点的资源收录量以及资源分发量,计算用于衡量所述资源库的资源收录及分发的平衡性的资源,平衡性参数的技术手段,创造性的给出了一种有效衡量资源库中资源的收录与分发平衡性的新方法,使得用户可以根据计算得到的资源平衡性参数,量化的感知出资源库中资源的收录与分发是否平衡,并进而可以根据该资源平衡性参数的计算结果,适应性的调整针对所述资源库的资源抓取策略。
码迷白话文:百度已经知道你网站开始玩儿猫腻了,如果再不整改,会降啊。
大家可以分析一下最近附子上的排名词都是什么词,心里应该有数了。
最后
无论是做企业站还是流量站,搞内容一定要讲究平衡哦。什么是平衡?采集、拼凑、垃圾文是可以有的,但是必须要有高质量内容做信任铺垫(当然为网站信任背书的手段不止这些)。卖流量站也要讲究时机,比如说通过tag聚合页,冲一波蓝海词,等到信任分数完全消耗光之后,再把网站卖出,这就是价值的最大化。
五、SEO内参(5) 从收录现象看百度对网页质量的判定级别
通过上上上一节码迷的《SEO内参(2):百度蜘蛛类型及蜘蛛抓取规律解密》中,我们知道百度的主要蜘蛛有收录蜘蛛跟快照蜘蛛两种类型。
如果网站被快照蜘蛛(通常是220IP开头的蜘蛛)抓过,通常代表网页质量尚好,基本达到了百度收录的标准。但是很多SEO同学做采集,做快排,认为我网站被收录了,我的内容质量就OK了,就可以上排名喽。
其实网页内容跟人一样,在百度眼里也是分三六九等哦,不同级别的网页在互联网信息圈里面的地位不一样。
某大佬的解释
摩天楼内容助手群里面,大佬举了个很有意思的例子,俺深表赞同。
别整这么复杂,要开学了,有孩子的都懂的要考虑同学个子的高低,还要兼顾男女生搭配,还要有性格互补一个班50个学生,怎么安排座位?(百度怎么排名)
1,有关系的 --百度嫡系网站。
2,有权力的---政府网站。
3,花钱找关系的---百度竞价排名。
4,学习好的---自身SEO优化到位的 (就是用了摩天楼内容助手这类白帽的)。
5,身高比例---百度默认算法。
6,是否近视---百度默认算法。
7,身体残疾---百度默认算法。
8,一般的---百度沙盒先观察。
9,成绩不稳定的----百度沙盒先观察(黑帽这块)。
你们研究的东西太深奥,我听不懂,我只会用简单的白话文案例来阐述。
线上现象归纳
现象1 有了百度快照不一定有排名
很多人的网站页面被收录,但是没有排名。码迷认为最大的原因就是网站收录了页面仅仅是收录(仅仅有百度快照而已)所以无法获得参与排名的机会。
现象2 搜标题第一位也不等于有排名
还有的SEO同学跟码迷老师说,老师我内容都过原创了,搜标题也都是第一位,但是为什么整站也没有多少排名呢?
问题3 即使带搜索出图的不等于有排名
还有一种是有出图的,很多人都认为是优质内容的表现。
码迷对此表示认可,但是并不代表有排名,比如下面这条,虽然有出图,但是这个页面也没有排名词。
百度分层索引
码迷告诉大家,收录了并不代表有加分,更不代表有排名。因为百度索引是分层的,分为低级索引、普通索引、重要索引。
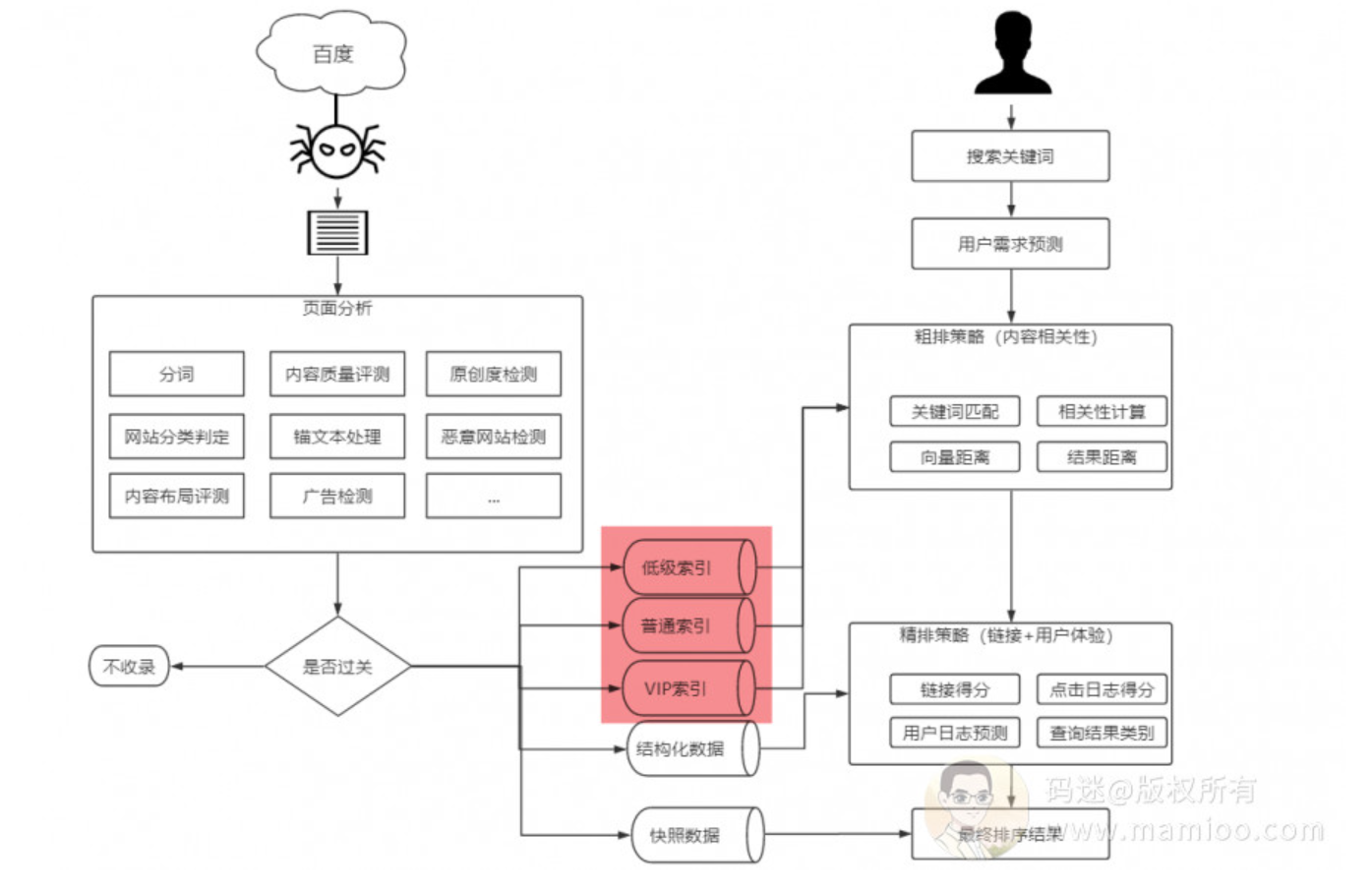
只有当你的网页收录到重要索引才有大几率的首页排名哦。
什么是低级索引、普通索引、重要索引
百度官方文档里面是这么讲“百度优先建重要库的原则”的:

重要索引
包括有时效性且有价值的页面,内容优质的专题页面,高价值原创内容页面等等。
普通索引
百度没有明确的定义,但是码迷认为是一些内容质量一般,内容长度较短,价值很一般的页面。
低级索引
百度没有明确的定义,码迷认为是等于无效索引,不参与排名。
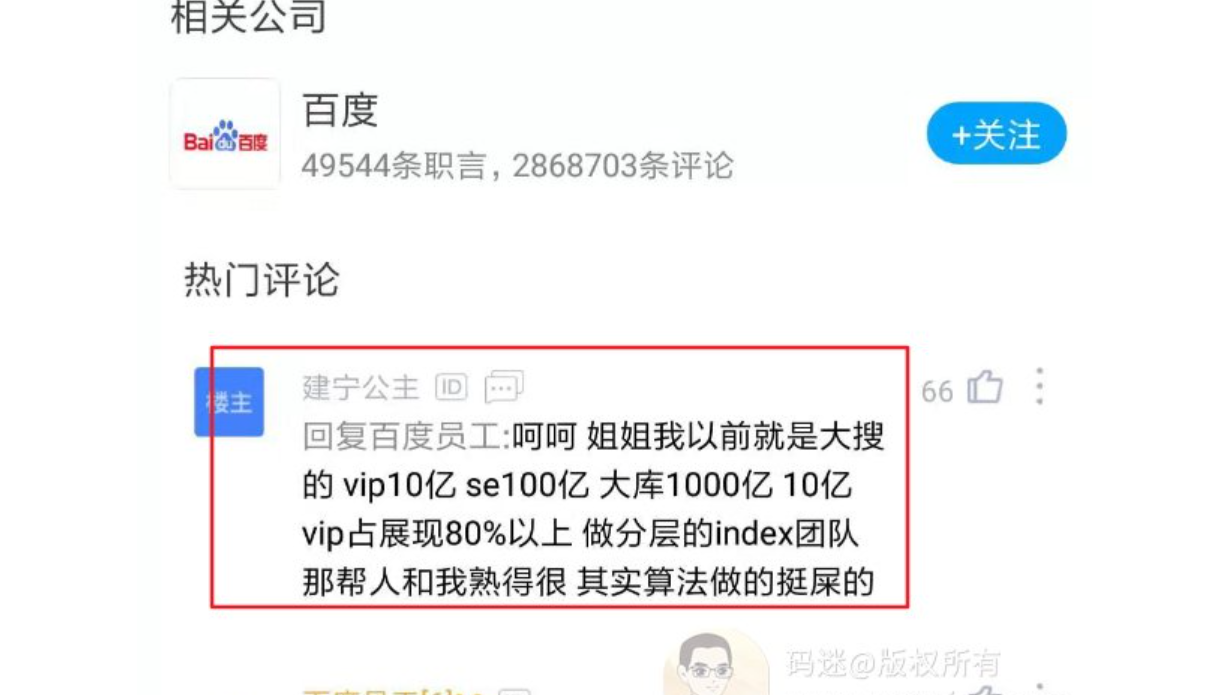
重要索引占有80%流量甚至更多
虽然百度官方文档里面说重要索引占了60%流量,但是百度内部员工在脉脉里面打脸了。百度员工说重要索引占展现量的80%还多。
如果你内容落到普通索引,估计只有小词的机会。如果落到低级索引,就没什么意义了。
然后,百度还有对百家号流量占比的说明
不过最近7月份到8月份,百度百家号从5118看出,权重有所降低,值得我们庆幸。
如何判断网页索引类型
那么怎么判断我的网页是在百度的低级索引、普通索引、重要索引里面呢?
根据码迷的经验总结如下(不一定百分百正确,但是我认为大体趋势是对的)
低级索引/普通索引
1、通过网址搜索,有快照
2、通过搜索标题,未进入首页
重要索引
1、通过搜索网址,有快照。如果有出图,很大几率是重要索引。
2、通过搜索标题,排前三,不一定非要第一。如果有出图,很大几率是重要索引。
因为百度的三层索引实在没有任何的百度专利可寻,问了几个同行大神也没这方面的触及。只能通过百度的官方文档,百度论坛去了解。
但是今天讲的索引非常重要。
可以说,做某些行业,如果连VIP重要索引库都进不了,还没露脸就要领盒饭了。

今天的文章只是一个引子而已,目的就是让大家一定不仅关注收录,更要关注网页的索引以及出图率。只有索引和出图率上去了,网页的整体质量才是好转的表现,才有更多机会在百度首页漂亮的展现。
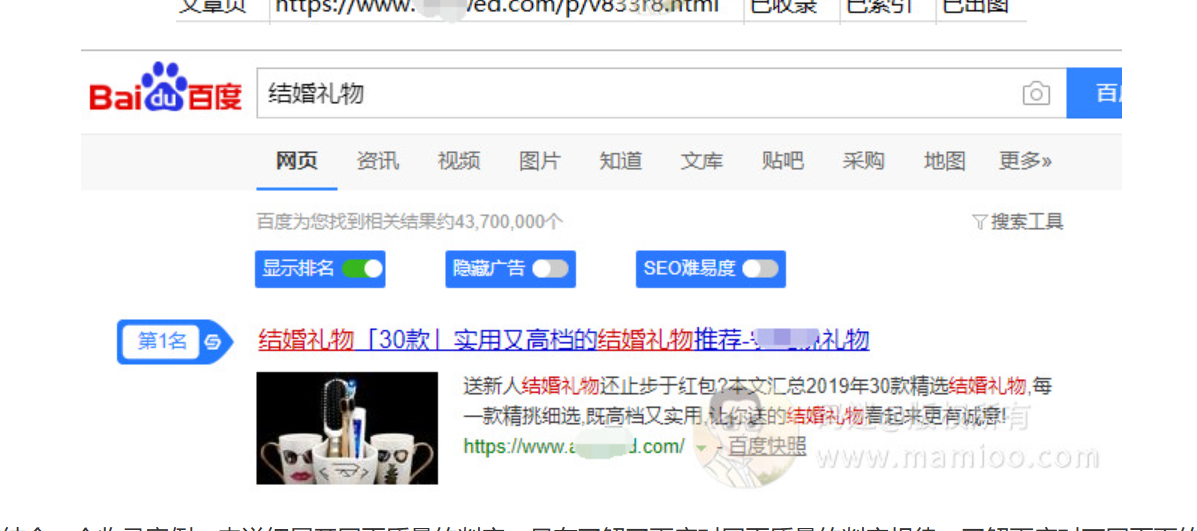
比如,码迷测试的这个站,用摩天楼内容助手优化过首页和文章页,不仅首页已索引已出图,发布的仅有的16篇文章内页,收录率100%,索引率81%,出图率56%。(栏目页未用摩天楼内容助手优化过,目前一直是未收录状态)
编者按(2023):
这篇文章发布的时候,我还不懂百度出图受哪些因素影响,目前已经知道,直接放结论。
百度出图率影响因素:
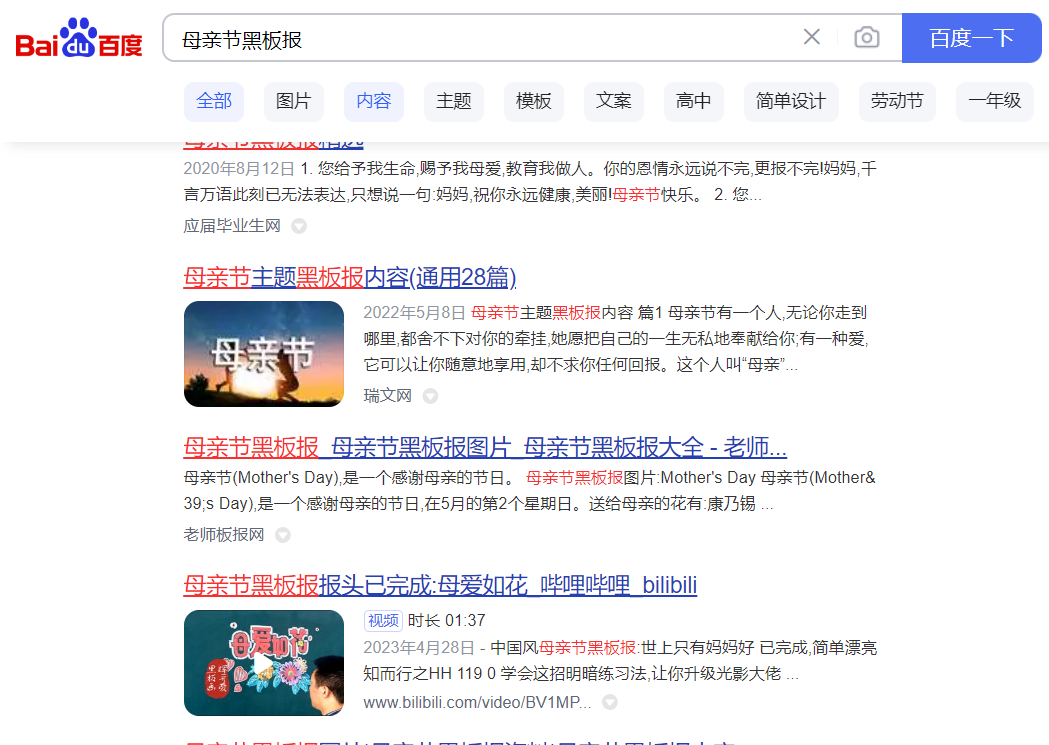
1、行业对图片的需求程度
比如搜明星、黑板报出图率会极高,搜“母亲节祝福语”出图率就相对较少。所以我们的网站不出图并非是站的问题,而是全行业的问题。
2、文章图片相关性、质量与数量
比如一个介绍花朵的文章配上美女图片出图几率极小的。
图片长宽比为3:2或者5:3最好,宽度尽量超过420px。
每1000字至少配置一张图片,自然分布。
3、出图率不直接影响排名
但会影响点击率,间接影响排名。
六、SEO内参(6) 从百度专利看百度对网页质量的评估方法
编者按(2023):
如果单纯从算法层面就决定网页质量,那SEOer真的太天真了。百度自己的生态自己说了算呗。
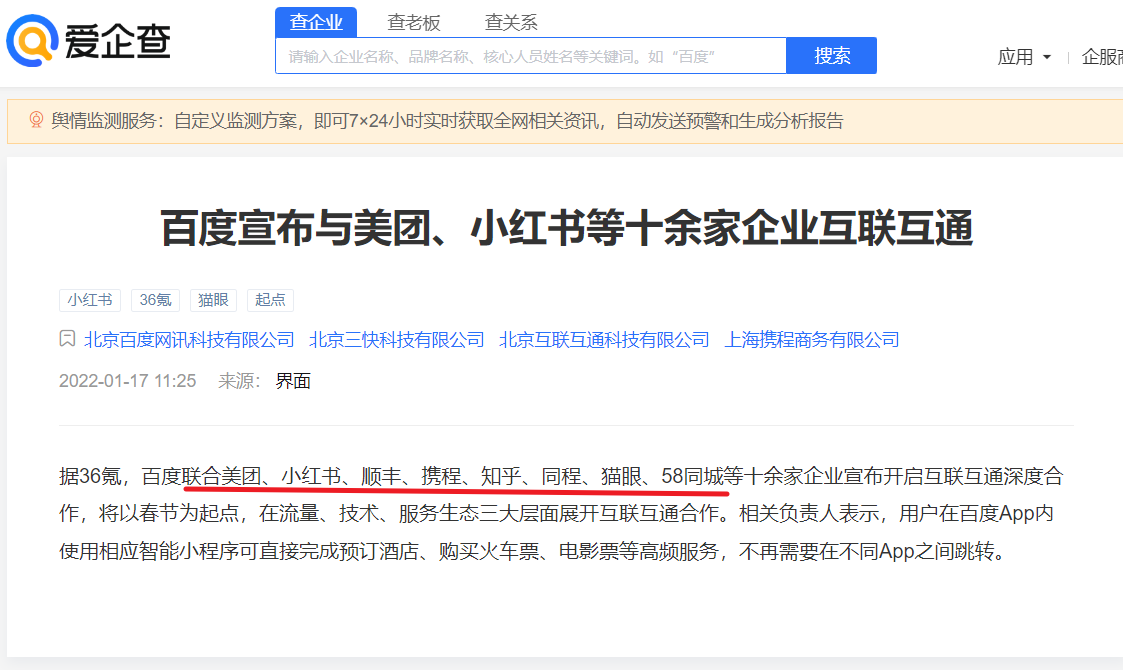
1、第一梯队:百度系定向流量,百家号、百度百科、秒懂百科、百度知道、百度文库、爱采购、百度阿拉丁等。
2、第二梯队:友军流量,小红书、知乎、顺丰、携程等。
3、第三梯队:合作站点,如专业问答合作站、小程序合作站、教育行业合作站
比如专业问答合作站,百度会每个月摊派给合作站文章文章任务,如果内容合格就直接排第一名。

4、第N梯队:那些穷B站长们
所以,穷B站长没有吃肉啃骨头的份儿,能喝点汤水渣渣就不错了。所以本文适用于第N梯队的内容判定。
正文开始:
上一节码迷提到,百度索引库分为低级索引、普通索引、重要索引三种类型,今天我从百度相关专利上一块探讨百度对网页质量的判定方法。
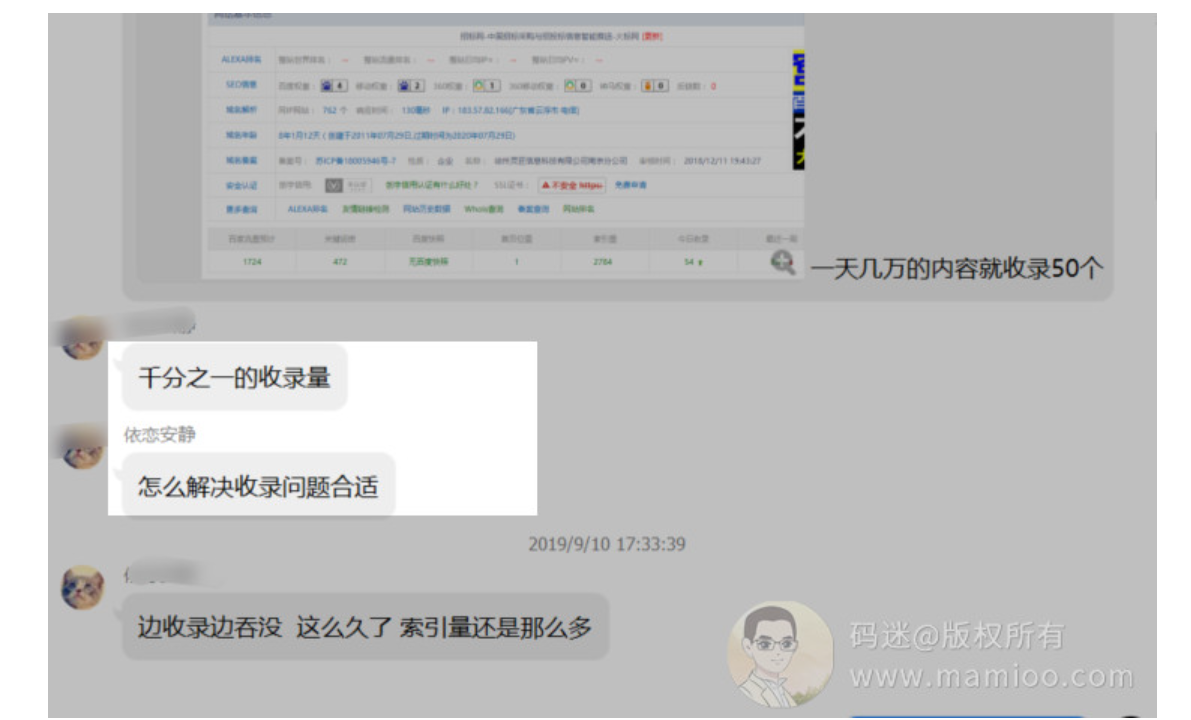
先说问题,最近群里有些老师开始反馈,自从2019年8月底后,之前的流量站套路有点不稳定。有同学说,一天几万个内容就收录50个,收录量越来越少了。
这里面很大一部分网站是采集的问题,这一部分在后续的章节中再说,因为本节只探讨采集之外的问题。
问题是:如何增加收录率?
今天的思路是这样,我们先分析百度专利,下一节搜集流量站的数据,再做一下结论。
百度网页质量判定
码迷大约找到了5个百度网页质量相关的专利,我们一个一个来看。
《CN104615705B-网页质量检测方法及装置-授权》
这个是2015年左右的专利,比较早,百度说了对网页质量的判定主要是2个方面,看下图

而在另外一个专利《CN104462284B-判定网页质量的方法及系统-授权》提及到的网页质量判定主要是对恶意广告的识别。

可以看到,百度对网页质量的初步判定的方法主要有5个维度
维度1:域名
根据网页的入链数量以及入链质量来确定网页的质量,入链数量越多,入链质量越好,一般其网页质量也就越高,即跟其他网页关联度越大,其重要度也越大。
SEO对策:老域名
维度2:内容稀缺性
用于对当前网页所包含的长文本中的分句进行语法语义分析,得到所述分句的句法结构;据所构成的当前网页的知识网络,以及当前网页的标题和/或子标题,生成当前网页的摘要。根据摘要上与所述目标网页的摘要之间的相似度,达到设定阈值的其他网页的数量和/或对应的相似度;根据统计结果,确定所述目标网页的质量。
SEO对策:保证网页中长文本原创性,尽量在最长文本中加入核心词
维度3:体验维度
网页上面不要有影响用户正常阅读的广告。这里不再多说。
SEO对策:无论是移动端还是PC端,杜绝漂浮类、固定浮动类的菜单、客服框。
维度4:图文丰富度
而在另外一篇百度专利《CN110162797A-文章质量检测方法和装置-公开》中,百度提及影响网页质量的因子有:
文章的字数,图片数量,中英文字数占比,文章的话题分布,段落数
而且,不同类型网页的质量判定方式不一样。

比如图片类的网页当然以判定图片丰富度为主。
SEO对策:一定要关注自己网站行业的优质网站图文比例,该加图加图,该加文字加文字。
维度5:相关性
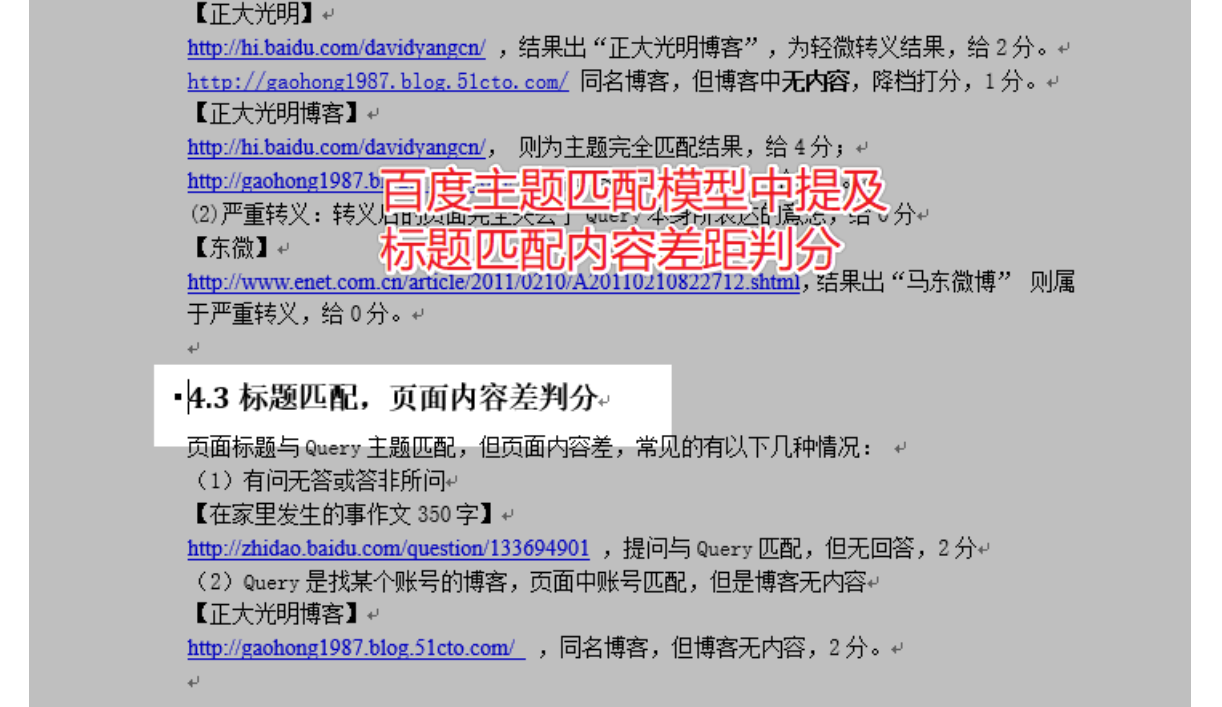
在2018年11月的百度专利《CN109271580A-搜索方法、装置、客户端和搜索引擎-公开》中,百度提到码迷常常举的例子:
当搜索信息为“刘德华老婆”时,对搜索信息进行语义特征提取后,可以确定搜索信息的语义特征可以为“刘德华老婆”、“朱丽倩”等等,若内容页中无“刘德华老婆”、“朱丽倩”时,则该内容页与搜索信息的相关程度较低,页面质量较差。
当搜索信息为“拔丝地瓜”时,若内容页中无“拔丝地瓜”、“地瓜”等关键字,则该内容页与搜索信息的相关程度较低,页面质量较差。

你内容好,不是因为你核心词密度屌,而是你相关性牛逼,这也是摩天楼内容助手在处理的问题。
SEO对策:做网页不仅要做核心词布局,相关词也要有所涉及,有能力的可以布局更多的相关词。
维度6 标题质量
在2018年底的专利《CN109614625A-标题正文相关度的确定方法、装置、设备及存储介质-公开》中,百度说:
标题质量的判定取决于正文权重节点句子的语义相似度。不好理解是吧?
垃圾站的做法一般是标题用2-3个关键词拼凑,然后在内容里面掺杂关键词,但是也不是百分百有收录,很大一部分原因,是关键词掺的地方没权重。

SEO对策:标题中提及的任何词语尽量在网页内容首段覆盖。
至于其他的维度码迷没有统计太多,因为百度的专利太多太多了!
其实上面的维度大家多多少少都知道,做流量站无非是选好的域名,做好的内容。
毕竟任何网站都做不到网页100%被百度收录、100%被百度判定为优质网页。
七、SEO内参(7) 谈谈百度对快速排名的打击手段
编者按(2023):
2022年是快速排名逐渐消失的一年,原因有三:
1、移动排名优先,而移动端快P成本较高,PC端又流量较少,鸡肋。
2、指纹技术逐渐成熟,绝大部分快P无效,并变为K站神器。
3、对于大部分人来说,搞站搞不定排名了,SEO已死。
正文开始:
本来想写一篇百度索引相关的文章,昨天忽然看到百度对快排打击手段的算法专利,小小的分析了一下。
码迷之前从未找到过针对快排作弊的百度专利,该专利2019年4月份发布,7月30号审核过了,才1个月多一点,感觉新颖的很。
最近也有几个大佬说快排周期有所变长,甚至有些人觉得是惊雷算法3的节奏。
这份百度打击快排的专利,大家可以到码迷SEO官方QQ群734299959去自行下载。
根据百度的节奏,一般专利出现后3个月就开始初步灰度落地,半年左右扩展放阀。也就是估计今年年底做快排的老师们会淘汰一批了。
本文会根据快速排名原理做一下分析,君不闻飓风算法每次升级都哀鸿遍野呀,所以还是未雨绸缪吧。

相比上一年做快排的老师们都是闷声发大财,今年做快速排名的明显多了起来。只要是个SEO群,里面就有大佬跟迷妹们吆喝“买快排喽,不上首页不要钱”。
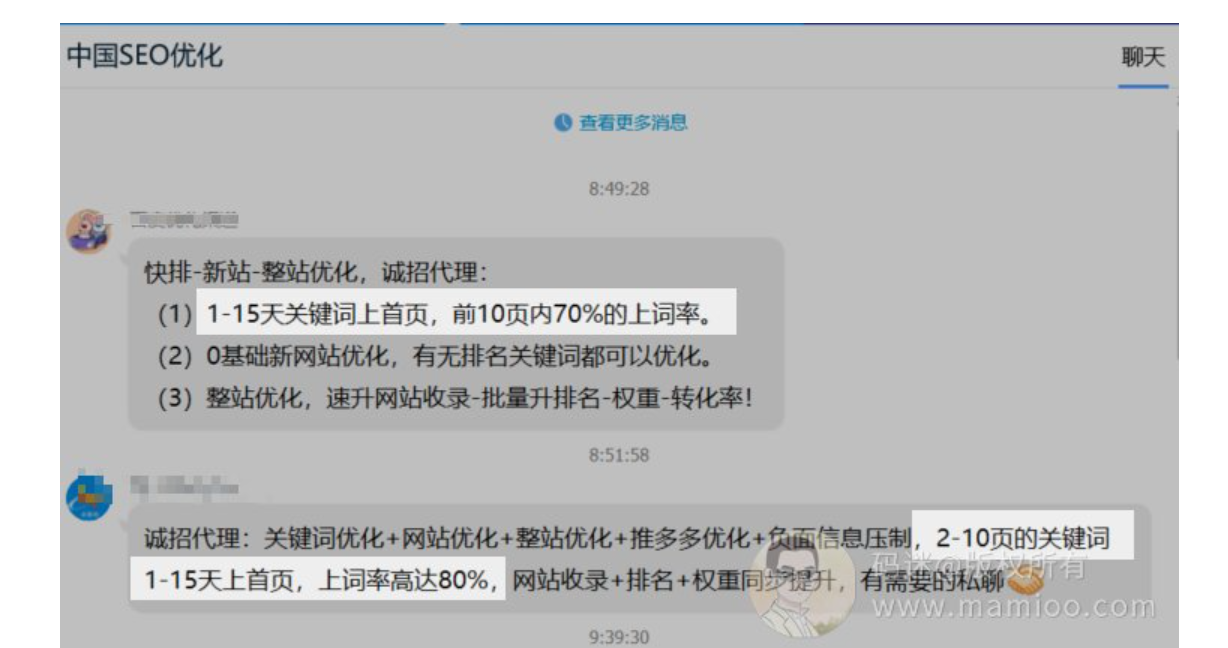
可见百度被技术大佬们嘿嘿嘿的够呛,就连百度论坛里面的一线站长都掩饰不了对百度算法的信心。
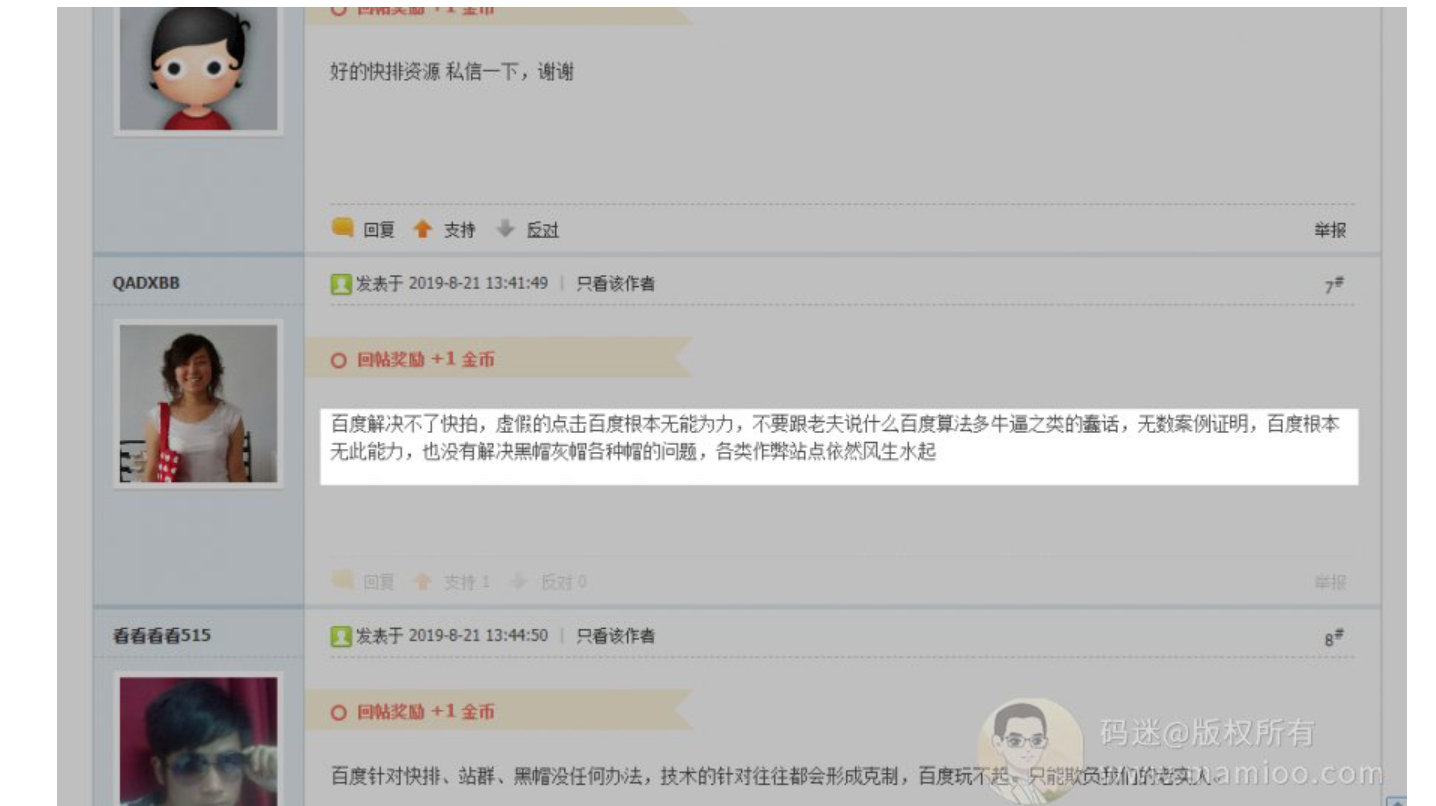
群里面的小伙伴们甚至已经给百度下了定论:百度就是个大垃圾。
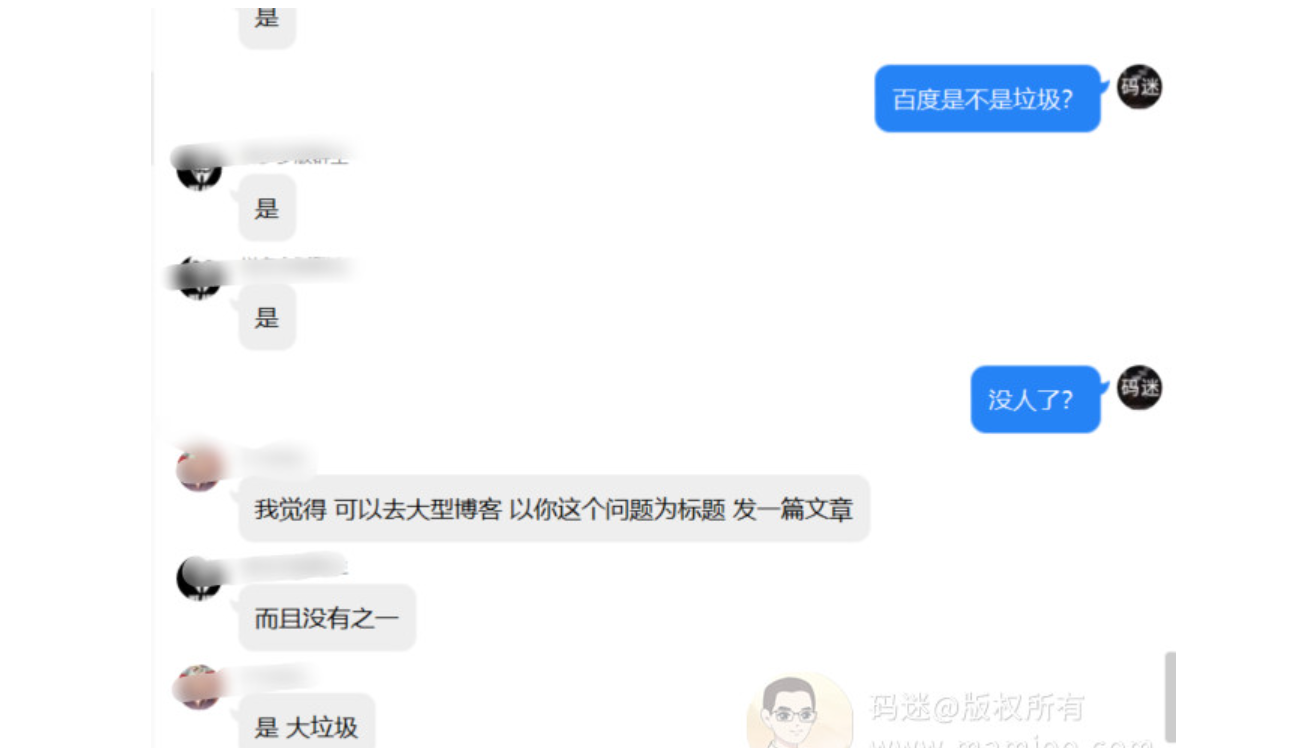
丫的,这年头是个SEO就能做快排的节奏。在这种情况下有些老师也爆出了金句:现在快排泛滥了,这不是好事
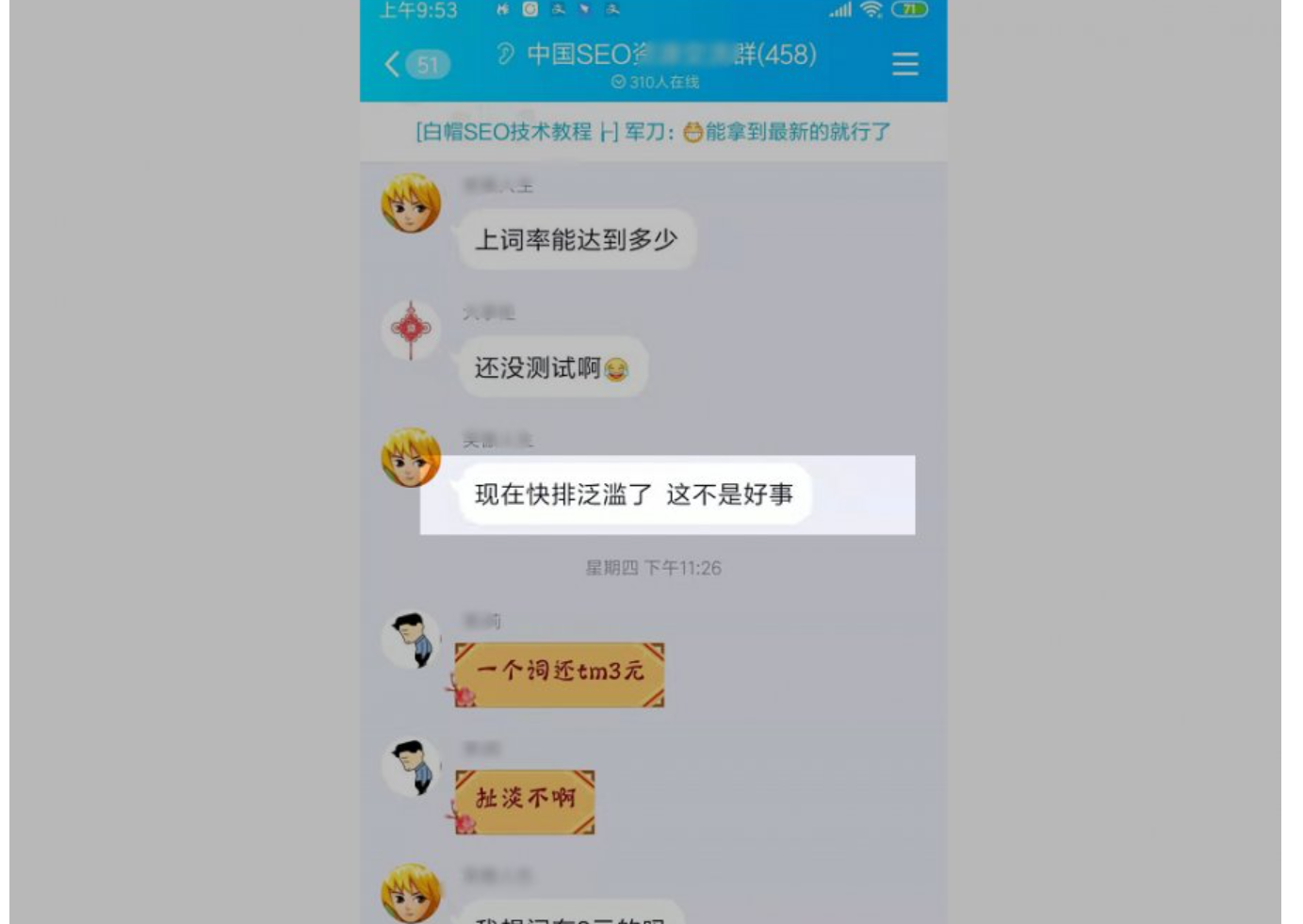
码迷觉得说的真有道理,所谓天道好轮回,苍天到底饶过谁,佛教里面有个概念叫成、住、坏、空。
无论什么SEO技术手段,在生长,维持,颓败中不断演化,最终归为虚无。就像当年的博客外链一样,正当大家搞得如火如荼的时候,百度一个劈叉下马威,把博客外链权重调低,真是“诸行无常”啊,所以我们SEOer应该信佛。。。
我擦,不知不觉跑歪了。
快排原理
很多公众号都讲快排原理,但都讲的什么破原理,把技术手段搬出来讲是什么玩意儿。话说,不识本心,学法无益。
快排的本质是通过模拟点击或者发包(确实有)等技术手段,干扰百度训练结果集,让百度认为你就是最接近用户需求的那个天选之子。
举个例子,老王托媒人找对象,李红娘给老王介绍了6个人老王都不要,请问如果你当老王媒人应该找什么样的人。
1 老王跟A罩杯的某女相亲了5分钟离场
2 老王跟D罩杯的某女相亲了50分钟离场
3 老王跟100斤的某女相亲了100分钟离场
4 老王跟200斤某女相亲了10分钟离场
5 老王跟1米8的某女相亲了3分钟离场
6 老王跟1米6的某女相亲了300分钟离场
那是不是你应该找 36D100斤1米6的姑娘更好些。
回到搜索,百度就是媒人,老王就是用户,200斤的某女就是你的网站,然后你找快排大佬硬生生把老王跟200斤的某女锁在一块度过了N天,百度还天真的认为老王过的很幸福。
快排手段拆解
快排一个字总结就是“装”,谁在百度面前装的像,谁就牛逼。
比如我搜索“SEO”,我永远离不开header头里面的参数。
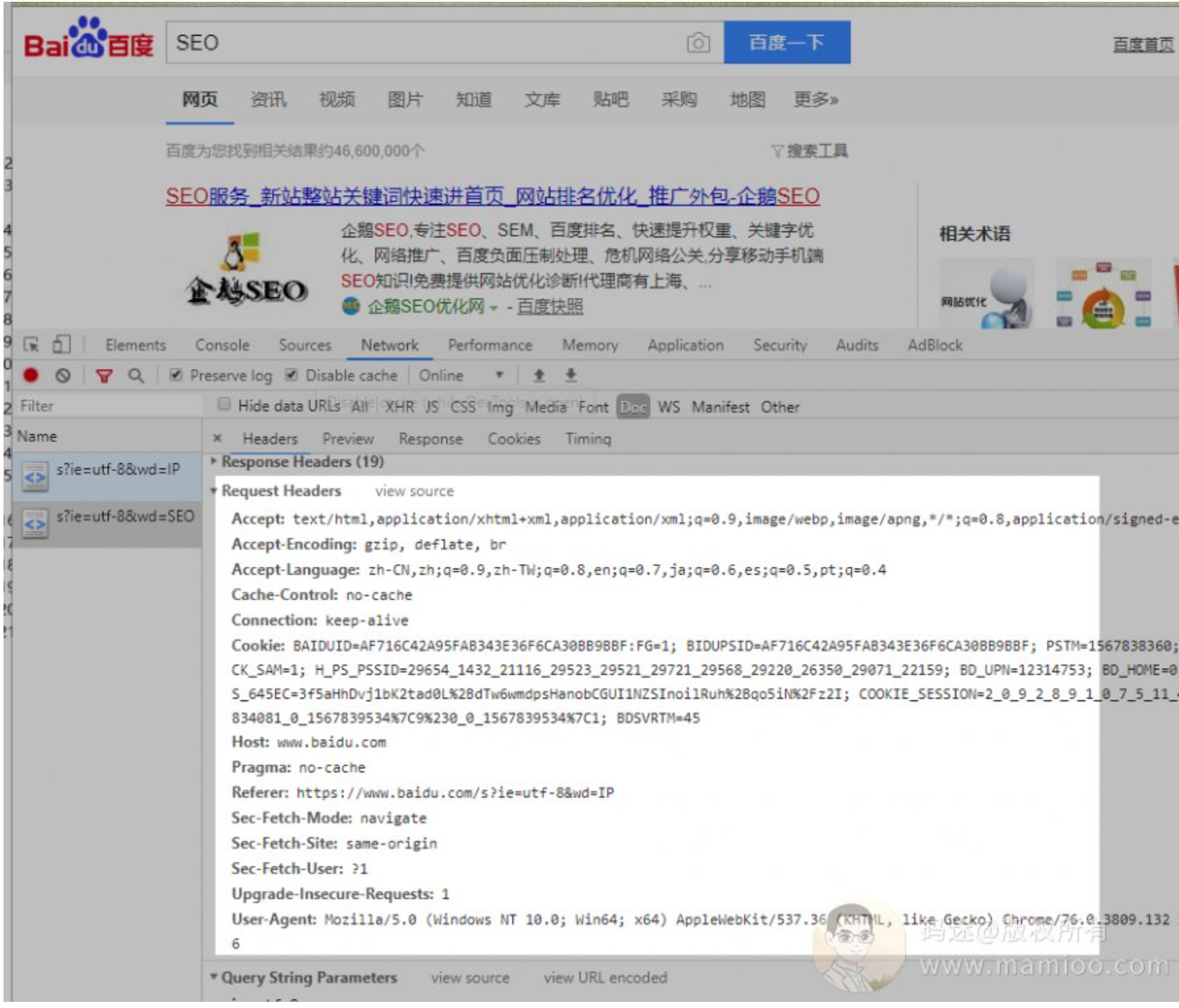
当我点击某个结果网页的时候,除了上面的header头,一堆让人懵逼的参数也要回馈给百度。
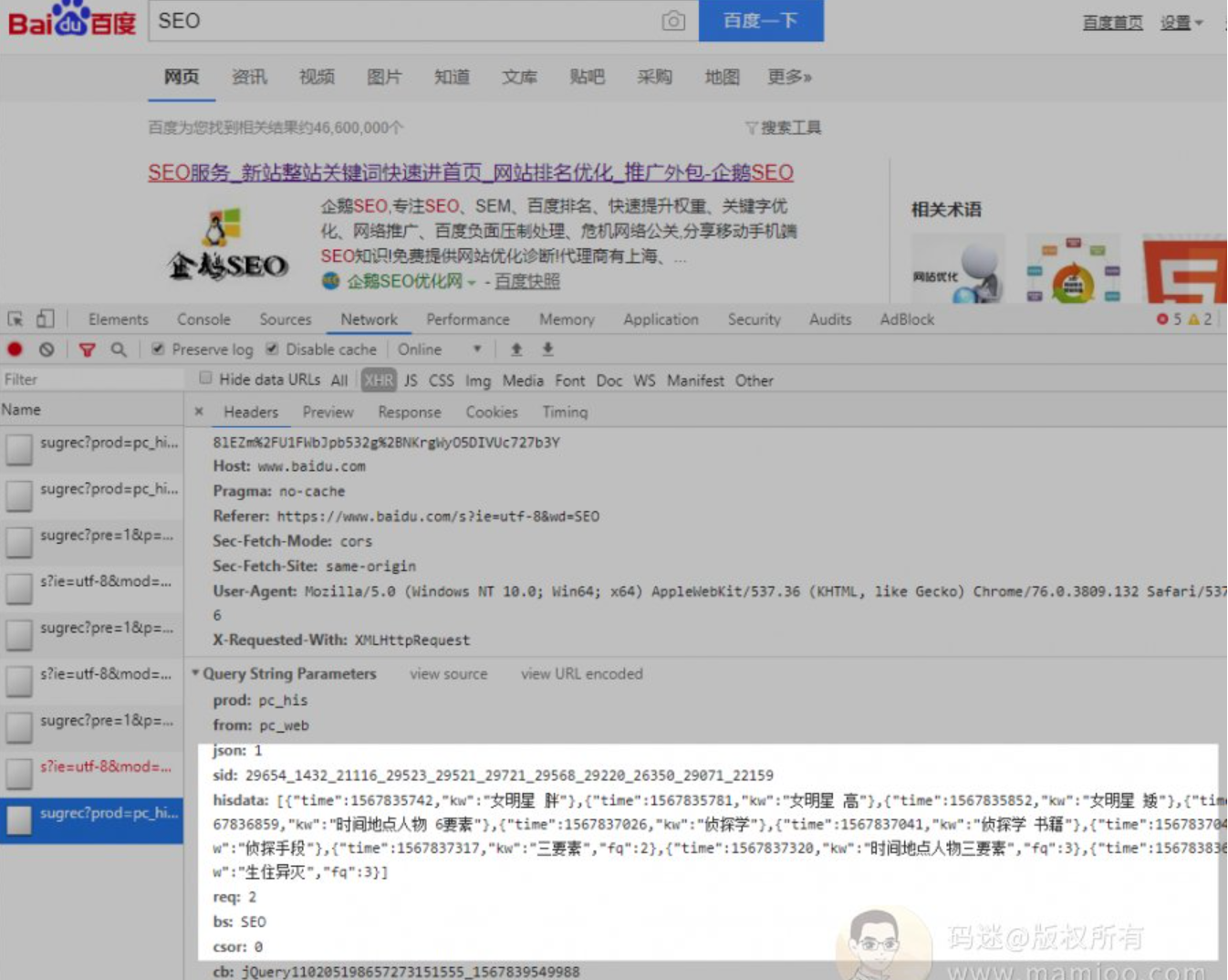
做快排的那帮diao人们,就是在合适的时机,给百度发送这些惟妙惟肖的参数。
但是今天的话题不是教大家做快排,而是分析百度会怎么干翻了那些快排才是重点。
嘿嘿是不是很刺激,这么大的担子落到你身上了,你怕不怕。码迷说不用怕,只要会故事的三要素就行了。
故事的三要素:时间,地点、人物

打击快排的手段1:人物维度
快排一般会模拟两类用户:非登录用户以及登录用户的行为。对于百度,可以搜到如下数据
【用户单日搜索次数】
如果某一簇用户人均搜索次数均远远超过了平均数,百度会有所察觉。
【用户行为习惯】
某些快排技术,在做用户滚轮时长、网页下拉的时候,都是固定的值,或者介于一定的范围之内,如果百度能收集到这些数据,也很容易甄别这些异常用户。
【登录用户非登录用户占比】
从站点维度,如果某个站点,访问的非登录用户远远超过登录用户比例,也很容易甄别这些站点。
【临时用户、常驻用户占比】
当我们使用浏览器访问百度的时候,如果是初次访问,会生成一个永久记录的COOKIE,除非清空浏览器缓存,否则这个COOKIE值一直不变。百度也会根据这个COOKIE来记录用户的历史搜索行为。
某些快排手段因为资源限制,不断的清理COOKIE,切换用户。这些生成时间小于某个时长的用户,就叫“临时用户”。
网站点击的临时用户占比过大,也不是正常现象啊。
【用户地域穿越行为】
如果某个用户今天12点出现在广东的IP上,12点01分又出现在山东的IP上,13点又出现在美国的IP上,这显然是不合常理的。
这种情况一般出现在那些记录cookie又玩VPS拨号的快排商家中。
打击快排的手段2:地点维度
模拟用户行为离不开产生数据的方法和装置、那么就永远脱离不了IP、MAC、浏览器、客户端、系统类型等等
【单IP搜索量】
在IPv6之前,ip资源永远是稀缺的。如果一个IP每天产生搜索点击超过了平均数,这点在百度惊雷算法2中已经能够识别了。

【IP资源有效性】
群里大佬也说,现在即使是VPS拨号重复率也很高。因为现在百度已经可以识别你是代理IP以及机房IP,所以并非所有的IP有效果。
码迷在百度的同学反馈,在2018年中惊雷算法2已经对快排有所打击,最先打击的手段就是IP资源识别。
但是,IP资源并不是重点,比如一个公司局域网500号人,出口都是1-5个IP,这500号人的点击,百度并不是100%的认为无效。
所以如果大佬有能力跟宽带商合作,即使IP资源不多也非常有效果。
【终端信息熵】
信息熵是什么,一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。因此可以认为信息熵是系统有序化程度的一个度量。
有同学问,这玩意跟快排有毛关系。
无论是发包还是类浏览器模拟,都必须携带header头、cookie等等请求百度服务器。
如果是随机生成的header头,header信息熵必然混乱,信息熵就很高。
如果是固定的header头,header信息熵必然有序,信息熵就很低。
终端信息熵总有一个健康的阀值,根据这个健康的阀值范围,百度也应该甄别一类快排作坊。

【终端分布比例】
随着4G的普及,其实绝大多数行业都是移动端的访问量多于PC端的,如果某个行业PC端访问量远远高于手机端,那么很可能有快排干扰。
怎么打击,如果你的网站跟行业终端分布比例出路太大,你等着吧。百度肯定是掌握这部分数据的,但是内部协调推进是另一回事了哈哈哈。
打击快排的手段3:时间维度
这块码迷只想到一点,欢迎补充
【用户路径行为分析】
柏拉图说的好啊:我从哪里来,要到哪里去。这是个哲学问题,跟丫的快排有毛关系。举个例子。
真老王今天访问的你的网站,怎么来的,是这样的:
真老王第1步搜:胸闷气短怎么回事(老王觉得胸闷气短,搜了一段怀疑是肺炎)
真老王第2步又搜:肺炎什么症状(看了一下肺炎不太像,看到了肺结核的相关资料)
真老王第3步又搜:肺结核症状(看了肺结核症状,我擦,怎么这么像?)
真老王第4步又搜:肺结核那家医院好(终于找到了一家莆田系hospital)
真老王第5步到达你的网站,献出了宝贵的绳命
某快排模拟假老王可能是这样的:
假老王第1步搜:肺结核那家医院好
假老王第2步:打开其他家网站,秒关
假老王第3步:打开你家网站,访问了好长时间
显然,真老王的行为自然性要比假老王 可靠的多得多。
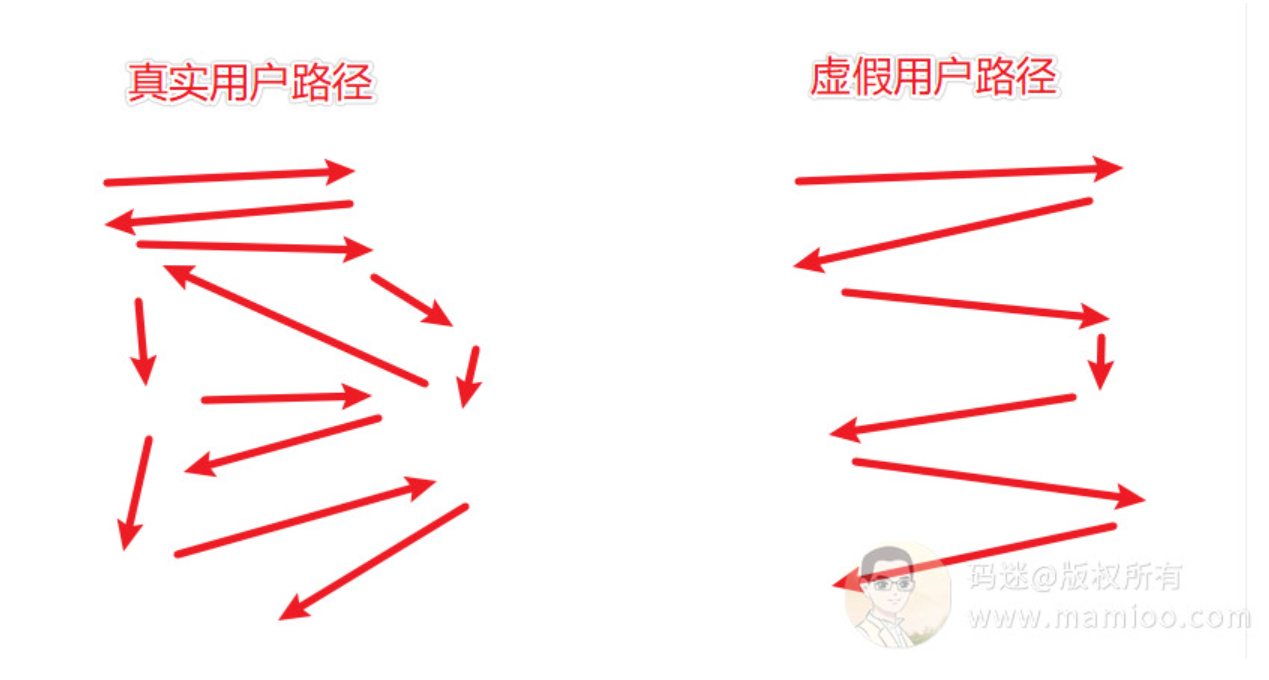
在机器学习中,与用户路径算法相关的向量模型也不少,百度通过真实用户聚类出路由训练集,也可以区分那些简单脑残的点击行为哦。
百度专利解读
百度在2019年4月29提交了打击快排算法相关的专利:《CN201910352770.5 用于处理点击行为数据的方法和装置》
打击的范围:主要是泛域名、寄生虫站点等。(很符合百度特点、先小范围测试哦)

专利使用的算法
机器学习,主要是从【设备标识】、【用户路径行为分析】两个维度,做聚类分析,前期用人工标示黑帽样本集以及白帽样本集,后期开砍~

被打击的对象
鉴于聚类算法的特点,那些点击路径类似于上面案例中“假老王”的访问方法,估计会被打的渣渣都不剩。
以后如何做好快排
引用群里大佬的一句话:钱加技术

百度已经开了打击快排的第一枪,码迷觉得百度的打击算法很高大上,毕竟百度的猿们也不是吃素的。
这次专利虽然看起来打击的范围有限,但是从IP终端到用户的访问路径均有提及。百度这次行动,码迷觉得主要目的是黑帽、白帽SEO点击样本的搜集,要不不会存在后端人员做样本库人工标示。
等百度样本搜集完成,经小范围测试后,如果打击效果不错,再灰度扩容。意味着那个时候,如果凭有限的终端资源、不严谨的模拟参数都会被百度检测出来,如果那时候做快速排名的老师们再不做技术资源升级,真的渣渣都不剩了。
本系列首发于www.mamioo.com,同步发布于公众号”码迷SEO“,未经允许不可转载。高高低
八、SEO内参(8) 从百度网页质量评估浅析个人怎么做流量站
编者按(2023):
1、本文中提及的旅游站点本来有很好的发展前景,但是三年口罩来临,给旅游业来了个毁灭性打击。
2、这个站点的算法核心是,采集大量内容,用逗号、句号切分句子,然后剔除长度小于N的短句,再长句子拼接,过了百度飓风算法。
3、句子拼接类已经很难获得排名了,大家不要再尝试。
正文开始:
好多天前摩天楼内容助手群里有个同学问我站的问题,给了我2个旅游的站点,两个旅游站点内容模板都很像,域名都不是很好的老域名,但是基本上一个月都达到了爱站权重5。因为码迷之前主要做过文学类的流量站,没有做过行业类的。也表示非常新鲜。
今天我们结合百度网页质量评估,来跟大家一块挖一挖人家是怎么做到的。
因为毕竟是人家辛辛苦苦做大的,所以码迷做了打码处理,尊重一下人家。
码迷在《百度SEO内参》系列一直强调一个原则是通过现象看规律,通过规律看本质,通过本质讲对策。我们敬爱的毛爷爷也说过:“尘世间没有无缘无故的爱,也没有无缘无故的恨”。但凡网站腾腾腾起来了,必然有它的理由。
要么是非凡高超的SEO技巧,要么是辛勤劳苦的耕耘。
分析网站的思路
流量站码迷觉得主要分为垃圾流量站、优质流量站两种。垃圾流量站一看词基本上就看出套路来了,但是行业站因为各自行业的性质不同,挖掘手段也不尽相同。码迷一般是按照如下流程开挖。
1 看域名外链
2 到5118或者爱站查一下排名词以落地页类型
3 从网站标题找规律
4 从内容构成找规律
5 查收录率看效果
第1步 看域名外链
这里用桔子SEO工具可以查到,这个域名3年左右,不算很老。另外外链来源域名也就20个左右,外链一点也不强大。
码迷觉得奇怪啊,于是到另外一家也查了一下外链,引用域也没有超过100个。相比附子的网站,这个域名外链,基本上没有买链接的嫌疑,但是从历史锚文本来看,地域性是非常相关的,都是做重庆地区的业务。
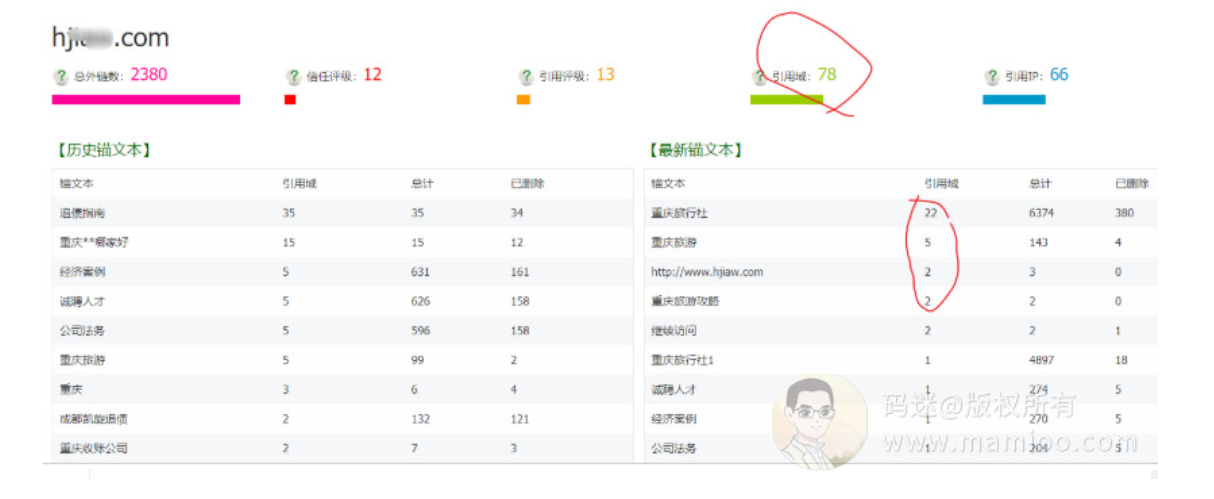
PS: 重庆是直辖市,相比北京互联网竞争小,但是人口基数远超其他直辖市,大家想一想很多SEO网站喜欢在重庆起航了吧?
结论:域名是老域名,无黑点,有地域相关性,但是外链并非很强大。中规中矩。
第2步 查排名词&落地页
我们搭配5118 或者爱站工具,可以看到这个站指数词还非常多,除了首页的落地页,基本在聚合页面上。
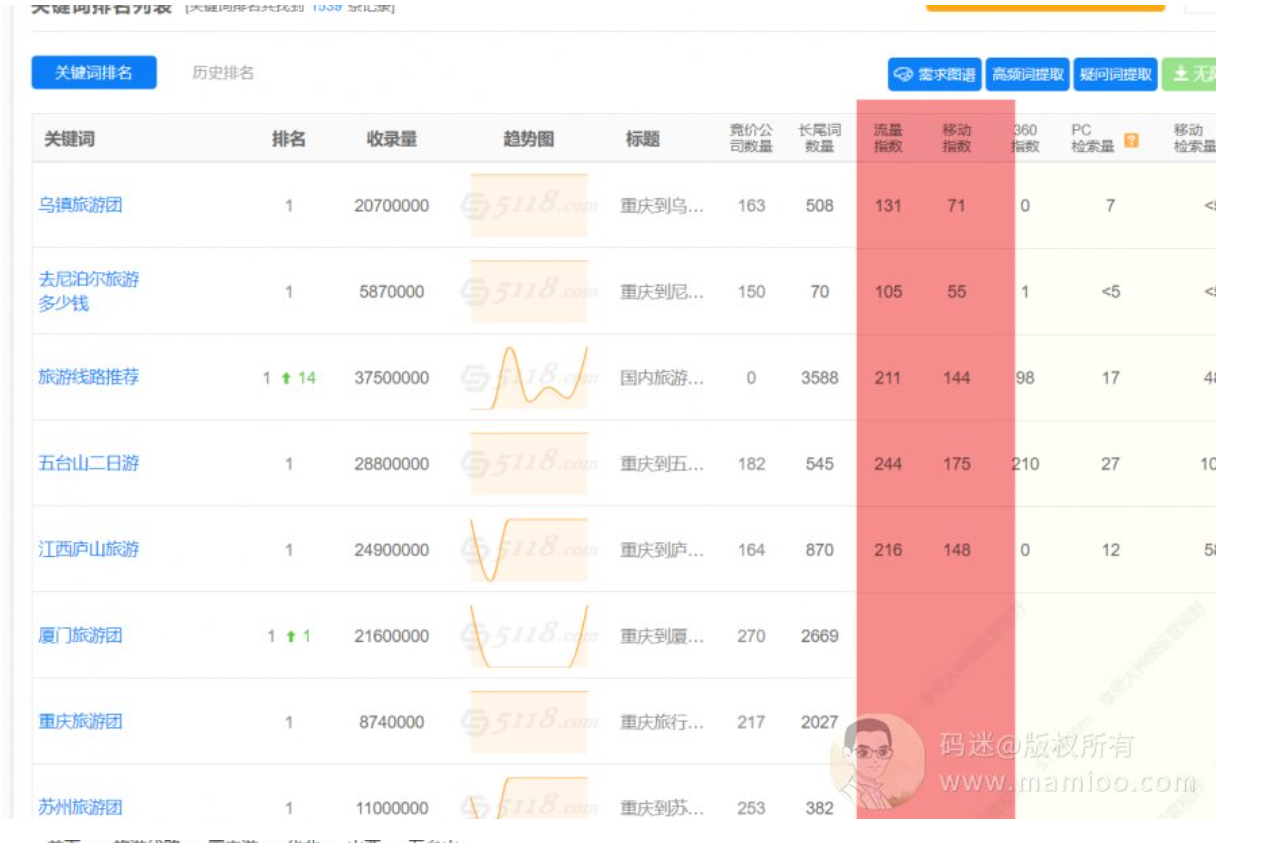
结论:网站关键词带指数的很多,说明是优质站点,落地页多为聚合页。
第3步 从网页标题找规律
我们做网站内容的时候无论是人工还是程序跑,都是先搜集标题,然后再根据标题生产内容。
那么做流量站,作为屌丝是不可能人工的,这辈子都要靠采集的。毕竟连老婆都养不起了,还养小编么。
所以基本上流量站上词都是一波又一波。
这里有个小窍门:通过谷歌查看网站最近产出了哪些内容
因为谷歌比起垃圾度娘,收录不仅及时而且收录率要高很多。
最近一个月没发新页面了,怪不得上升曲线有点疲软~
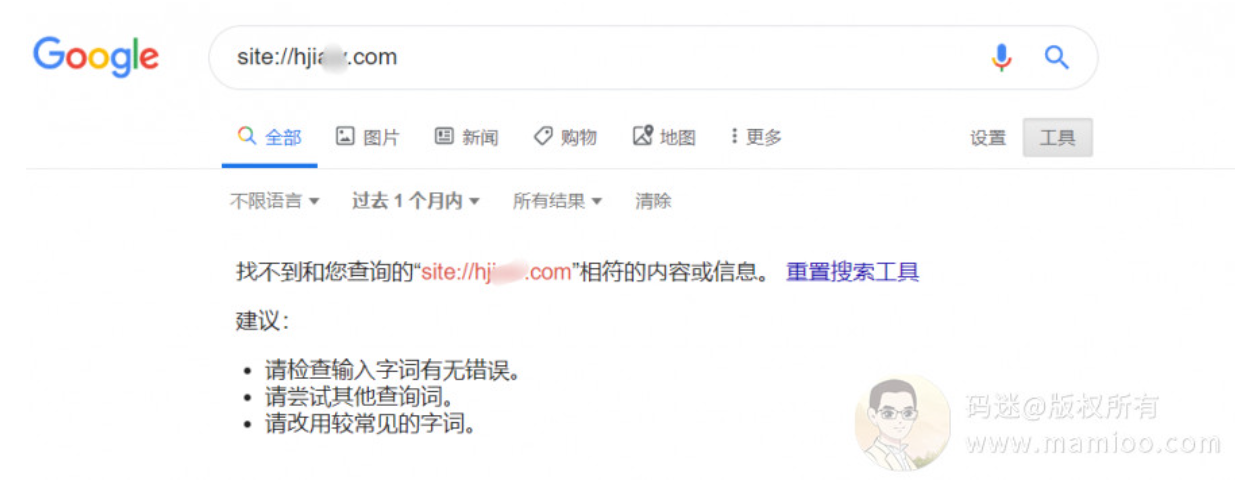
那查查最近2个月的吧,哦~,还真有新内容,我们可以通过标题看出来,主要有两类标题,一种是“要多少钱”,另外一种是“什么好玩的地方”
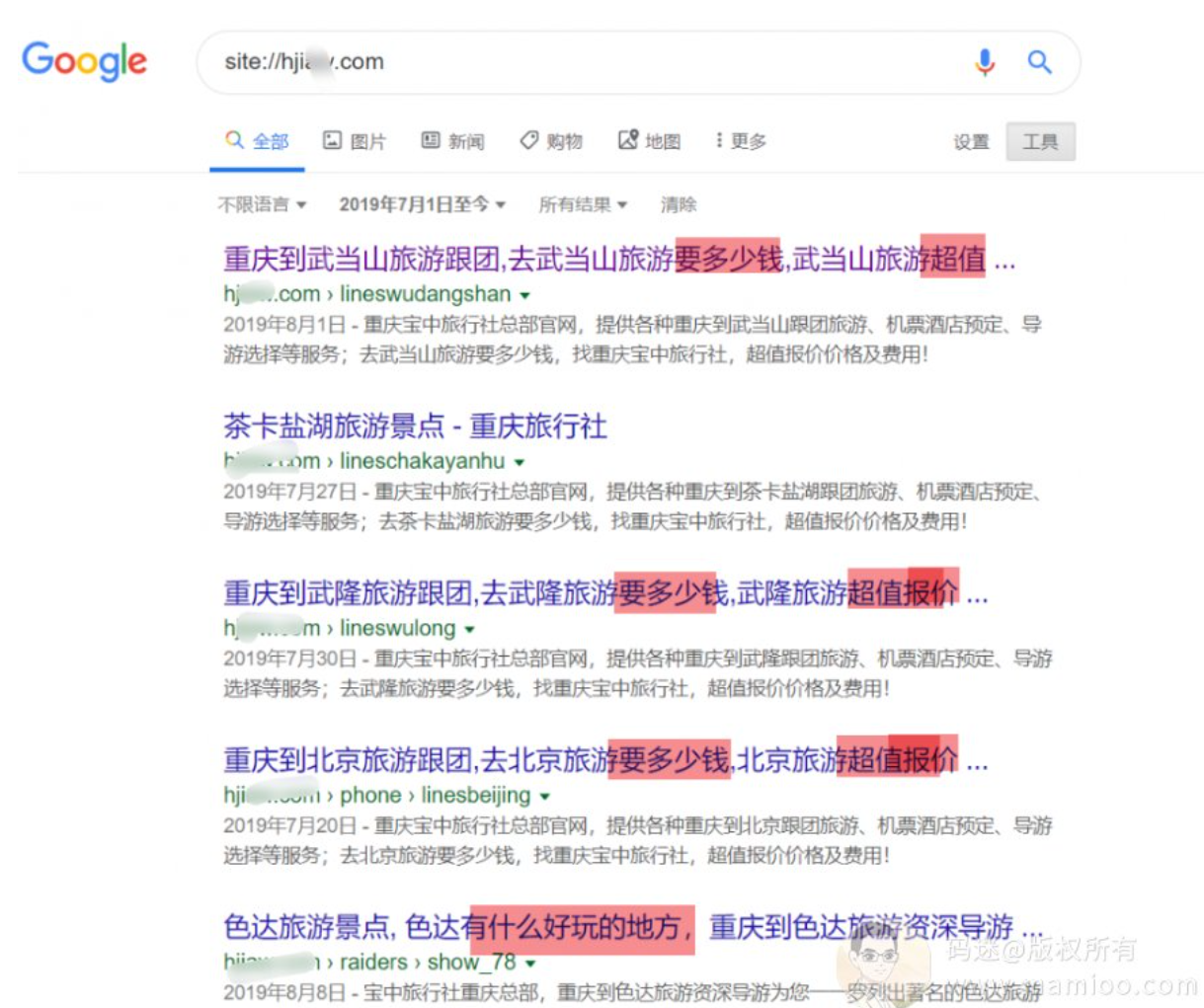
“要多少钱” 类关键词对应的是聚合列表页,那么另外一个词有多少内容。
“什么好玩的地方” 内容不多,只有48条,再继续挖。
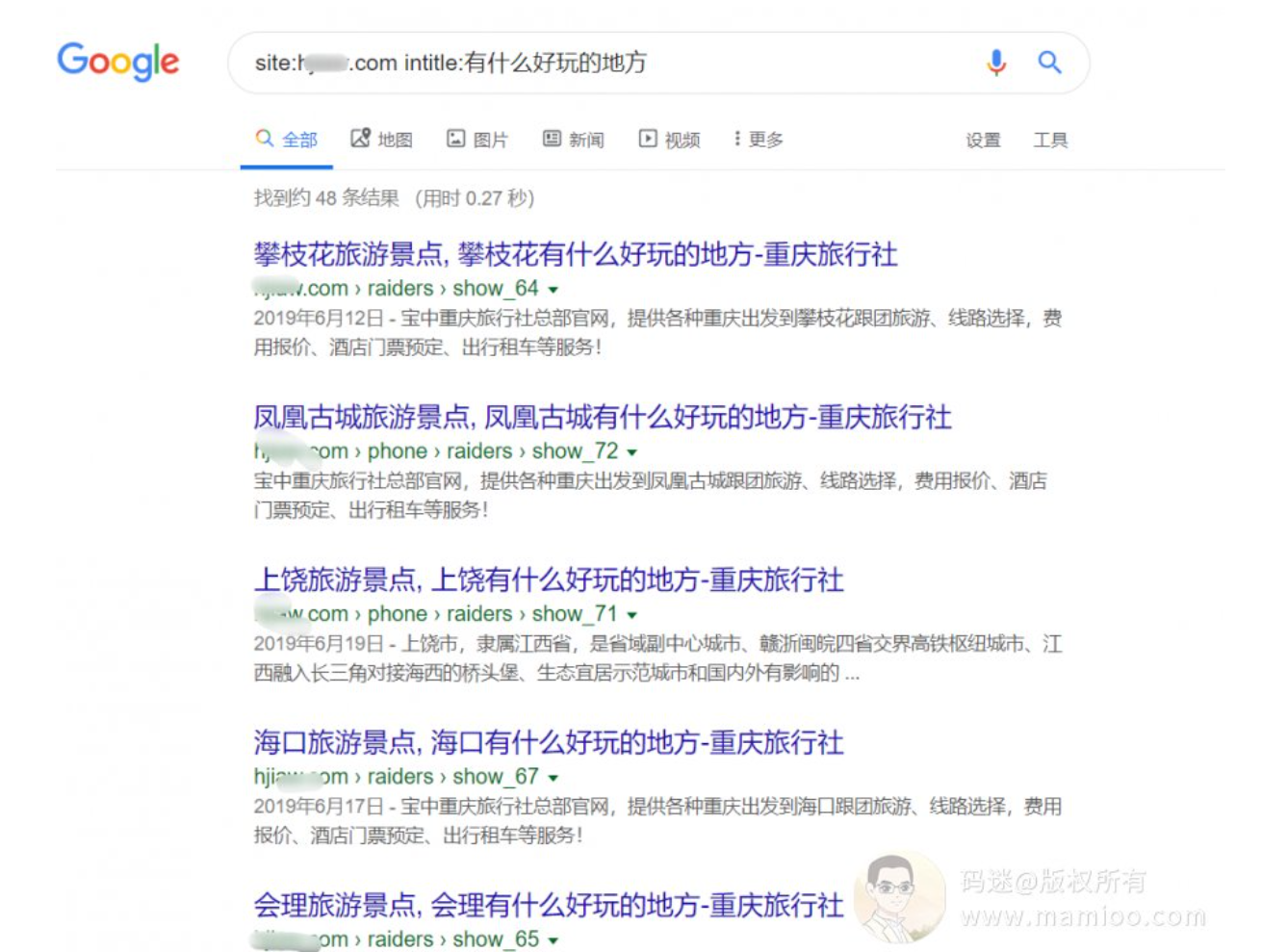
“旅游线路” 的内容不少,1700多条
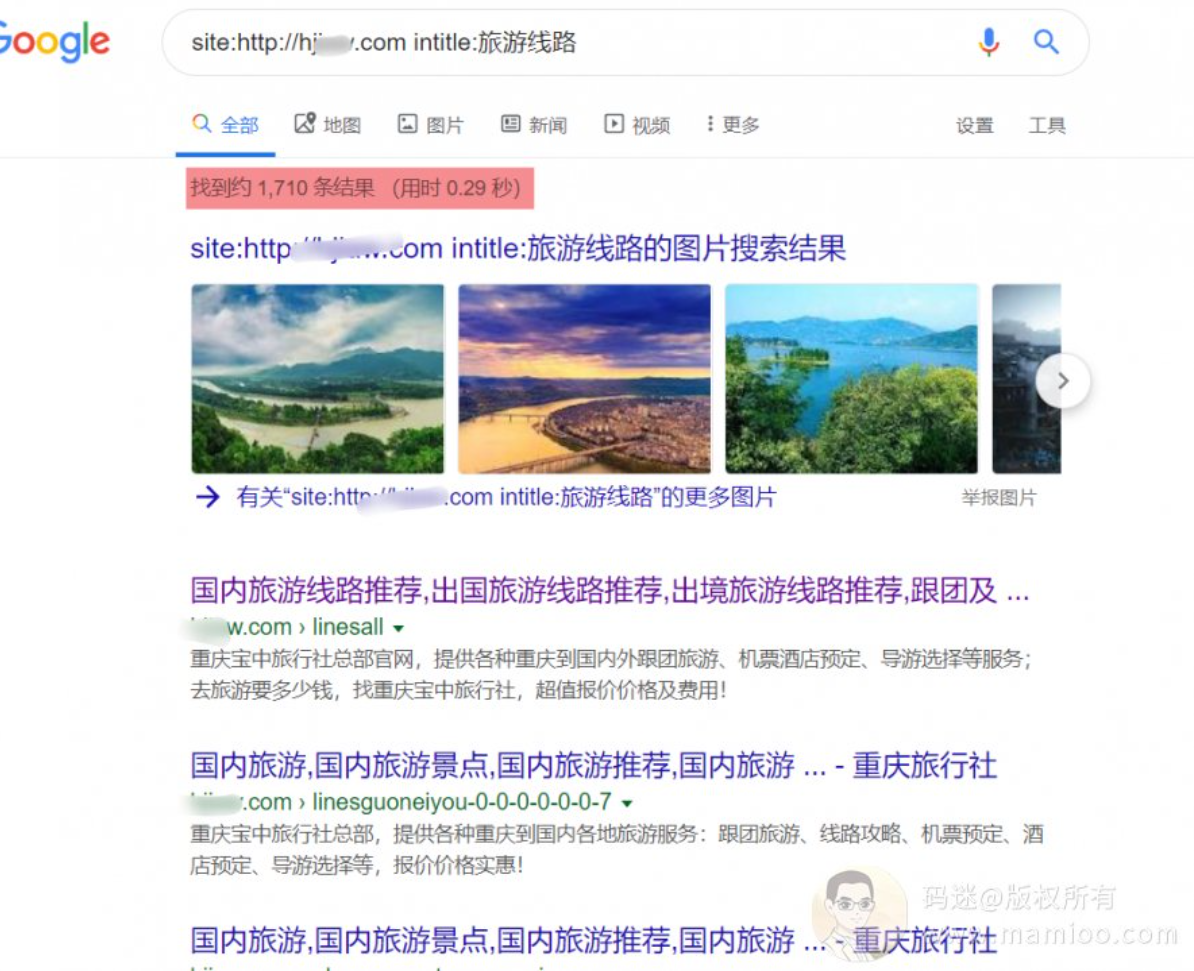
”跟团线路,费用报价“的也不少,400来条。
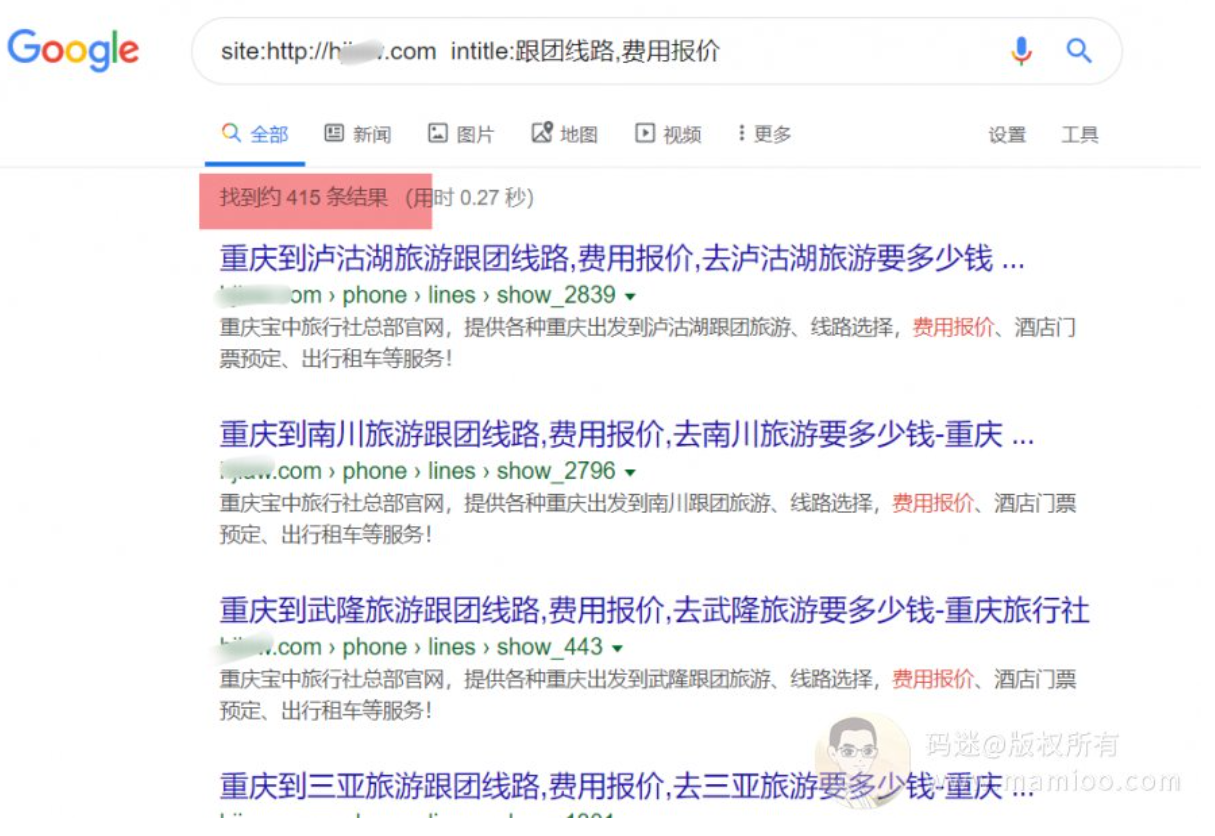
就挖这么多,我迫不及待的看标题是怎么来的了。
结论:标题应该由{地区}+{固定词根}批量生成的
4 从内容构成找规律
“什么好玩的地方”类
拿一篇举例子,我们用google搜段落飘红出处。务必不要用不争气的度娘,因为度娘根本就判断不出谁是原创。
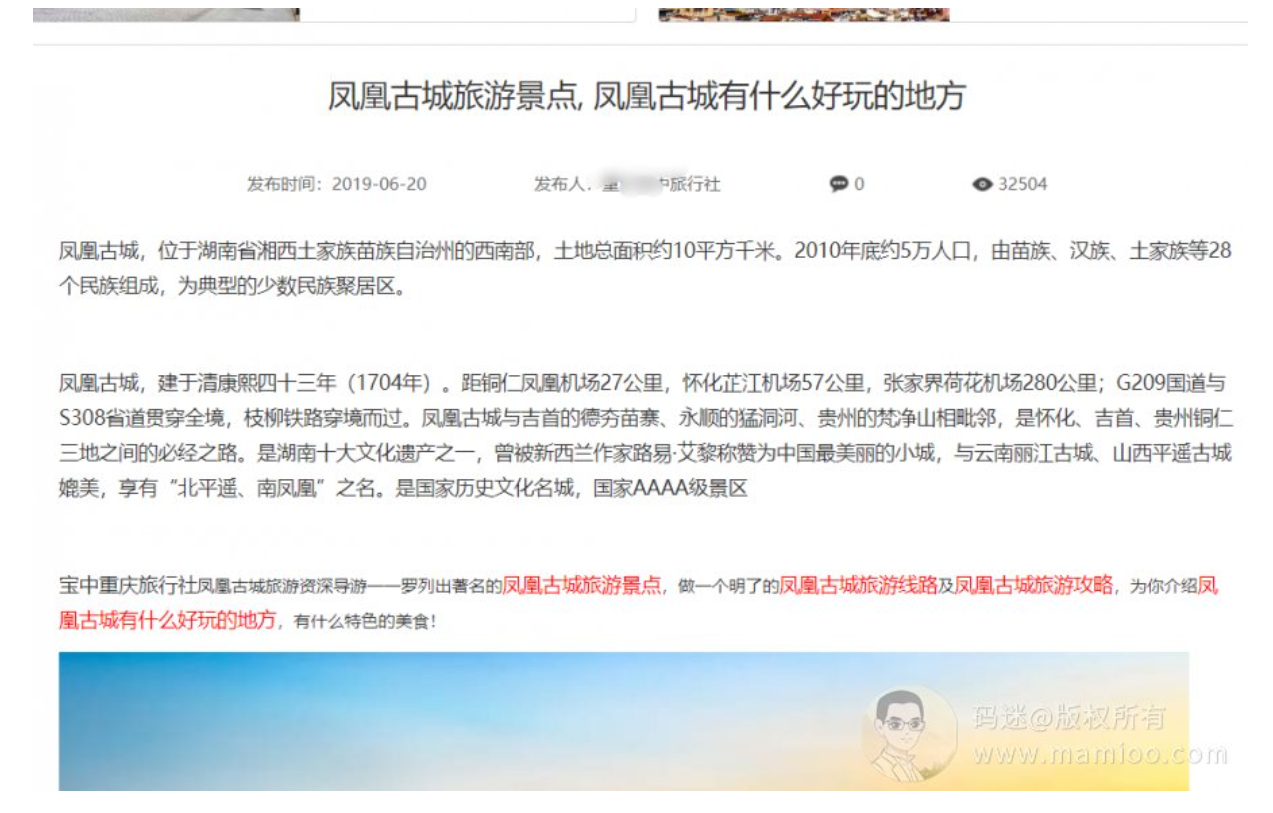
我们发现,这篇文章各个段落都来源于百度百科、新浪、携程等5个以上网站,采集组合而来。
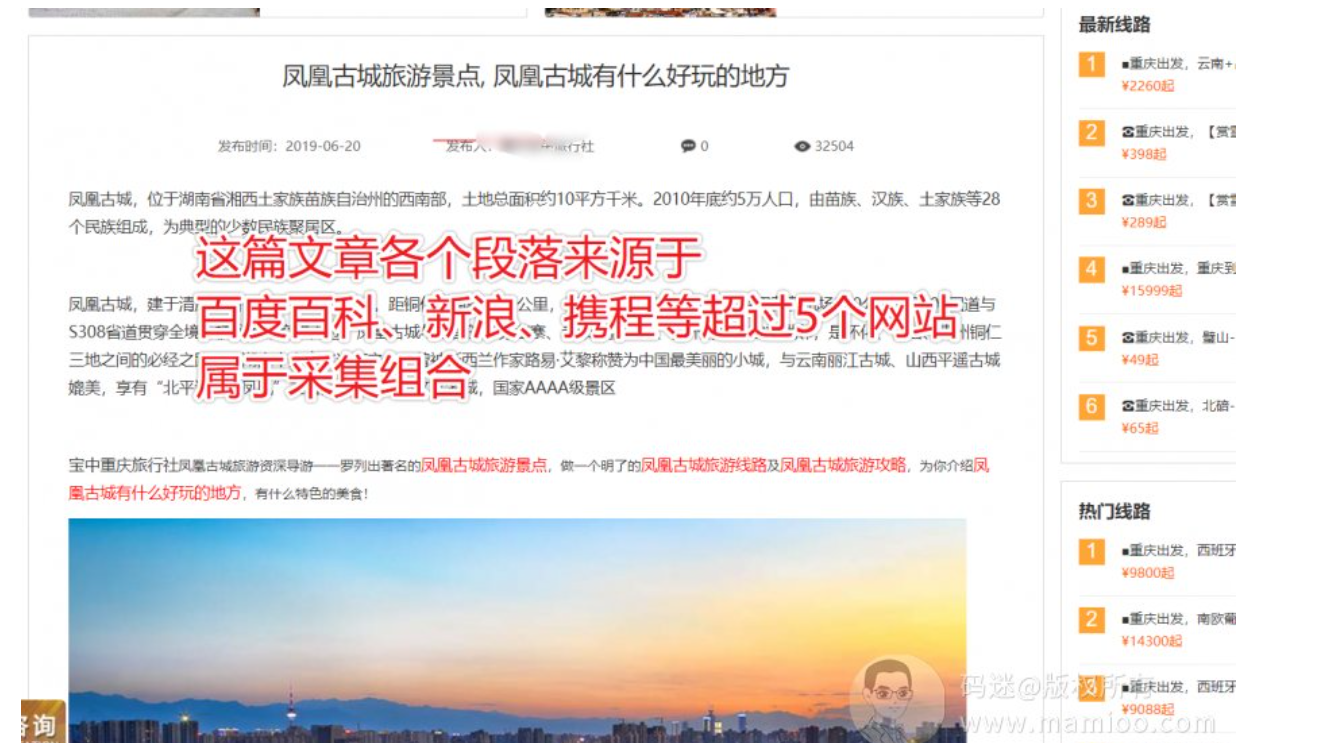
再找一篇“旅游线路”的文章,大体看了看,一个德行。但是细看,其实下面的文章把平利县旅游景点中的天书峡景区,平利县龙头旅游村,千家坪,八仙悟真观等都做了介绍,所以内容也不是胡乱采集拼凑的哦。

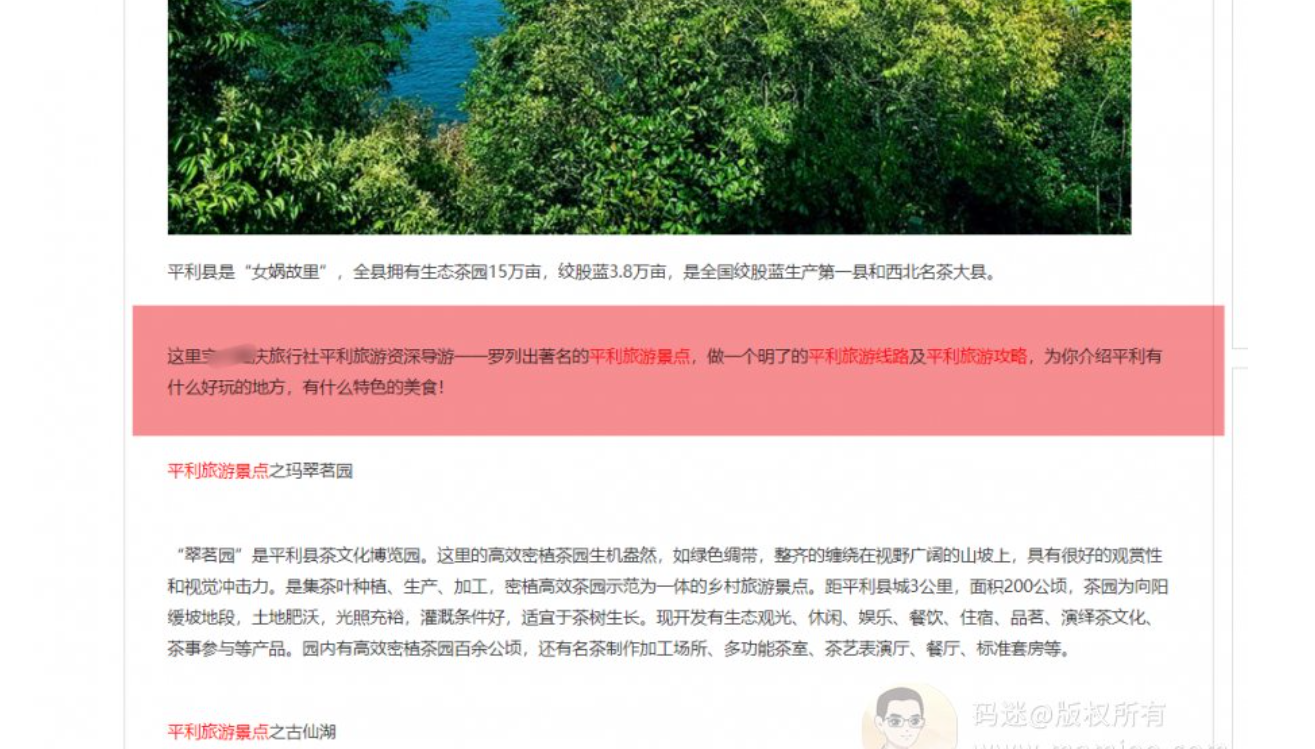
再仔细看,下图红色区域,每篇文章都有这一段,将标题里面的关键词包含,并且生成内链。
总结:
1 单篇内容来源于5个以上网站数据
2 为保证内容相关性、稀缺性,内容由{地区}+{所属景点}扩充而来
3 为保证标题内容相关,内容均插入固定格式的一段话。
4 构建内链为聚合页引流加权
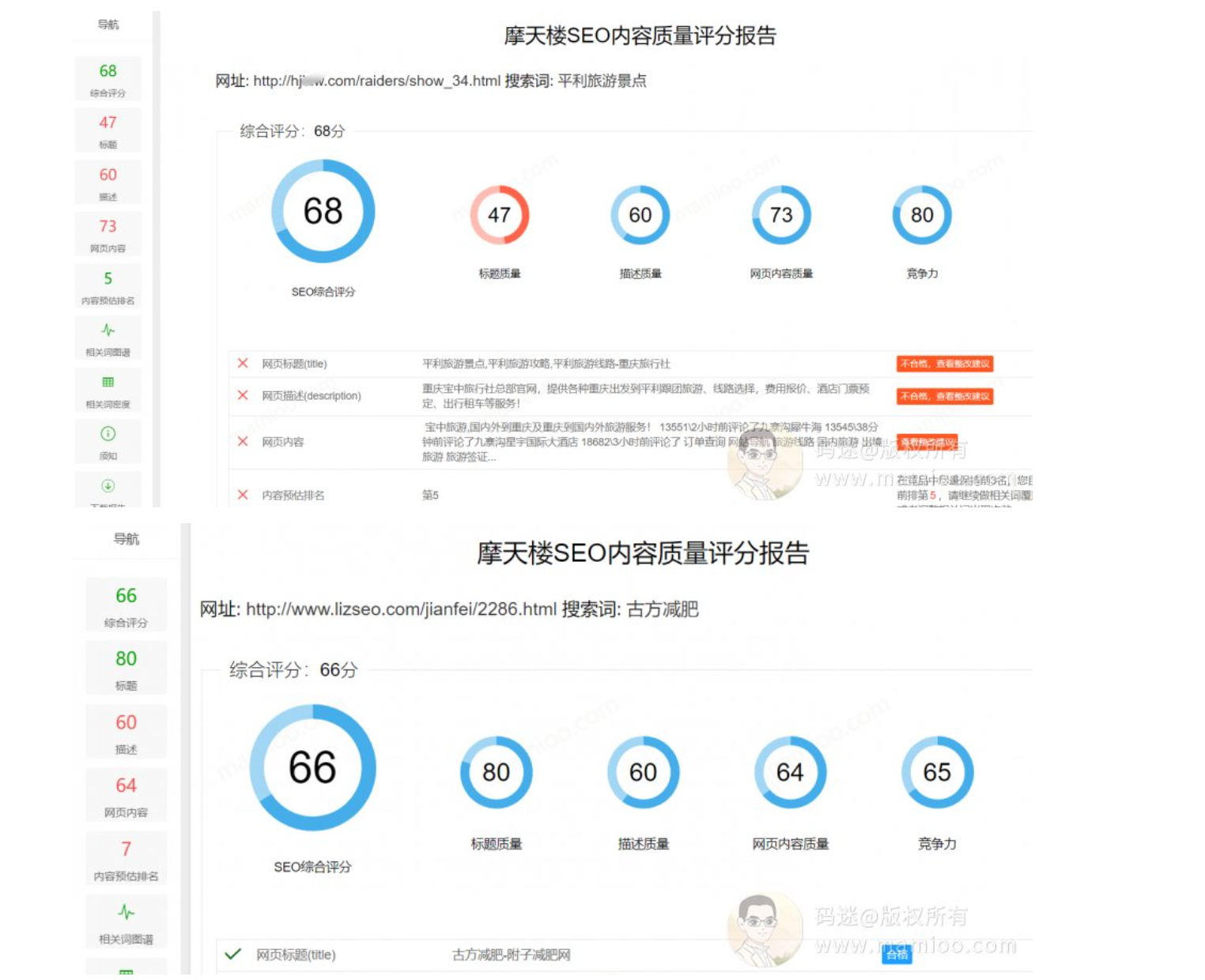
简单给几个流量站的内容页面用摩天楼内容助手做了打分,基本上都在60分以上。
好啦,码迷觉得刨的差不多了,大家也应该差不多了解一点流量站的套路了。码迷在上一节中《SEO内参(七) 从百度专利看百度对网页质量的评估方法(中)》提到,百度评判网页质量包括域名、内容稀缺性、 用户体验、图文丰富度、内容相关性等等。
大家从这5个维度分析一下这个网站,是不是每一方面都尽力了,他们是怎么尽力的?
现在做流量站除了要完善内容之外,还要配合快排做整站提权,这个码迷《百度资源分配策略解析》中,已经说过了。这里不会去总结流量站具体的做法,毕竟培训老师们更专业一些,但是中心思想是不变的。就是让百度看来,我的网站即使是采集,也是对用户有价值的内容。
最后1步 查收录率
用百度谷歌对比一下收录条数就能预估个大体的范围,25%左右,不是很高。
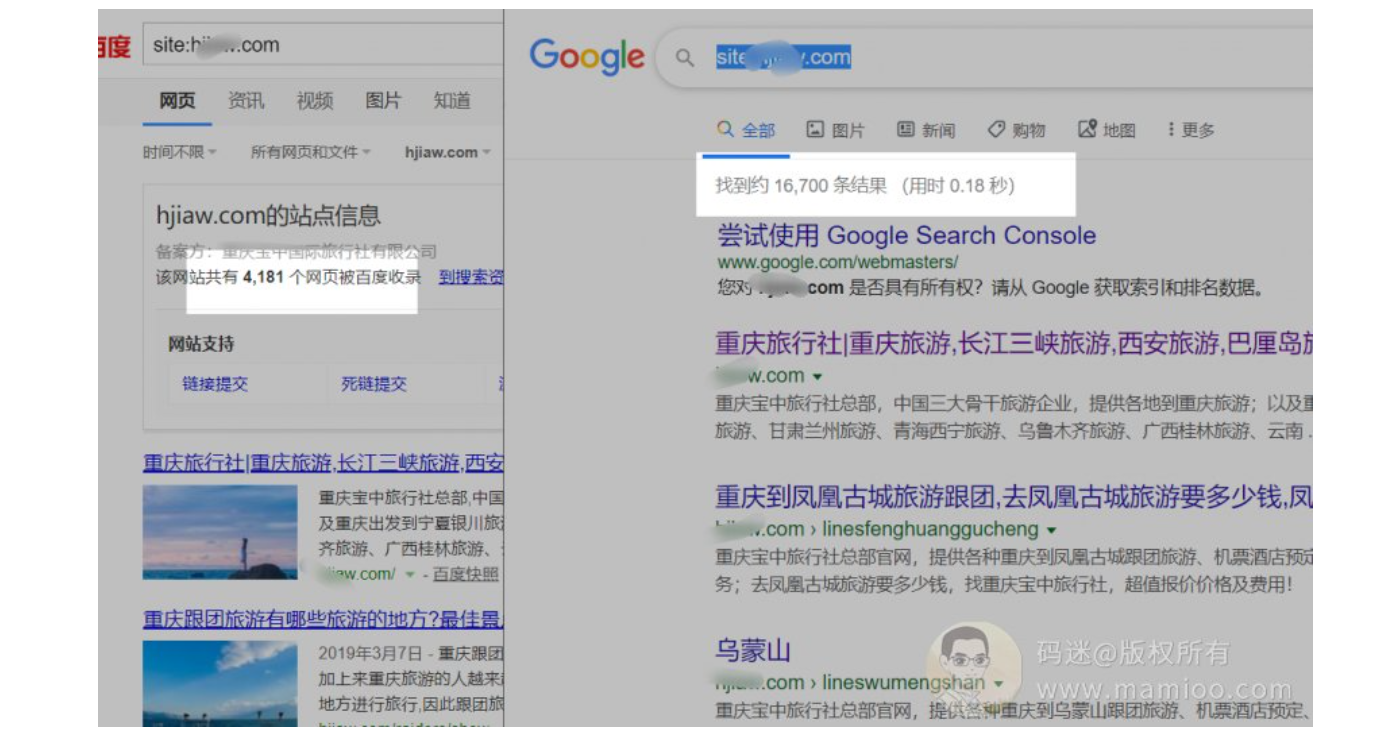
我们可以看到,这个网站最大的问题就是采集,否则收录率不会这么低。那么如何做采集才能绕过百度去重检测,这是我们接下来讨论的话题了。接下来,码迷将给大家带来《深入百度的网页原创性识别方法》系列。
九、SEO内参(9) 飓风算法3.0的前世今生及AI伪原创工具评测
编者按(2023):
既然已经有了ChatGpt来生成原创内容,那就不要用采集了。
ChatGpt也可以用来搞伪原创,比如"请用口语化的语调复述一下内容:"。
正文开始:
自从8月底飓风算法3.0上线之后,仅仅过了20天,也就是2019年9月18号,百度就发布了一则搜索违规处理情况通告,其中处理掉528万个恶劣采集网站。相信很多站长是欲哭无泪。
中国这个大环境就是浮躁,很多做SEO的都喜欢吃快餐。火车头、DEDECMS采集程序大行其道,伪原创工具也搞的有模有样。但是飓风3.0之后,如果不改变采集方式,当真是越采集死得越快哦!
很多站长没有意识到事情的严重性,一些有智慧的人(SHA)(HAI)(ZI)还有模有样的搞纯采集,某些牛掰站长信誓旦旦的跟码迷说,老子的站照样收录没问题,老子的算法能过百度原创检测,老子有伪原创工具很牛逼。你也不看看你站收录的是有500w,但有排名的指数词有几个?一周内收录还有几个呢?

采集站下去,原创站上来
你的采集站下去了,人家做原创的上来了,码迷有个合作的站点Duang的一下子涨了一倍的词库,窝草,幸福来得那么忽然,哈哈哈哈嗝。
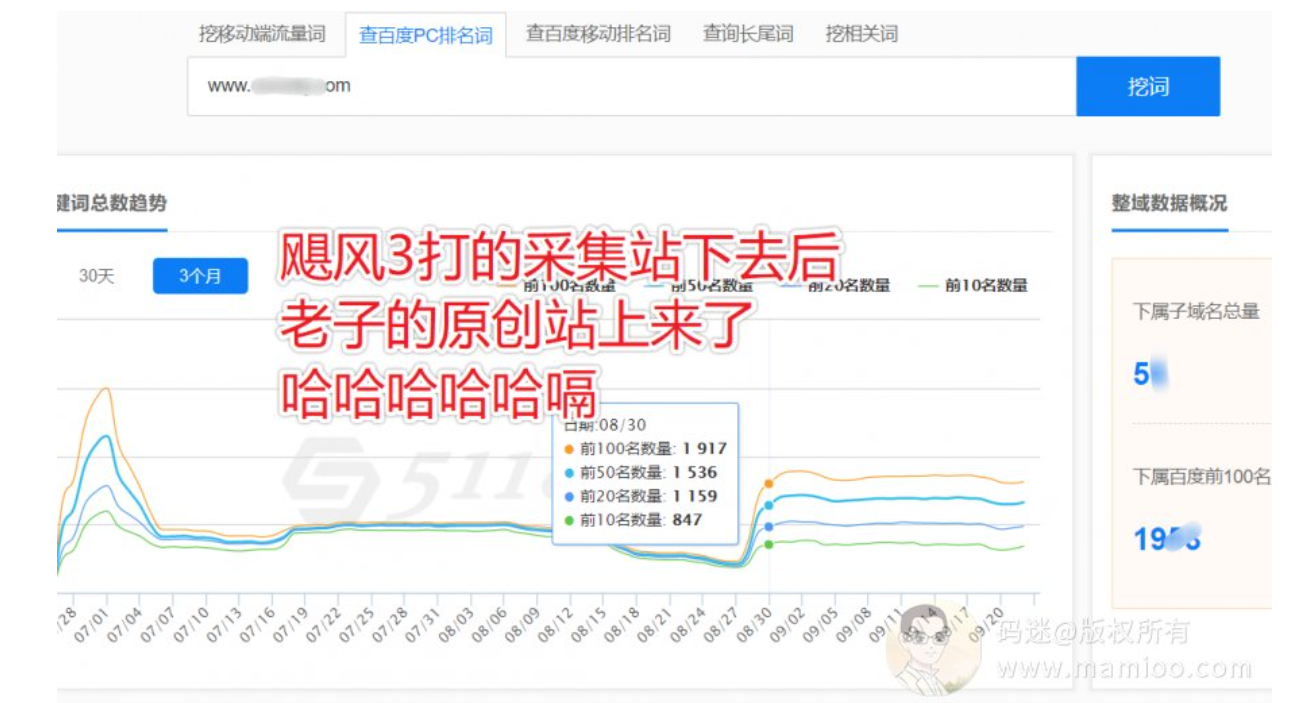
百度好歹也是养着一群985、211的程序猿,虽然大搜的那帮人算法垃圾,但经过百度的三代原创检测系统的升级,绝大多数伪原创手段到目前都已经没有了效果。但不等于就没法做采集了,也不等于没法做伪原创哦。码迷觉得飓风算法3.0也没有那么高深,道高一尺,魔高一丈哦。
某些采集站仍然有排名
同样是采集,同样是伪原创,有的人发100篇,被百度干100次。而有的人发100篇,都能进入百度重要索引,而且指数词都有了。
比如下图这个案例,采集加工也是优质内容,而且是首页排名哦。
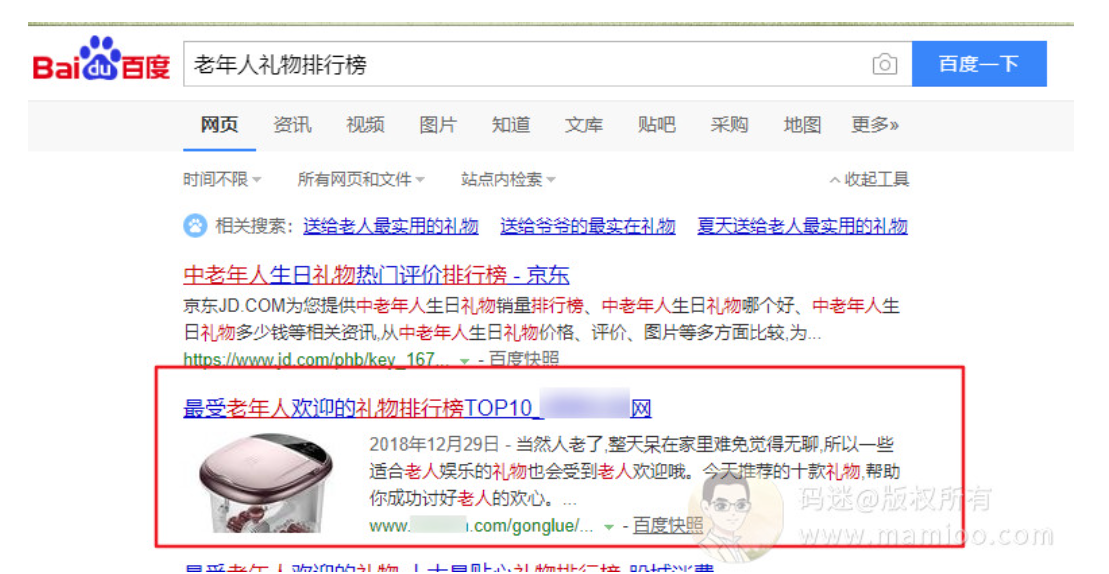
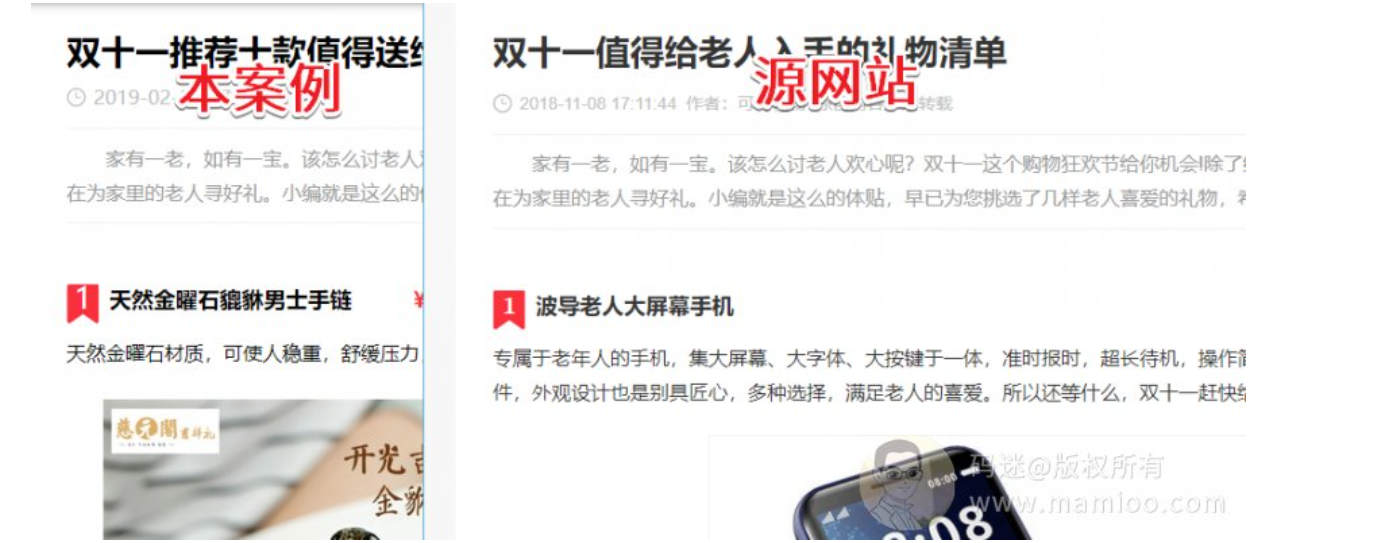
今天我讲为什么你通过采集发的文章没有排名,没有收录,甚至被K站。有些大神认为是运气,哈哈哈哈嗝。很多人不知道所以然,往往是因为自己根本就不知道百度飓风是什么玩意。
已知无用的伪原创手段
《SEO实战密码》 中总结了6种内容作弊手段,这些都已经被百度识别了。无论是同义词替换还是简单在原来文章上做更改,都已经没有收录的几率。其中已经没有用的伪原创手段包括如下:
1 更改(完全重写)标题
2 颠倒段落次序
2 加一段原创,如在最前面加一段内容摘要
3 文字简单增减,如感叹词、修饰词
4 同义词近义词替换
5 强行插入关键词,如在一篇小说中强行插入关键词
如果说作为黑帽SEO高手的你还用以上这些手段,放下屠刀立地成佛吧,该干啥的干啥去,别浪费时间。
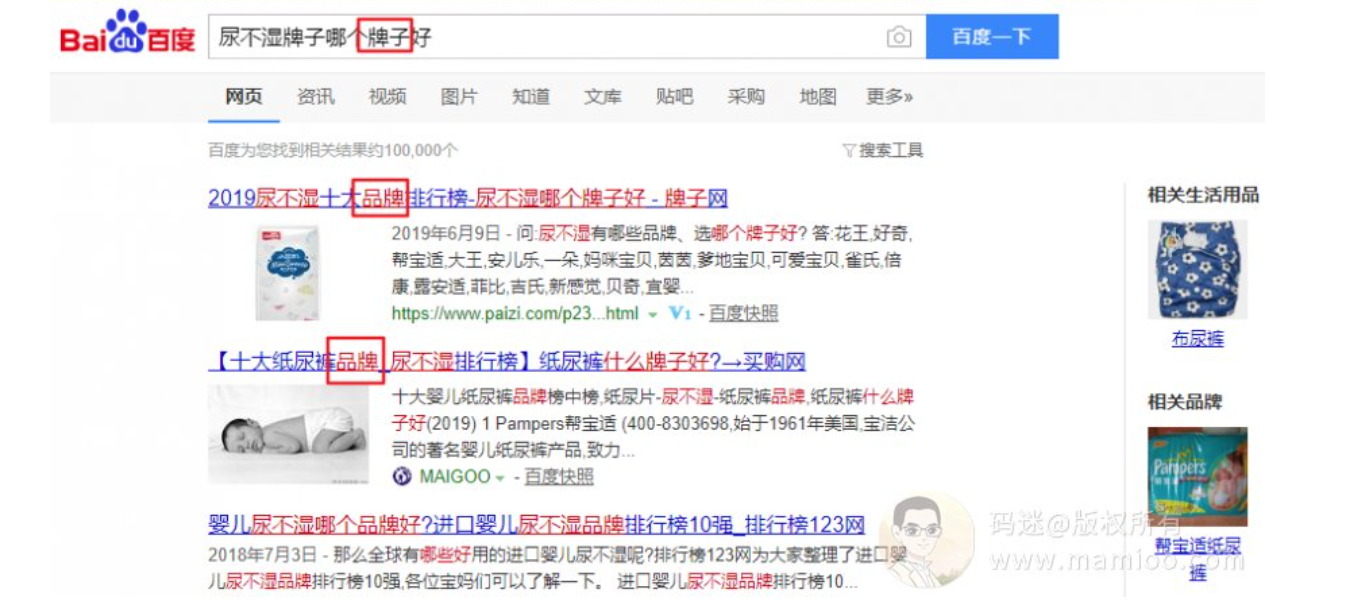
为什么同义词替换没有用?
这块百度已经说了百度有自己的同义词库了,还有人做伪原创光用同义词替换,尤其是某个站长工具站也推出了同义词替换工具,名曰智能伪原创。智能个毛啊,你比百度智能??
比如你再百度搜索xx牌子好的时候,品牌也会飘红。
AI伪原创
本来不敢写AI伪原创方面的评测,害怕会得罪某些人,但是码迷找了几个圈子里面用伪原创的站长,反馈飓风3上线后,收录是一天不如一天,比如今天发1000篇伪原创文章,下午就剩下收录500篇,明天收录收录不到100篇,90%以上伪原创内容的都被百度识别掉了。
如下图左边是原文,右边是AI伪原创的结果,可以看到无论是句子顺序还是很多词语,都发生了变化。基本每个句子都不是相同的。最近很多人都热推AI伪原创,认为可以通过百度收录,可以取得排名。
嗯嗯嗯AI伪原创好屌,专注于采集的老王站长觉得自己已经打通了筋骨脉络,终于可以大干一场了。

然后码迷直接问了做智能伪原创的卖家有没有过百度的案例,然后被他喷了,被他喷了。。。“我欠你的吗”?
江湖上流传的SEO指纹算法
码迷偶尔看到《某某SEO:搜索引擎是如何识别内容原创的?独家揭秘SEO指纹算法!》,感觉很有道理的样子,出处在哪里?如果是自己编的,这里省略100字。
百度3代伪原创识别系统
SEO高手跟小白的区别是什么?就是知其然知其所以然。码迷见过太多自以为牛逼的站长被自己打脸了,这还没有轮到百度打脸。不知道原理就开始瞎搞,有个毛线效果。来吧,跟码迷一块深入飓风算法吧。
第1代百度原创识别手段:
根据《CN201110031636-一种网页重复的判断系统及其判断方法》专利,这是2011年左右的老专利了,可以说是百度第一代伪原创识别系统。主要手段是通过对网页结构化数据做simhash。

通过这种识别手段,采集来连标题都不改正,正文也不修改的,基本没戏了。
主要步骤如下:
在本实施例中,进行网页重复的判断时,如果两个网页满足下面任意一项,则认为这两个网页是真重复 :
1、两个网页的真实标题签名相同。
2、两个网页的网页内容签名相同。
3、两个网页的网页正文签名的不同位数小于 6。
4、两个网页的网页位置签名相同,并且 url 文件名签名相同。
5、评论块签名、资源签名、标签标题签名、摘要签名、url 文件名签名中有三个签名相同。
缺点:
这个算法要对网页五个维度走签名计算,码迷觉得这个算法计算量太多了,估计百度试用了一段时间就放弃了。
另外修改一个字签名就不一样了,很容易破。
第2代百度原创识别手段:
很多人说“baidu就是个垃圾”,码迷觉得很有道理。码迷说了第一代计算量太大了,耗费钱啊,毕竟竞价排名才挣钱呀,自然排名搞这么高大上的去重算法干啥,艳红不喜欢。那怎么找个最简单的办法去重?
百度程序猿如是说:
咱们从整个网页中,提取出一个最长句子,根据提取出的最长句子的签名进行分组,同组内根据title的皮尔逊距离(计算网页内容的相似度)和链接发现时间进行原创性网页的识别,即判断同组内谁是真正的原创。

优点:
该原创度识别方法码迷推测应该存在了很长很长时间,这种方法优点计算量小小的哦。
缺点(硬伤啊):
仅仅通过最长句子作为依据,误判率相当高。
第3代百度原创识别手段:
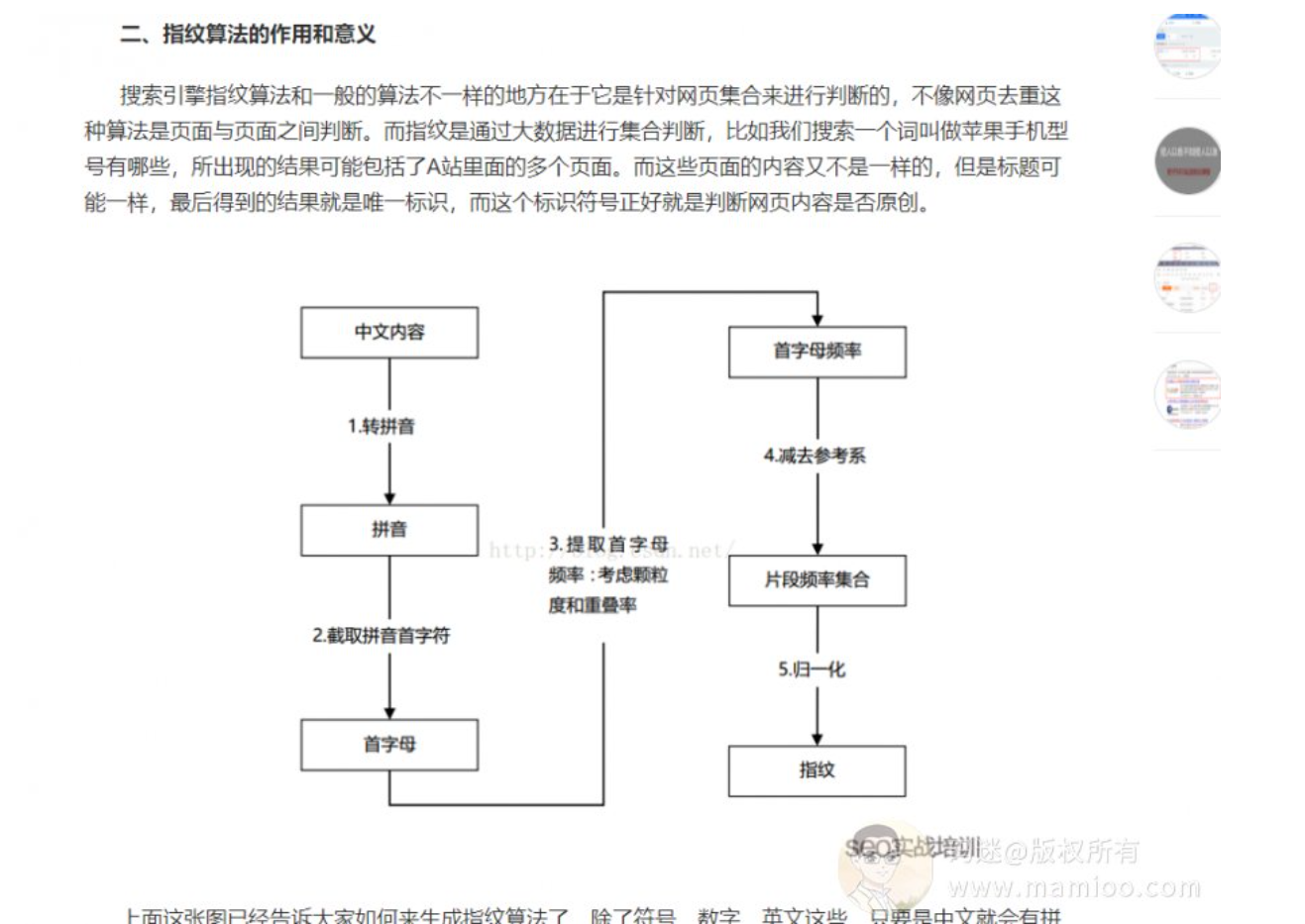
因为第二代的手段效果很不好,所以百度终于推出了飓风算法( 2017年7月7日上线),而对应的专利在2017年3月底提出的申请,那么时间点也比较吻合。基本思想是对句子使用simhash算法做签名,然后用汉明距离做原创度检测。

什么是同义词级别simhash
看不懂没关系,先了解simhash算法一点皮毛,码迷简单举一个例子,一图胜千言。
如果您是算法专家,可以访问传送门:github.com了解simhash算法。
AI伪原创能过百度原创吗?
基础假设
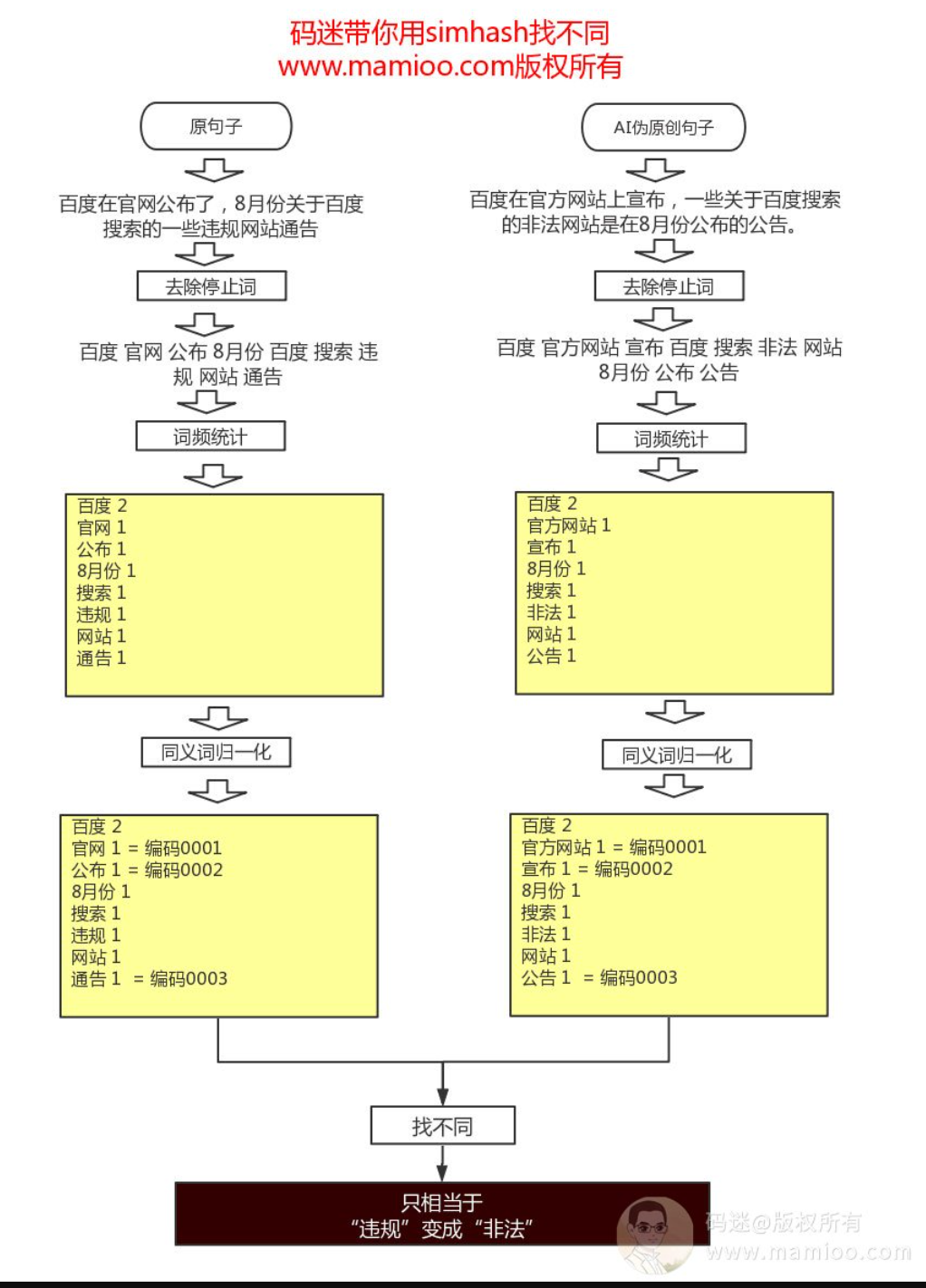
那么回到AI原创的问题,因为百度飓风3.0按照句子级别的simhash进行去重,我们假设:
前置条件1:对句子长度为100个字,进行伪原创
前置条件2:把句子的签名做对比,伪原创后编辑距离位数小于10,并且汉明距离小于10,并且汉明相似度大于80%
判定结果:抄袭
百度内部肯定有自己的汉明距离临界值,100个字符的句子已经是很长句子了,实际中百度的汉明距离临界值应该更小,我们上面假设中的已经相当宽泛了。
不了解编辑距离,汉明距离(也叫海明距离)的可以看
百度百科《编辑距离》:baike.baidu.com
百度百科《海明距离》:baike.baidu.com
你不会编程没事,码迷会。码迷有现成的分词方法,也有停止词过滤程序,直接用github上的程序。
参考:github.com
码迷随便找了一篇网易的文章,做一下simhash的编辑距离跟汉明距离。
AI伪原创工具评测1:
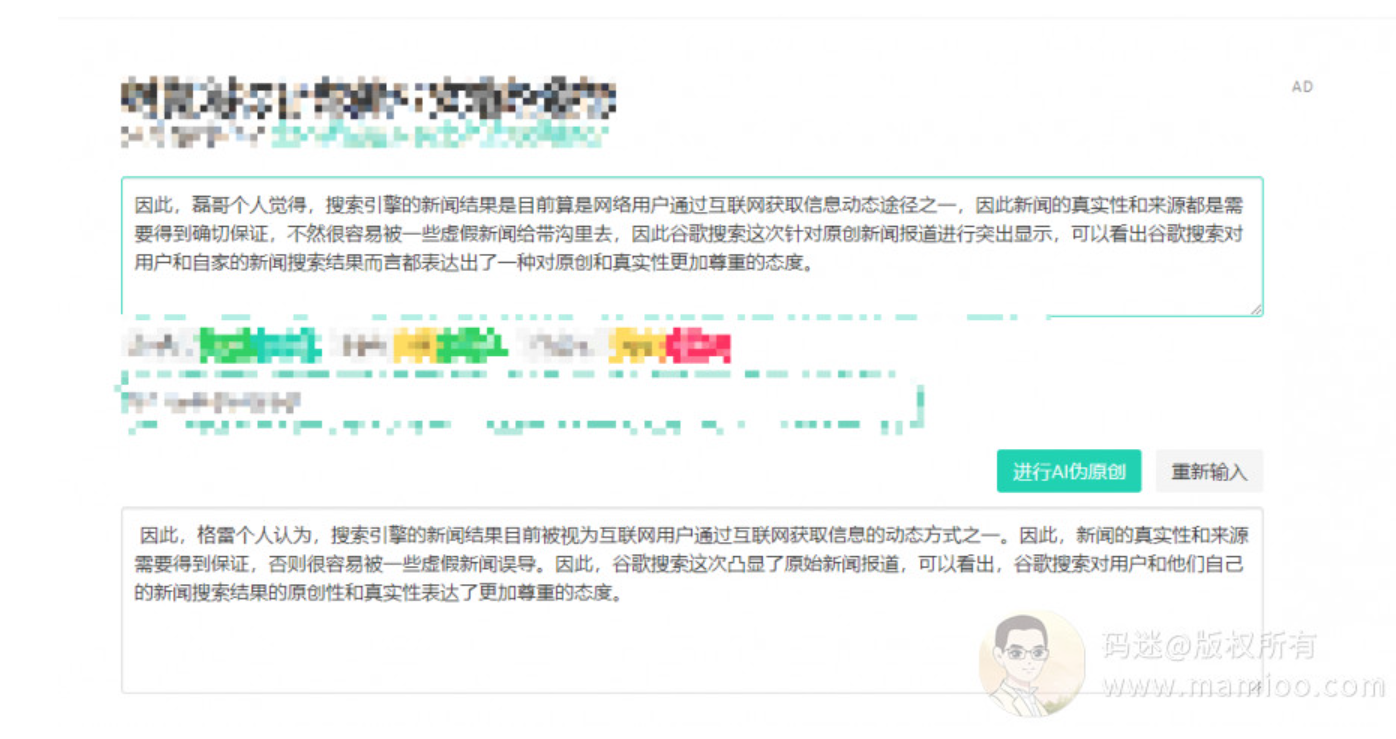
最终结果:
没有过假设的百度原创关,编辑距离为6,海明距离为8,相似度高达87.5%
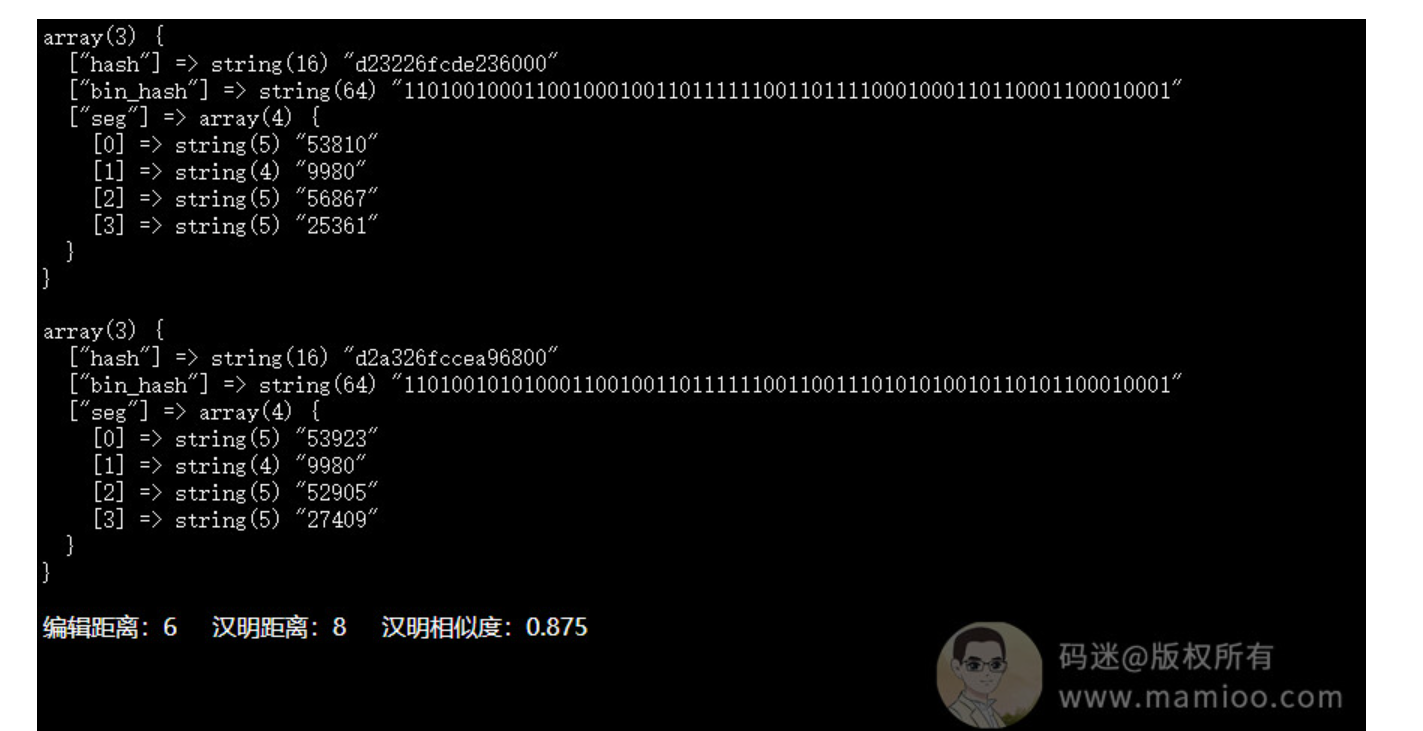
AI伪原创工具评测2:
码迷不死心,又要了另外一家AI伪原创:
最终结果:
没有过假设的百度原创关,编辑距离为7,海明距离为10,相似度高达84.3%
AI伪原创工具评测3:
码迷还是不死心,又要了另外一家AI伪原创:
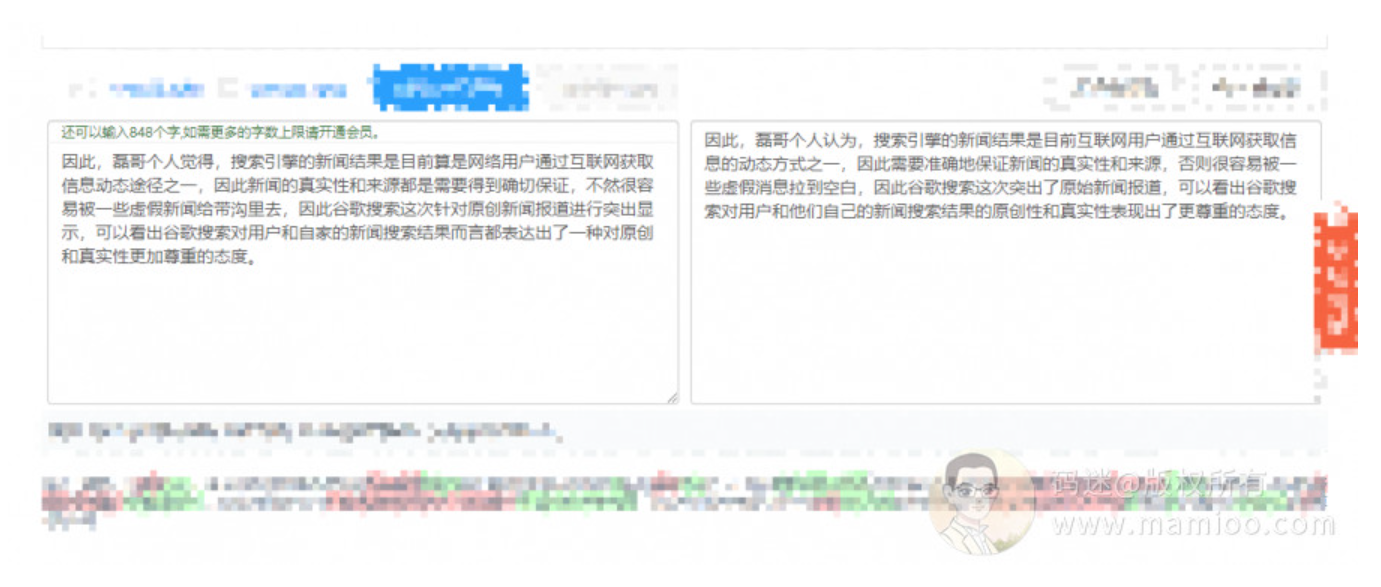
最终结果:
他xx的什么破AI伪原创,编辑距离只有4,海明距离为6,相似度高达90%!被百度干的渣渣都不剩,别误人子弟好不好?
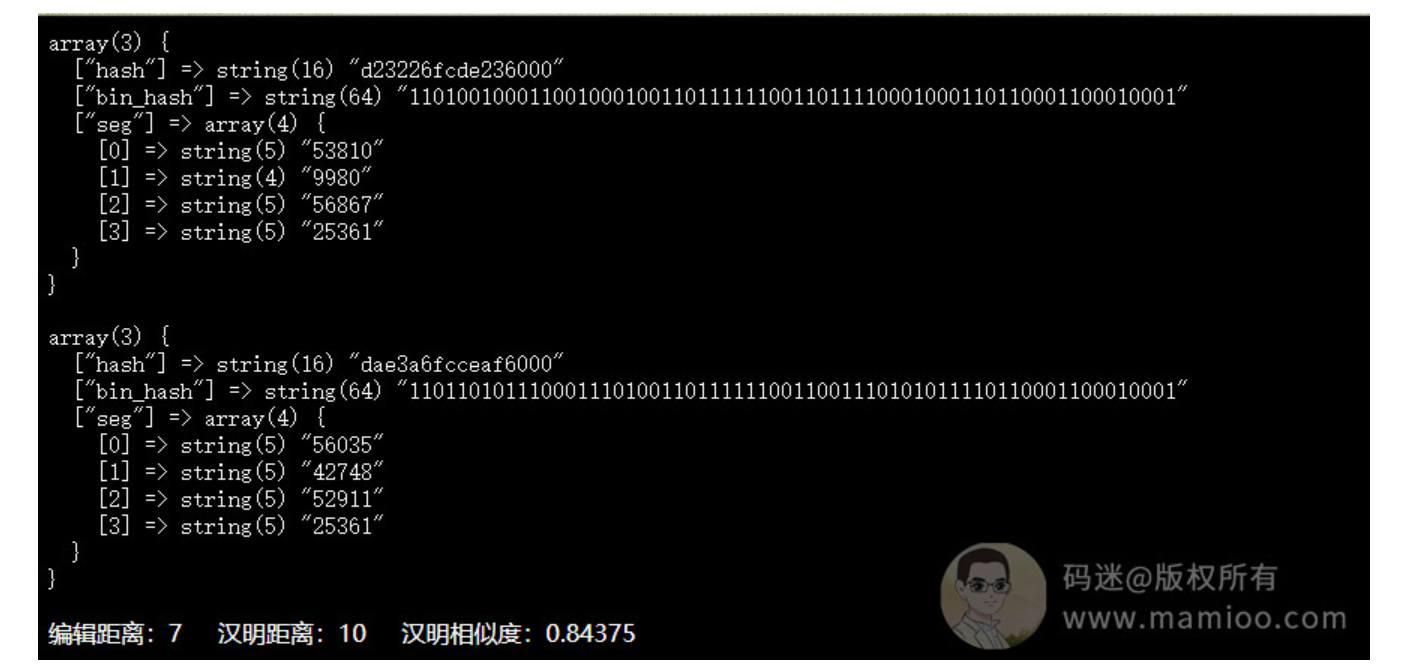
结论
首先、直接伪原创不容易过百度原创
人家百度几千号人来做开发呢,就凭一个伪原创就能过了百度检测吗?所以大家千万不要直接采集人家的内容,稍微伪原创就发到自己网站上了,这就是作死。
其次、同义词替换语句颠倒没毛用
某些网站声称几十万的同义词近义词词库,码迷告诉大家,百度为了压缩索引,同义词词库可比你们任何词库都丰富的多,人家的同义词库还是分词性的。另外语句颠倒不会影响simhash算法结果哦。
如何做采集过原创
但是人家有些人靠采集就能做出排名了,这是为什么?有些人靠采集组合也能有排名,即使不用上伪原创就能上百度排名。码迷一个合作伙伴网站,还没起来就被飓风算法打的渣渣都不剩了,但是经过码迷研究,让其更新采集组合算法之后,又恢复了往日的精彩~
十、SEO内参(10) 独家相关性提权法原理以及SEO文章质量提升方法
大家好,我是码迷,我是摩天楼内容助手的作者,今天跟大家分享如何写SEO文章打造优质内容质量,如何打造一个秒排布局的方法,这个方法就是“相关性提权法”。这也是摩天楼内容助手的核心所在。
我们知道,网站内容是SEO基础,百度判断网页内容的好坏,衡量的标准是看搜索结果有没有满足用户的需求,这里百度官方文档里面也说了2个层次来判断网页内容质量。
层次1:需求满足程度
网页内容中是否提供了用户想找的信息,比如用户搜“刘德华老婆”的时候,如果你的网页里面没有“朱丽倩”,那么你就没有满足用户需求。即使你网页内容重复了800遍“刘德华老婆”,也没有任何卵用。

层次2:答案获取成本
还是上面“刘德华老婆”的例子,网页第一段就包括“朱丽倩”,跟 网页最后一段才包含“朱丽倩”,是完全不一样的答案获取成本。百度会根据答案文本距离去判断用户获取信息的成本,所以说好的关键词布局,不仅在于密度,位置也很重要。

那么,现在我们站在度娘角度想,百度如何去判断你的网页是否满足了用户需求?到底满足了多少?满足了用户需求的页面获取答案的成本又有多少?
这些东西我们可以通过百度专利《CN103699625A-基于关键词进行检索的方法及装置-公开》《CN108121741A-网站质量评估方法及装置-公开》等专利,以及前些日子流传出来的《百度相关性评估培训:主题匹配度打分》《百度相关性评估培训资料:基础篇》中找到答案。这些资料都可以在摩天楼官方Q群里面找到。
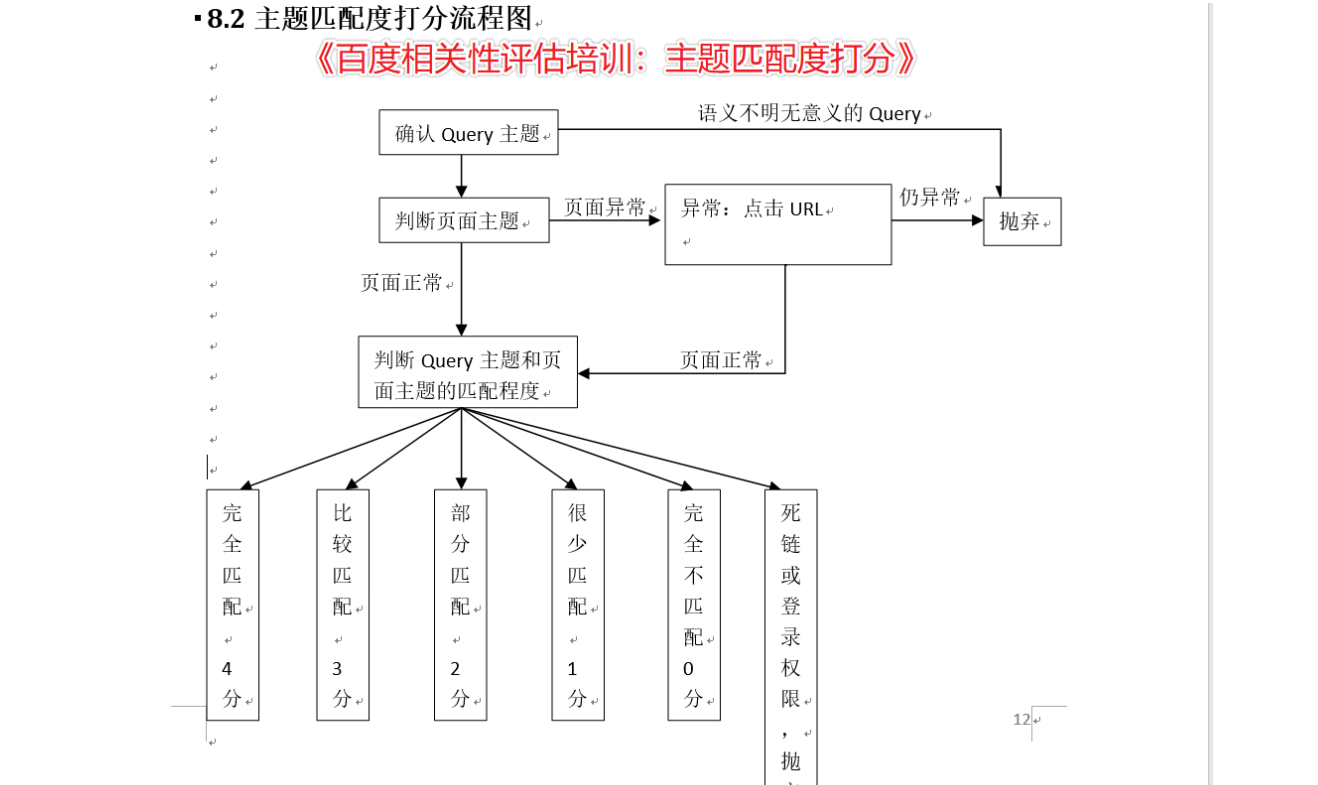
码迷把这些资料汇总起来,百度主要从这三点来考察评估你的页面内容匹配度,也是摩天楼内容助手的核心所在,码迷称之为“相关性提权法”。

相关性提权法有没有用
直接看案例,用事实说话,不装逼,稳定首页都3个月了,比那些光吹大话的大神们要实在的多。
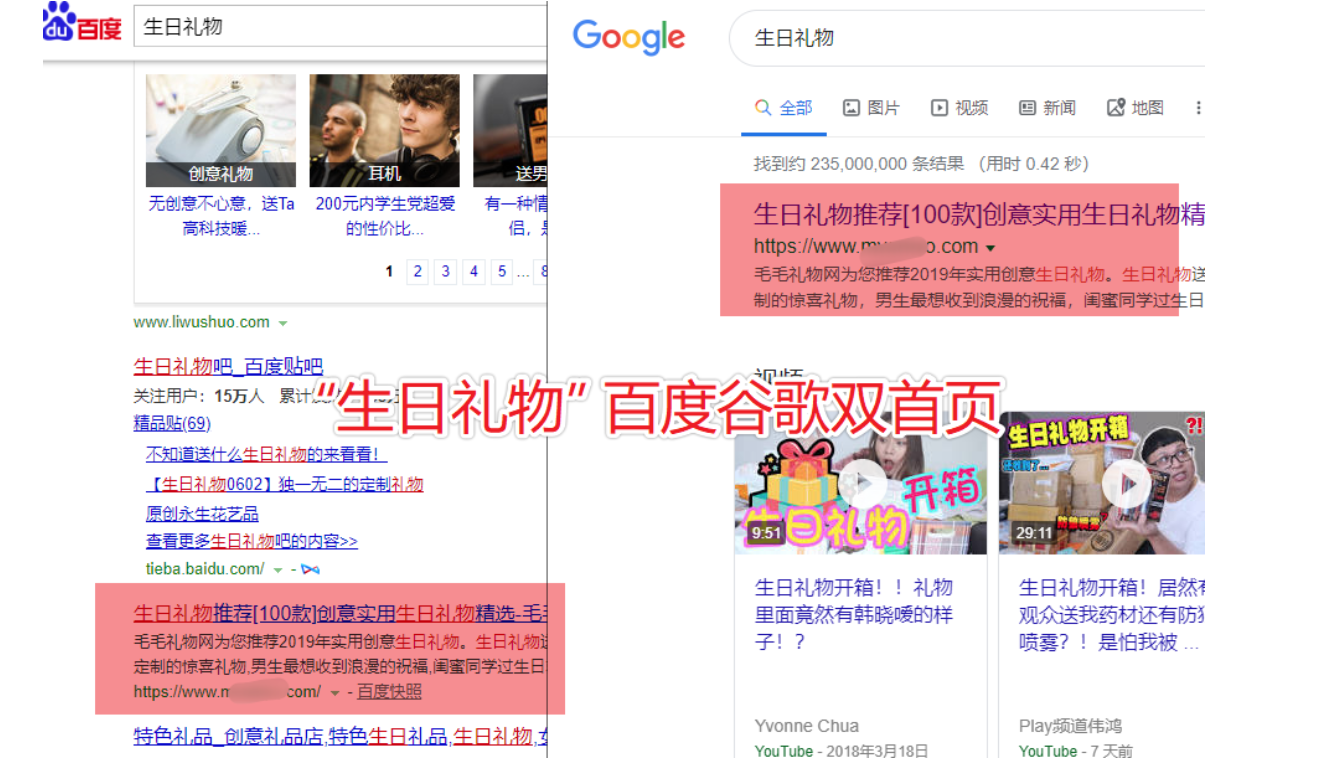
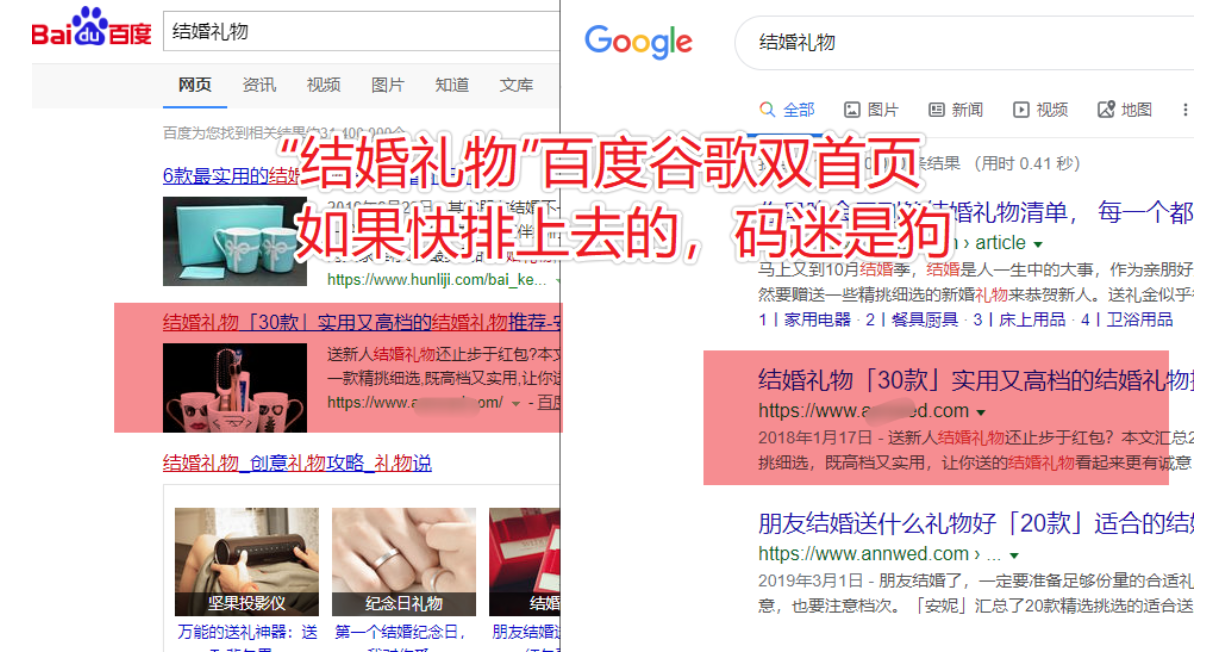
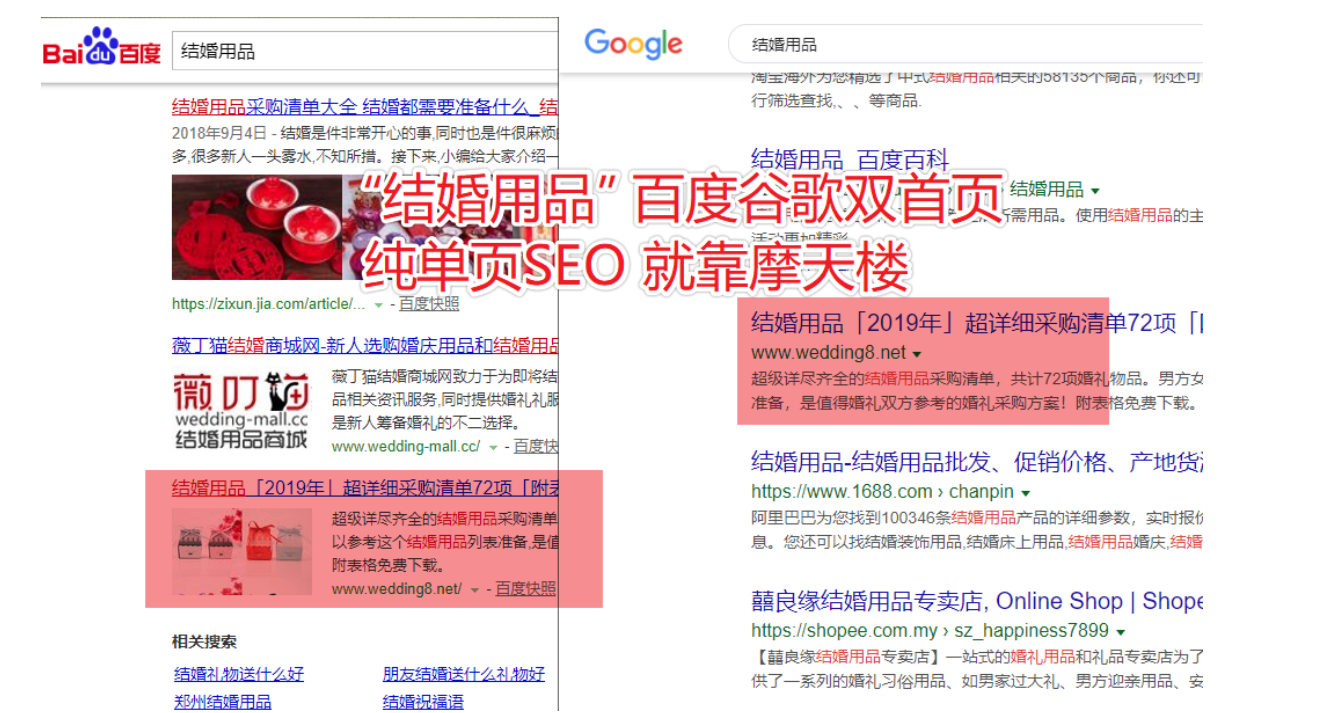
这些都是码迷的实验站点,码迷前前后后忙了20天左右,都是真实案例,生日礼物目前每个月收入1000+。每天一包烟钱,是不是赛过活神仙?
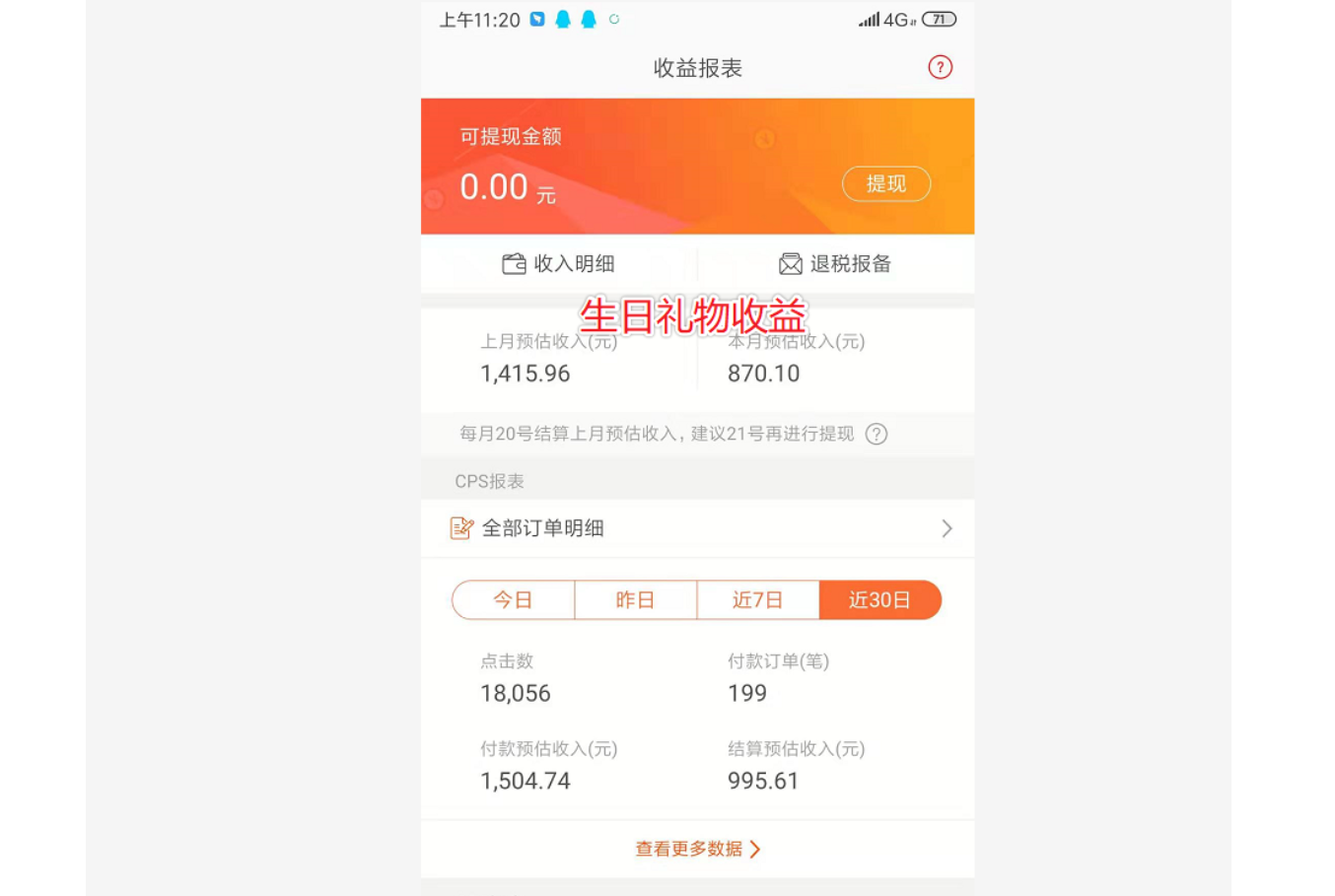
相关性提权法操作点
第一:用户搜索词与网页标题是否匹配
无论是写原创,还是采集为原创,写好一个好标题,不仅能有好的排名,也会有好的转化。码迷将会在《码迷百度SEO内参》的后续章节中,讲解如何去做网页标题,这里只简单说一下。
基础:标题包含搜索词
网页的标题,也就是title。比如用户在搜索“取英文名”的时候,那么你的标题中必须包含“取”、“英文名”两个词,如果没有,对不起,百度觉得你不太合适。
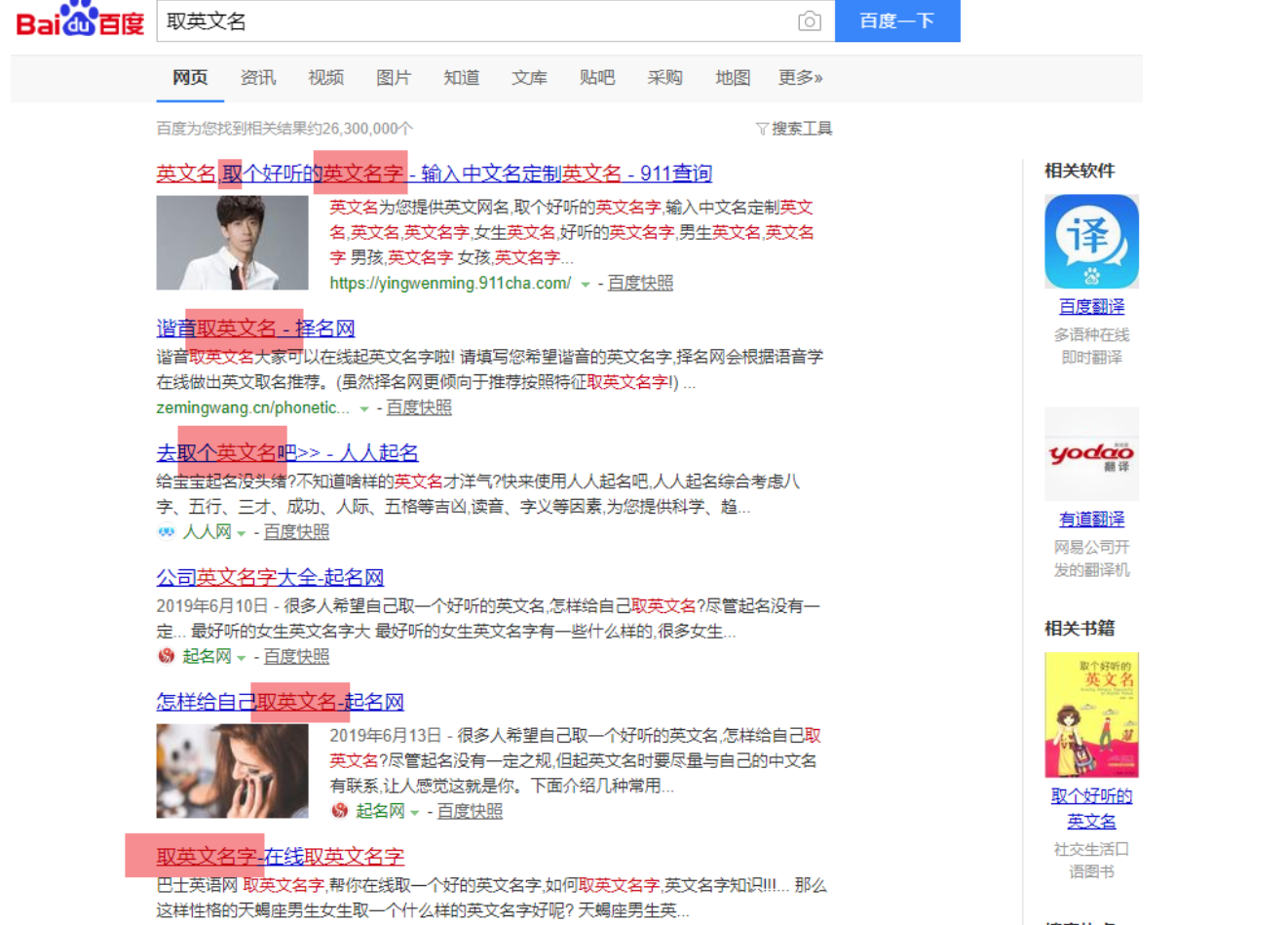
扩展:后续需求词匹配
很多同学在写标题的时候,基本做到了搜索词覆盖,比如我要做“SEO顾问”这个词,我的标题是“SEO顾问_搜索排名优化顾问_某某络网络技术”。那么这个标题好不好,很多同学觉得还可以,其实这个标题一般。为什么?
我们想想,如果用户找SEO顾问,一般是需要您来对他的网站提供SEO服务。用户在锁定你的网站后,更需要的是您的服务。所以服务是用户背后的真正需求,码迷称之为后续需求词。
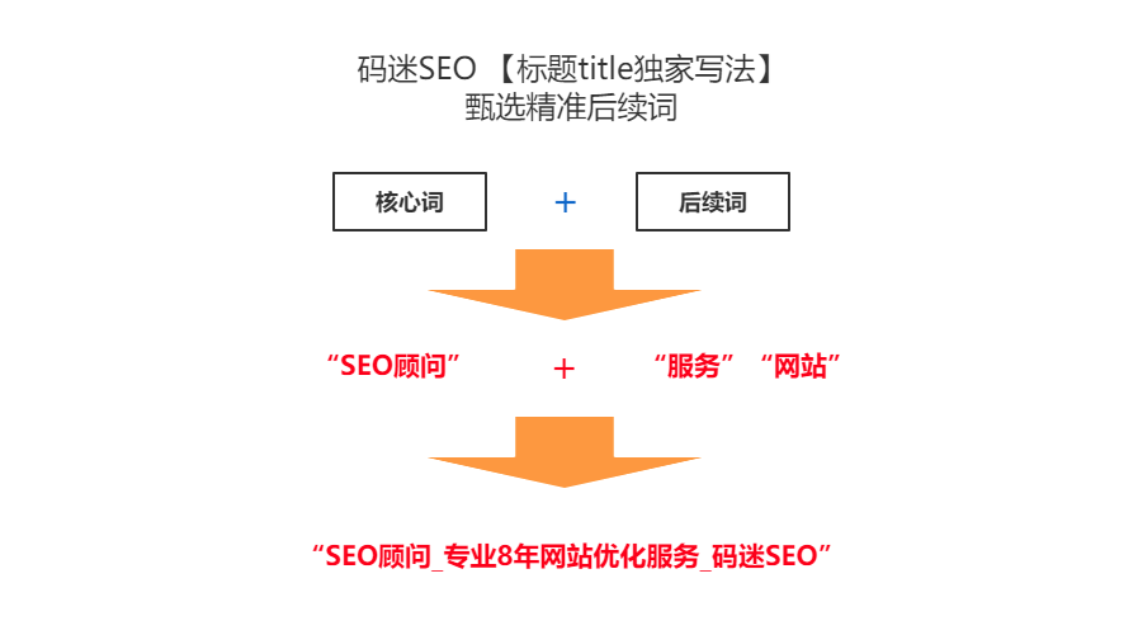
而在摩天楼内容助手中,也提供了后续词检测以及建议。就是说我网页标题不仅基础做的好,还能满足用户的背后需求,这才是好标题。
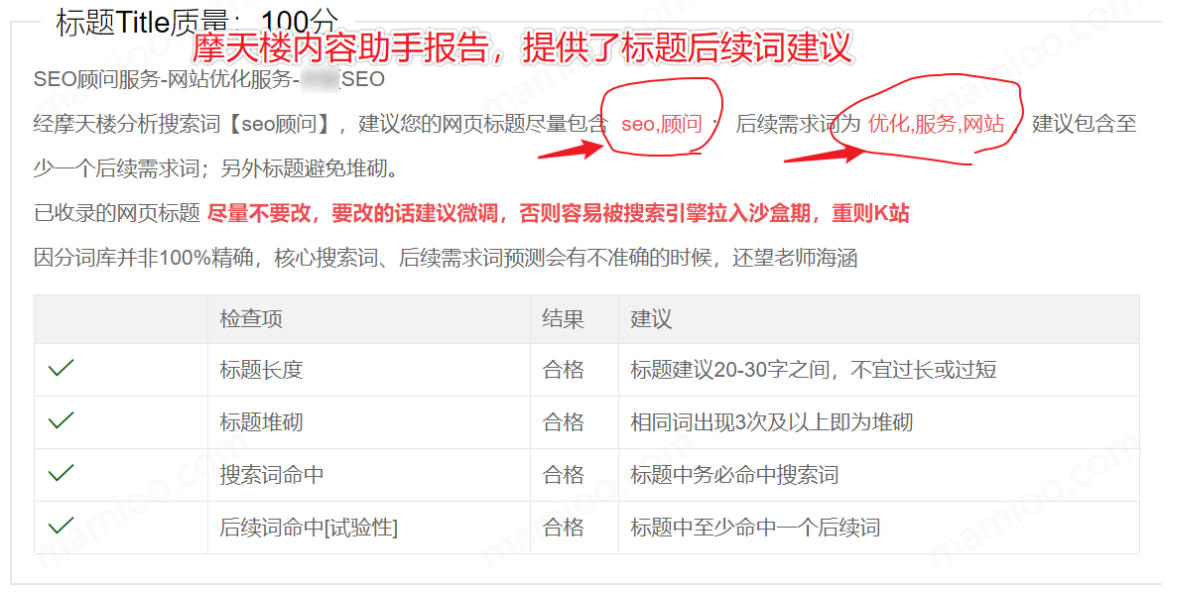
第二:用户搜索词与网页内容是否匹配
这部分是百度最最关心的地方,也就是你的网页主体内容是否符合了用户需求,以及满足程序到底有多少。百度如何判断,百度在专利中说的很清楚,就是BM25相关性算法,谁的内容里面包含的相关词越多,密度越合理,谁就是质量最好的。这一块不是空穴来风,在码迷《码迷:分享摩天楼内容助手开发过程及探索之路》中也是验证了的。
市面上无论是“N处一词”、“N词加权法”、“关键词密度建议值就是2%~8%”等关键词布局法,还是未来某个老师提出的“超牛逼独创高级万能不得了快速雄霸关键词密度控制大法”,只是触及到百度相关性算法的皮囊而已,还远远没有触及到百度算法的灵魂。

这里有3个层面。
第1层:网页内容必须包含搜索词
打个比方,你做“待产包最全清单”这个词,分词后是“待产包”、“最全”、“清单”三个词,那么你内容里面务必也要包含这三个词。
第2层:网页内容尽多包含搜索词的相关词
搜索词的相关词是什么?还是“待产包最全清单”这个词,待产包是为妈妈跟宝宝准备的,那么这个词的相关词包含“妈妈”、“宝宝”两个词。通过摩天楼内容助手我们可以通过大数据挖掘到这些相关词,一般在网页里面进行布局前30-50个相关词,你网页基本就是相关性无敌的状态了。
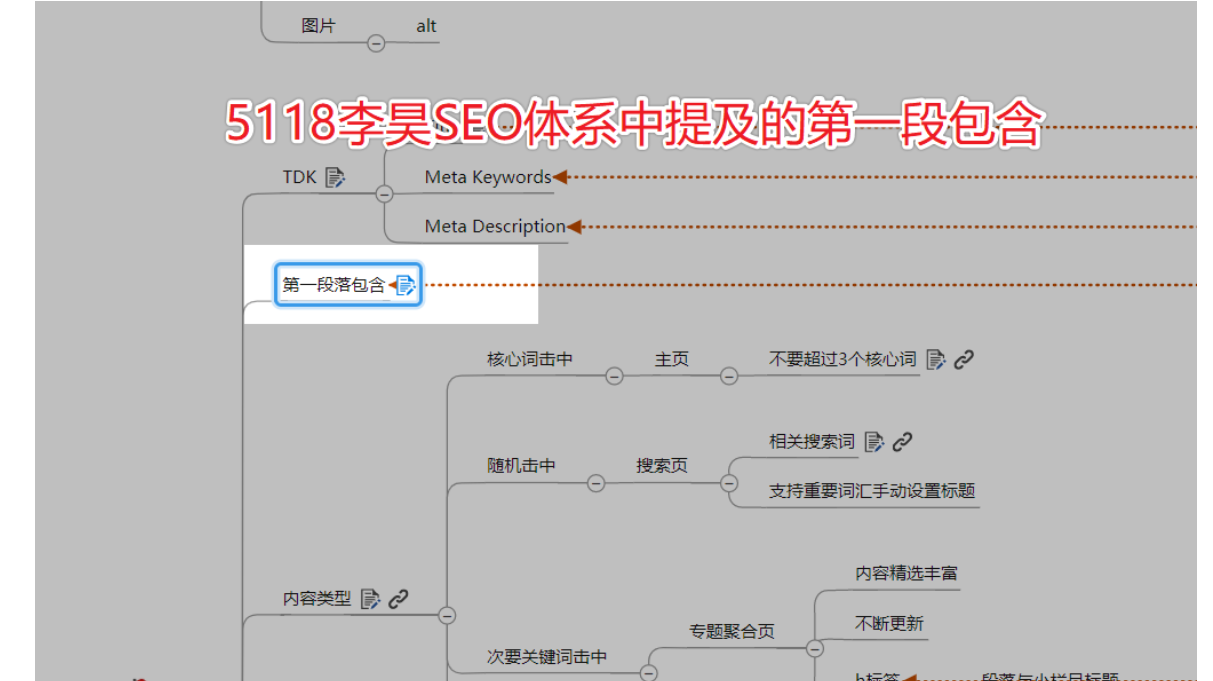
第3层:最相关的相关词放到网页内容前部
这个怎么说?我们在前面也说答案获取成本这个东西,码迷想到了5118创始人李昊在一节公开课中提及的“第一段包含”规范。
为什么要做“第一段包含”,核心原因就是让百度认为你的内容答案获取成本低,更能快速满足用户需求。
摩天楼建议你的网页首段包括网页描述(description)尽量包含最相关的前5个相关词。
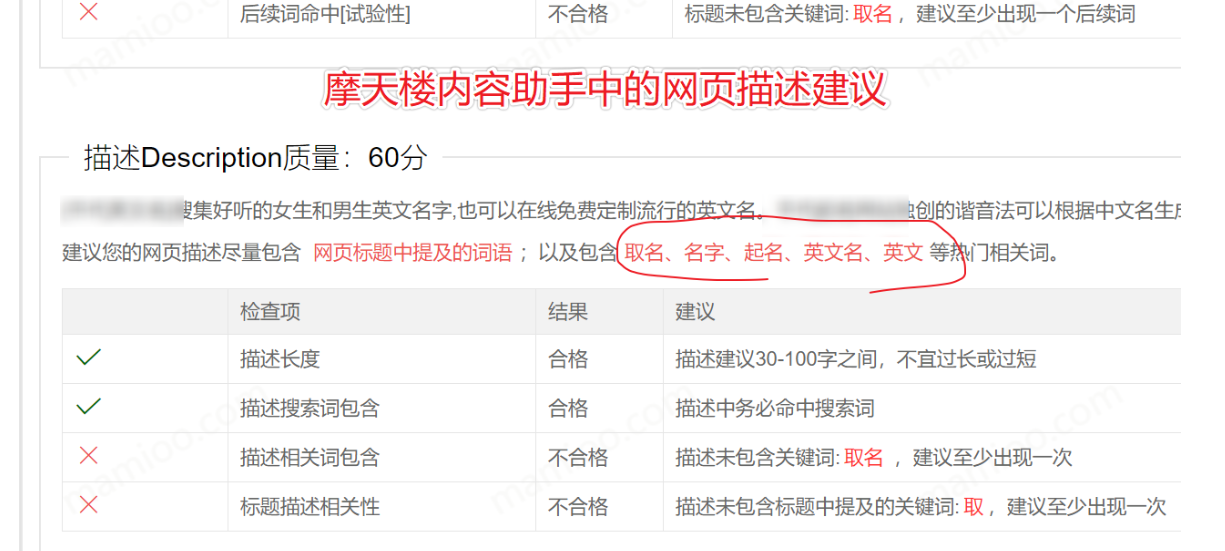
第三:网页标题与网页内容是否匹配
说白了就是文要对题,不要挂着羊头卖狗肉。现在做垃圾站的也都讲究网页标题提及的词语必须在网页内容中包含。
摩天楼也提供了标题内容相关度检查,人做事会有粗心的时候,但是工具从来都兢兢业业认认真真。

总结:什么是相关性评估提权法
1. 网页标题与搜索词不仅词面上相关,后续需求词也相关。
2. 网页内容与搜索词不仅词面上相关,更多相关词也要部署到内容中,热门相关词 “第一段包含” 。
3. 网页标题与网页内容高度相关,主题集中。
针对老页面:
摩天楼内容助手优化可以提权老页面现有的内容质量,超强相关性主题集中,你的内容质量再上一个台阶。
针对新页面:
发布之前,摩天楼内容助手优化可以给你提供相关词的写作参考思路,防止主题跑偏,助你更快达到新站或新页面秒排效果。
SEO的核心就是竞争,我比你规范,我相关性还比你牛,内容上你就是弟弟。
摩天楼内容助手,帮助SEOer打造既符合SEO规范,又有竞争力的网页。
最后引用摩天楼Q群里大佬的话,你应该试试。
十一、SEO内参(11) 百度飓风3原创检测算法讲解以及伪原创检测工具
上一节码迷跟大家探讨了单纯的同义词伪原创、AI伪原创都会被百度识别。这节咱就探讨百度飓风3原创检测算法的内部讲解,并且跟大家一块分析伪原创检测工具的好坏。
通过本节SEO内参,你将对怎么去做采集、怎么过百度原创检测有了明确的思路,广大辛苦的SEO的工作者们,以及善于玩转火车头、采集侠、简数的老师们,本节千千万万不要错过。
先看一个问题
码迷把摩天楼内容助手使用指南放到网上之后,百度收录了。
然后我通过在百度里面搜网页内容里面的句子,发现有的句子能飘红,有的句子不能飘红。看下图
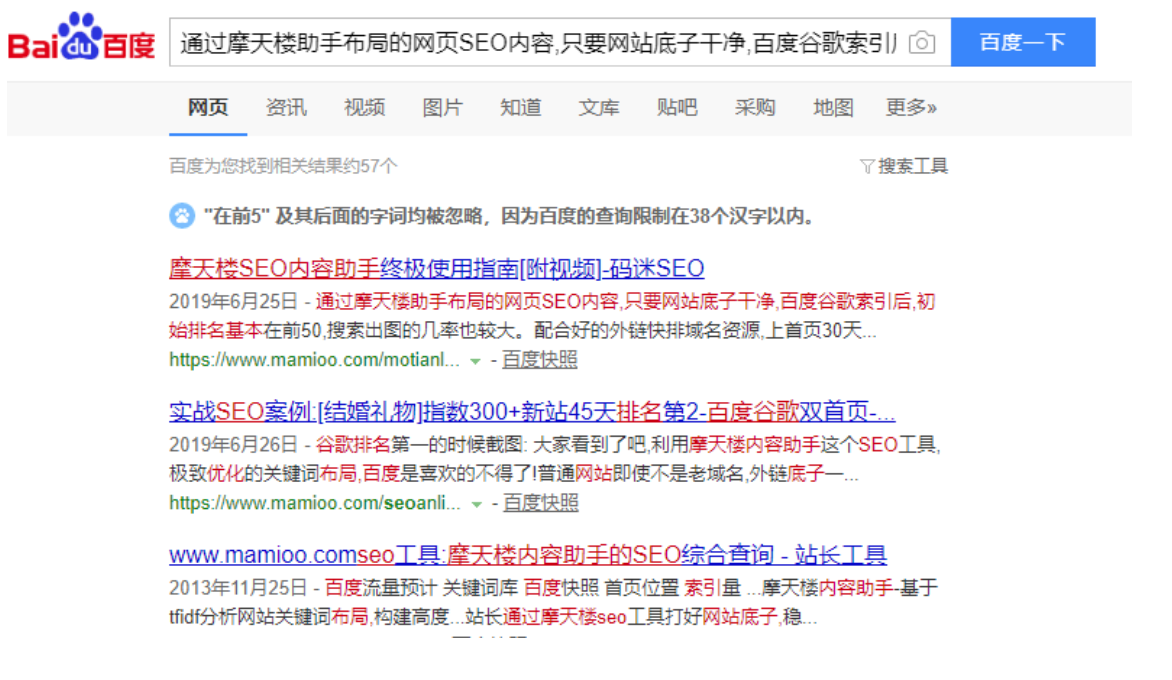
有一些句子是不飘红的。
你知道为什么吗?
为什么网页内容里面有的句子能全飘红,有的句子没有飘红。大部分的SEO从业人员都知道飓风算法是打击恶劣采集,但是绝大部分SEOer都不知道飓风算法底层到底是什么个算法。这就是高级SEO跟小白SEO的区别。
第2个问题:伪原创检测工具准不准,哪个好
相信大家,读了码迷《SEO内参(九) 飓风算法3.0的前世今生及AI伪原创工具评测 (上)》这篇文章之后,网上99%的伪原创检测工具你觉得准不准?
有些人一本正经的讲解伪原创检测思路,还有些人做程序纯碎为了薅羊毛~
成年人做事情要摆事实讲道理,胡乱臆测是不对的。
原因解析
通过飓风算法对应的专利《CN107169011A-基于人工智能的网页原创性识别方法、装置》,我们可以看到百度的原创检测步骤
步骤1 分句并按照权重排序
百度对网页正文内容进行分句处理,分句后通过IDF算法对句子进行排序,高权重句子在前,低权重句子在后
步骤2 检测所有句子原创性
注意,百度是把所有的句子都进行了原创检测,通过simhash算法判断,如果该句子已经在句子级词典中存在,则为重复句子。
步骤3 计算原创度
百度给的原创度=高权重原创句子权重之和 / 所有句子权重之和。
步骤4 原创判断
如果原创度小于某个阀值,被判定为非原创,抛弃。
如果原创度大于某个阀值,判定合格,高权重句子 句子级词典 库。
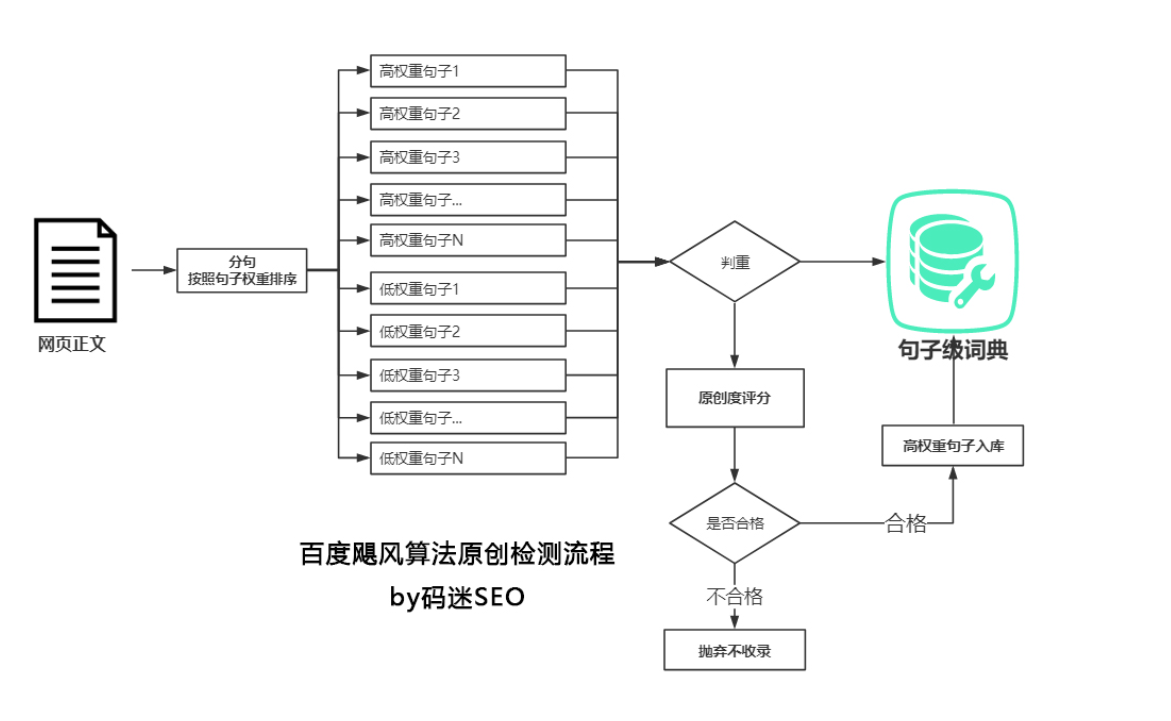
下图是百度专利说明书:
看不懂没关系,我们拿案例说明。
码迷根据百度专利简单实现了句子权重算法,还是拿摩天楼内容助手说明作为案例,得出权重排序如下:
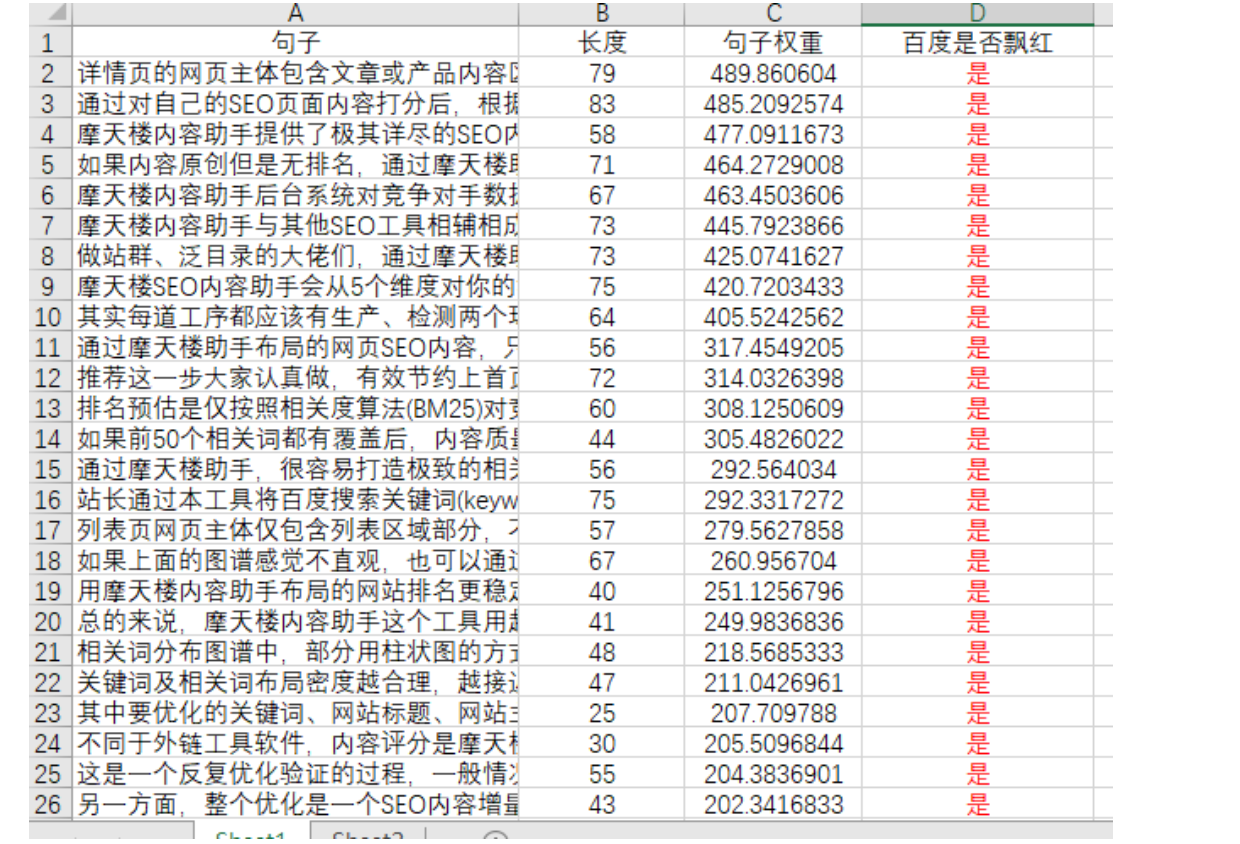
句子权重与句子长度的关系
一图胜千言,句子长不一定代表权重高。
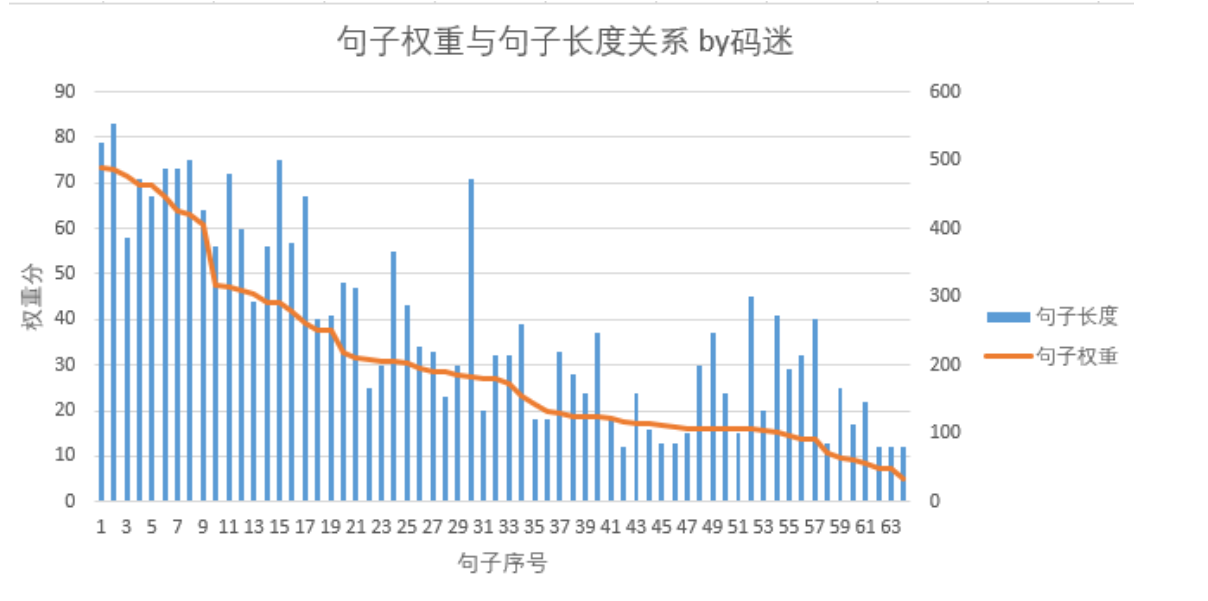
百度飘红结果的截止点
码迷的这篇文章中,64个句子,通过百度线上检测,从第40名开始就出现不再飘红的句子。飘红句子数约占整个句子数比例的60%左右。
也就是说,百度只是提取了网页内容里面部分句子进了百度的句子词典。所以就解释了同一文章中,有的百度结果句子飘红,有的结果不飘红。
百度原创度公式
百度专利里面是这样说的:
比如,可首先计算出从待识别的网页中提取出的各句子的权值之和,从而得到第一相加结果,如何获取句子的权值可参照一)中的说明。
之后,可进一步计算出从待识别的网页中提取出的各句子中的原创句子的权值之和,从而得到第二相加结果。
最后,用第二相加结果除以第一相加结果,将得到的商作为待识别的网页的原创性评价结果。
码迷总结一下:
原创度 = 原创句子的权值之和/各句子的权值之和
如何提交原创度?
公式是个好东西,只要一总结出来,就知道因子了。
方向1 原创的句子尽量高权值
方向2 抄袭的句子尽量低权值
百度说了,飓风算法不是打击采集,而是打击恶劣采集,也就是说凡事有个度,度度度。也就是只要原创度把握好了,就能过百度原创关了。
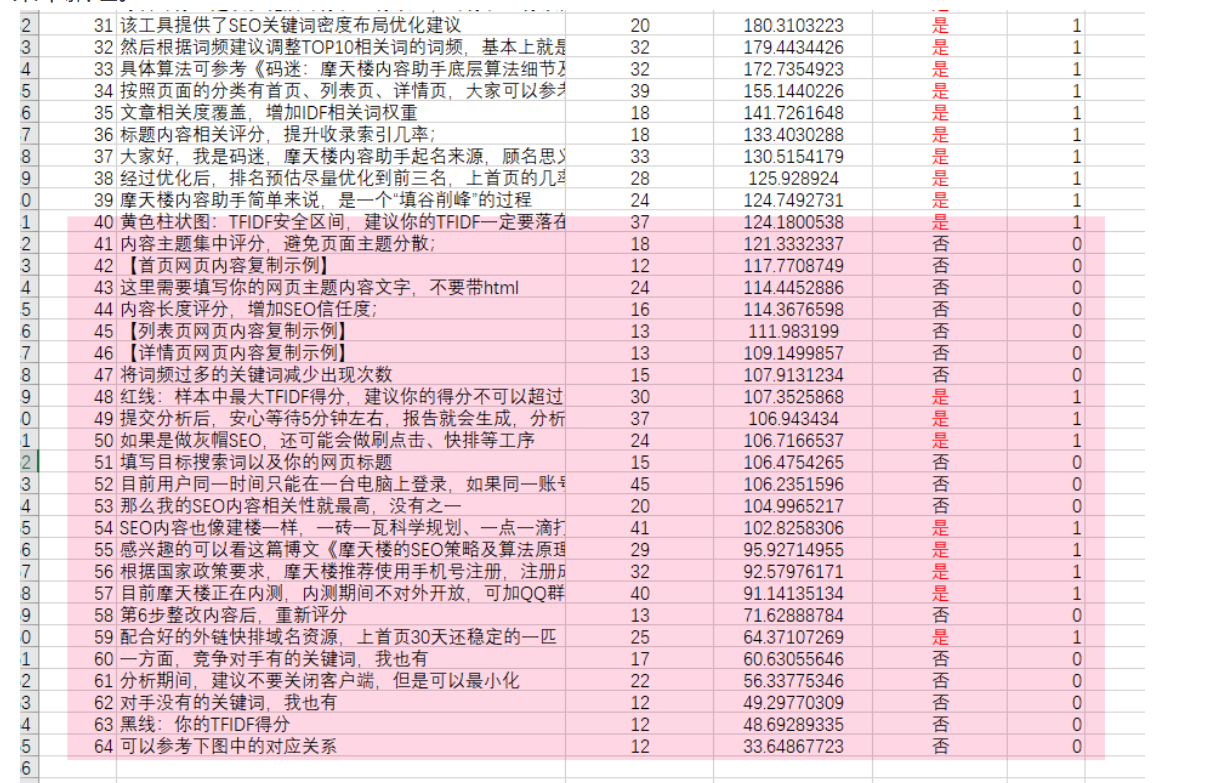
07 深入百度的网页原创性识别方法解析(下)
百度原创度到底是多少
现在很多SEO同学都是采用采集组合的方式,简单说就是采集3-10篇其他文章的内容,再将段首段尾加工一下,变成自己的文章。
然后用伪原创检测工具检测一下,只要超过某个阀值,如60%,就OK拉!
这种方法能不能过百度原创检测,有木有用?码迷告诉大家,有用,而且是不错的方法!但是不能100%过原创。
最后总结
码迷只是简单的对《CN107169011A-基于人工智能的网页原创性识别方法、装置》做了分析,更多的细节大家可以自己挖掘。
首先
不要在同义词替换、AI伪原创上浪费时间
其次
不要在 不以句子权重为基准的伪原创检测工具 上浪费时间
再次
如果你采集的内容都是百度句子级词典的句子,你完蛋了
最后
嗯,百度句子级词典又不是全量的,所以还是可以玩点采集伪原创的。只要没有超过百度原创度的那个阀值,就可以搞哦。
十二、SEO内参(12) 快速排名系统野史,快排战度娘折腾3年之后又3年
编者按(2023):
截止目前2023年5月,点击通过率依然是百度的核心排序算法之一,但是自从2021年以来权重有所减低。
我通过百度专利反推,百度通过机器学习自研了点击通过率预测模型,不再直接依赖于用户行为数据。
截止目前市面快排已经绝迹,而且仅有部分私有快排对特定行业管用。
正文开始:
今天SEO内参开始讲快排,百度内部并没有快速排名系统,快排只是对应了搜索引擎内部的一套工序,这套工具叫 用户点击行为统计系统。
针对的百度算法岗位叫CTR(点击通过率)算法。
最早的CTR算法系统百度2010年左右有所涉及、2012~2013年开始完善布局。
之前百度谷歌因为在中文系统算法上互相较劲借鉴,但是在谷歌退出中国之后(2012年),CTR技术上开始分道扬镳了。
今天的题目叫快速排名系统野史,快排战度娘折腾3年之后又3年,大家看着笑笑就好,别当真。
某日,有人在群里说道:
施主,贫僧乃东土大唐而来,我这里有顺时、怀道、破天、有客来、凤巢、超快排、上排名,互点宝,飞驰优化,云优,不知道施主需要哪样快速排名。(⊙o⊙)…施主,你不要懵啊,施主你快醒醒~

以上都是近期的快排系统,码迷看了一下网上的快排介绍,基本上是以“快排解密”为虚头的文章,把简单的东西复杂化了。
对快排原理不太懂的,可以去看码迷之前的文章《SEO内参(六):谈谈百度对快速排名的打击手段》,其实快排很简单的。
没有读过的朋友一定要先看一下,否则本文讲百度快速排名系统简史,你可能会懵~
从“公地悲剧”到快速排名
在讲快排之前,讲讲公地悲剧,“公地悲剧”是美国学者哈丁曾在1968年提出来的。它假设有一个向一切人开放的牧场,如果每个人从一己私利出发,就会毫不犹豫地多养羊,因为收益完全归自己,而草场退化的代价则由大家负担。

而每一位牧民都这样思考时,“公地悲剧”就上演了——草场持续退化,直到无法再养羊。
SEO内参本次推出百度快排系列专题,因为伴随着10月、11月百度最新点击系统的升级,基本上90%的快排已经被干掉了,所以跟不上算法不赶趟不行啊。只有从现象看规律,从规律看原理,从原理不断悟思路才可以玩的长久哦。
自从谷歌2012离开中国之后,度娘技术不思进取(这块在随后的章节会讲到,不是空穴来风),也就注定了百度排名都说结果比谷歌要烂很多。
百度的用户行为系统技术选型,因为多多少少缺少远见,也注定了最近几年快排系统的疯狂狂欢、也注定了百度站长频繁的报错更迭、也注定了零距离多开推送的小欢乐。
虽然百度内部已经有点拆西墙补东墙了,但是物极必反,从今天来看,快速排名的发展历史就是一场国内SEO环境的公地悲剧。
2012年第一代快排系统,人肉互点
伴随着百度点击统计系统的上线(预计成型于2011~2012年之间),很多人发现,点击可以提升排名。第一代点击系统-人肉点击开始流行起来了。那时候百度还没有对跳出率、停留时长等因素做严格的考核,码迷记得只要一对一互点的人够多,基本上上午点击,下午就能上排名。
典型代表:学员互点、QQ互点群
1.执行力不可控
人工互点的缺点很明显,就是执行能力与执行方式的不同。比如要求搜索词进入网址后,要停留15秒以上,有些人5秒就关了。这倒好,让百度觉得你网站跳出率高,排名反而降低了。
2.不能上大词及大范围上词
比如“生日礼物”这个词,指数在1200左右,这种大指数词每天搜索的人在500人以上。如果到qq群招人互点,每天找20人就不错了,相对于500人简直是杯水车薪了。大范围上词同理。
SEO互点逐渐没落之后,被更火更流行的拼多多互点、淘宝互点、抖音互点替代了。
当然SEOer大佬们也没有闲着,在SEO互点QQ群流行了2年之后,着手提高执行力与准确度的第二代快排出现了。
2012~2014年第二代快排系统,挂机点击软件
伴随着互点群的SEOer们搞得兴高采烈的时候,百度也在13~14年之前推出了第二代百度点击统计系统(码迷认为是百度一大败笔)。因为百度点击算法上的缺陷,搞得大佬们很高兴,挂机互助点击软件等一系列快排软件横空出世了。
当时比较有名的有“关键词排名优化大师”等等,打着快速占领互联网战略高地的旗号开始迅猛发展。但是这段时间,大部分人没有意识到转化词排名的重要性,都觉得有流量才是王道。所以那时候流量宝之类的软件远比现在吃香。
典型代表:飞驰互点(feichi.site)、快排宝(www.dur5.com)、互点宝、快排助手
IP有丰富的多样性
因为绝大多数互点类的快速排名软件都是真实的客户端IP,IP资源优质,百度对其信任度较高,所以即使到了今天,部分互点软件还是有效果的。
不适合大规模上词
但是如果要上1000个行业相关的词,你一台挂机的电脑是不可能跟其他的挂机电脑同等置换点击次数的。所以各大互点软件平台推出可以通过买积分的方式来获取点击,但是花销也是巨大的。而有些大佬已经在考虑集约型云端快排系统了。
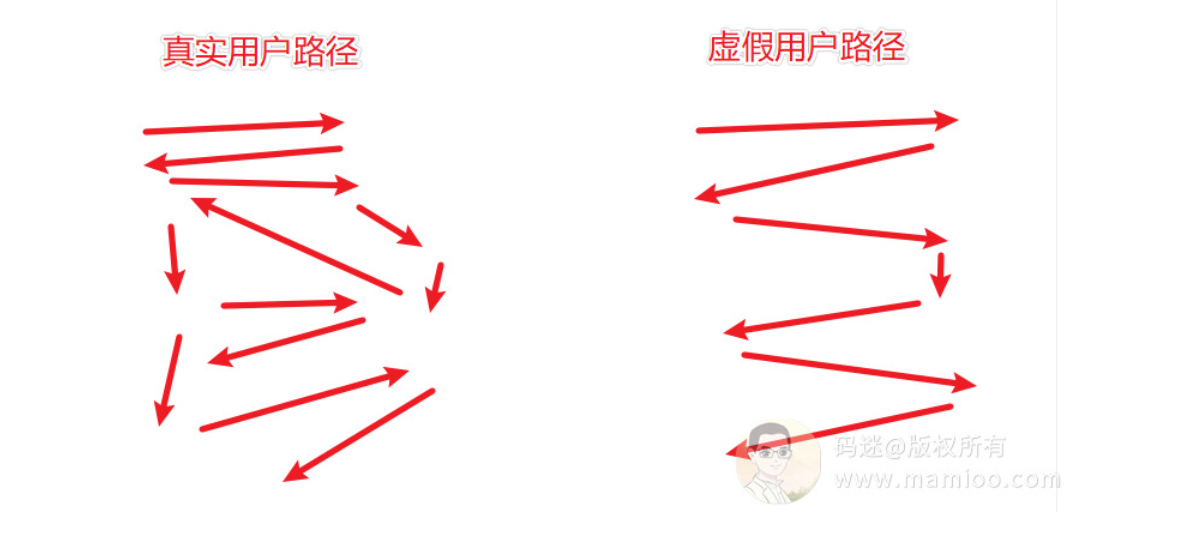
点击路径太简单
这也是互点点击软件的一些缺点,点击路径太简单了。因为真实情况下,用户找到你的网页基本不是通过直接搜索词一步到位的。而是反复的换词搜索,才到了你的网站。2017年惊雷2之后,对点击路径有所要求,所以这也导致了互点类点击系统效果一般,逐步淡出了一些人的视野。
当然最近的一些互点类快排软件开始反思这个问题。
2014年第三代快排系统,云端运行
其实第三代云端快排系统在2012年开始有人开发出来了,但是基本上最初的平台型快排系统也仅与大公司大客户对接(谁不喜欢狗大户啊),所以至少在2016年之前,快排并未进入大部分SEO的眼中,市面上的SEO培训课程也主要以白帽SEO为主。
因为好多SEO大佬都是闷声发大财啊,不用做内容,刷刷点击就能上排名,这样的好事自然知道的人越少越好哦。但是后来,随着培训课程中,快排已经变成必修课了,人人开始关注快排系统了。
典型代表:尊诺快排发包程序
其他比如顺时、怀道、破天、有客来、凤巢,云优,其实他们的原理都是一样的,都基本有三部分组成,IP资源+快排参数+点击计费统计。
1.IP资源
目前有效的IP获取途径有VPS拨号(淘宝有拨号主机)、代理IP资源(如快代理)、与互点平台合作(如流量宝)
2.快排参数
很多快排都声称自己掌握了最新的百度点击算法参数,码迷觉得这个噱头更多一些。因为绝大多数快排点击系统都是驱动浏览器来模拟点击,根本就没有发包之说,只是让浏览器显示与不显示罢了。
其实码迷觉得参数是最最不重要的,虚无缥缈的东西最利于推广打广告罢了。他们之间的点击区别只是点击路径上的区别以及上词套路而已。
3.点击计费系统
7天上首页,不上首页不要钱,上了首页天天要钱。所以,精确的点击计费系统是快排商们最最最关心的宝贝。为啥子这么说?
点击参数其实大家都是心知肚明的,赚钱的关键在于能画一个多大的圈圈,圈住多少韭菜。
只要韭菜多了,计费系统来一套,点击系统对接别人的点击资源就行了。找快排的时候,认清对面是不是二道贩子,码迷就不展开了。
2017~2018年惊雷算法1-2
在2017年之前,百度对点击快排也并未有太多的关注,因为快排没有干涉百度的核心利益,相反还对点击竞价有所帮助。所以此间百度对刷点击刷快排并未有太多的打击。但是玩快排的人实在是太多了,百度天天被站长们指着鼻子骂娘了。
所以百度开始做做样子,因为第三代快排系统过分依赖于代理IP资源,百度2017年就出了惊雷算法(名字很玄幻,光打雷不下雨)打击打击。但本质上百度底层点击统计算法还是那一套啊,所以快排系统很快有了新的转机了。
一个一万多指数的游戏词,花了500块就给上了第二,每天维护50块,一个月维护也才一两千,流量每天能带来1000多ip。你说有多爽啊~。
所以2016年到2019年是快排的黄金发展时期,至少在2019年7月份之前,其实快排把百度打的渣渣都没有了。所以百度不得不再行动一下了。
2019年7月第四代快排系统,整站优化
百度第二代点击统计系统缝缝补补又三年,被百万白帽站长指着鼻子的百度,终于第三代点击统计系统在2019年年中踉跄上线(百度点击统计系统会在以后的章节讲解)。
忽然有些人发现好端端的尊诺快排发包程序变成了K站神器,不能给自己网站刷了,只能给竞品刷了,窝草,这是怎么回事。
原来部分发包(码迷认为发包是无头浏览器,非TCP发包)已经被百度识别,并且点击没法单个上词了,只能整个网站词一起开刷才不容易被K。
针对整站优化的快排系统陆续上线,上排名、云优、顺时、怀道等一线二线快排系统开始与百度算法赛跑。
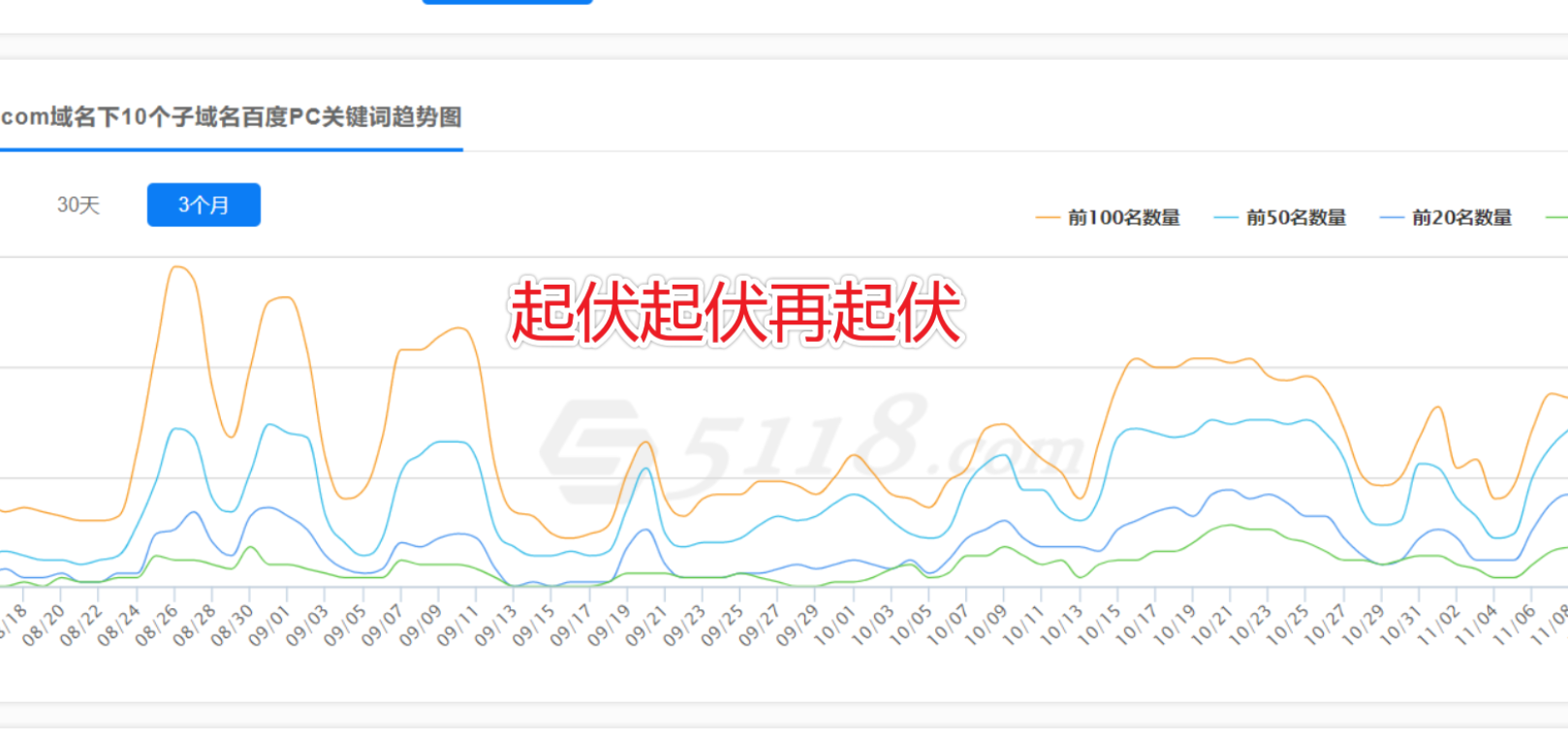
然而大事还在后面,从8月份开始,一直到11月份,目前还在持续,百度内部发起一轮秋冬攻势,百度开始加快迭代速度,百度甚至连基本的测试都不管了,开始硬头皮上了。

不仅百度站长后台一直不稳定,百度索引也被嘴上无毛的程序猿们一遍一遍的刷过来刷过去,有些网站甚至出现了八年前的快照回档,有些网站跟坐了螺旋过山车一样起伏起伏再起伏。
9月份:IP资源被干了一波,大量快排网站被降权
10月份:站内搜索快排手段被打击,部分刷快排的知名大站被降权
11月份:百度还加大了惩罚力度,更多快排网站直接被K。
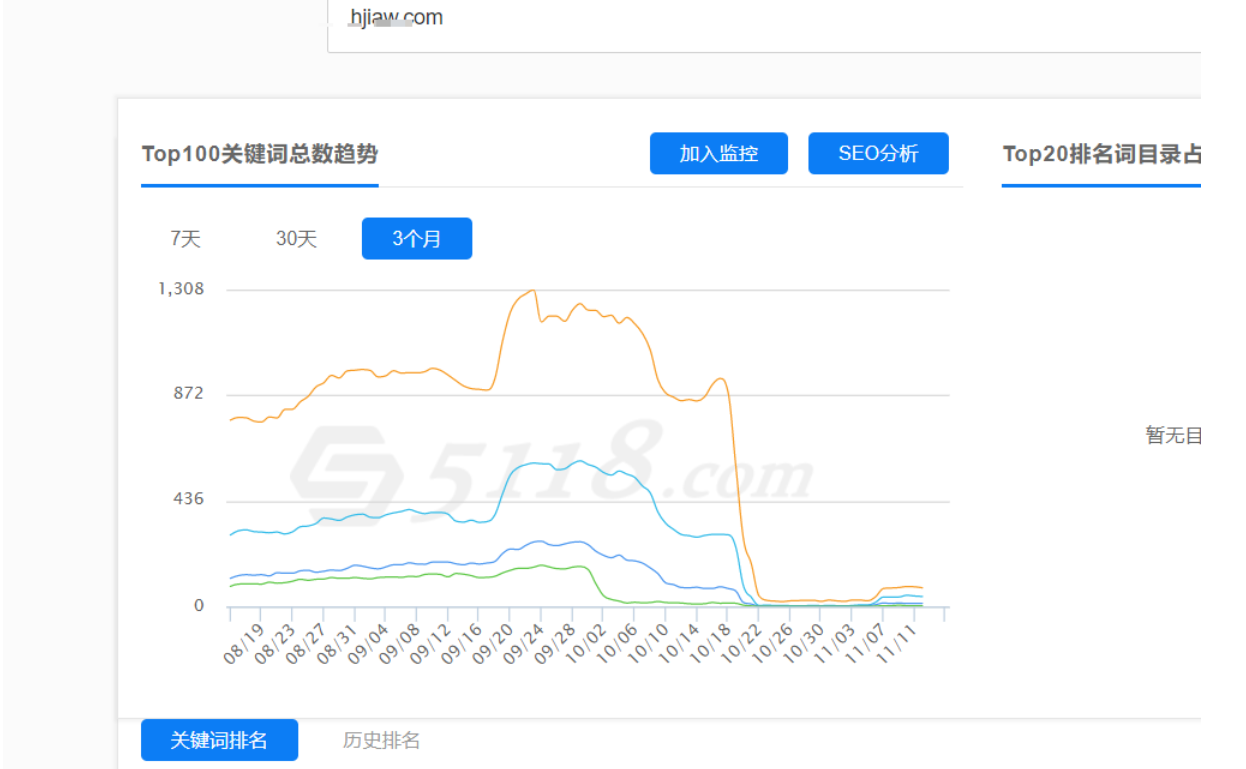
很多老师才开始意识到,尊诺只不过是小前锋而已,刷快排是死,不刷也是死,到底刷还是不刷。
码迷:还不如不刷呢~
唉,一声叹息了,很多老师开始忙活着找新的快排,但是话说回来,
真正赚钱的快排是不针对散户的
码迷说到这里,大家心里应该有数了,现在好的快排系统又变成了稀有货了,真正赚钱的快排是不零散出租的。正如跟之前好多快排系统对待散户的态度是一样:
1. 散户,没钱还事儿多,词少没意思。
2. 资金资源都不是散户承受的,还有的散户上词就跑路,所以散户基本上找好的快排希望很渺茫。
3. 喜欢企业客户,直接填合同,月包成万的上词,大家都有钱赚。
所以天天在群里喊着5天上首页,7天上首页的,反而要注意了,是不是骗子码迷也不知道。
最后
当百度的内部点击统计系统已经精疲力尽,要抛弃快排的时候,“公地悲剧”(草场持续退化,直到无法再养羊)就会上演。但是根据码迷搜集到的资料来看,百度至少最近一两年不会抛弃点击统计系统哦。本节讲了快排系统的历史,下一节讲一讲百度三代点击系统,感谢大家捧场。
十三、SEO内参(13) 百度点击统计系统深入解析(快排原理)
编者按(2023):
接触过快P的应该知道刷最后只能玩整站快排了,单个上词已经不好使了,本文揭示的是其中原理。
简单的说,点击统计系统的统计方法从单个词统计升级到相关词上词,使快P的成本暴涨。
小而美的PC端行业依然可以提高网站排名,但必须在IP、指纹浏览器 、刷词方法上过关。
正文开始:
上一节码迷讲了市井上快速排名系统的发展路程,知己知彼,百战不殆,今天开始讲度娘内部的点击统计系统。为啥要讲百度点击统计系统,因为无论是360、搜狗、神马,很多流程跟着百度学的。
你知道百度内部怎么玩,其他搜索引擎可以说小菜一碟。
其次,做实验绝对不可以像部分人靠硬怼,大家有兴趣可以看一下Zero大神的《查询词、检索词与加#搜索》这篇文章,大神之所以是大神,因为磨刀不误砍柴工。再说一下百度的惊雷算法,读完本篇你就明白为啥叫惊雷了。
最近玄幻的快排技巧
技巧1:我发觉就是,快排助手点击360 超快排点击搜狗 互点宝点击百度,效果不错
技巧2:除了底子好的,上快排稳定,还有真正SEO大佬外。新站排名很少有稳定的
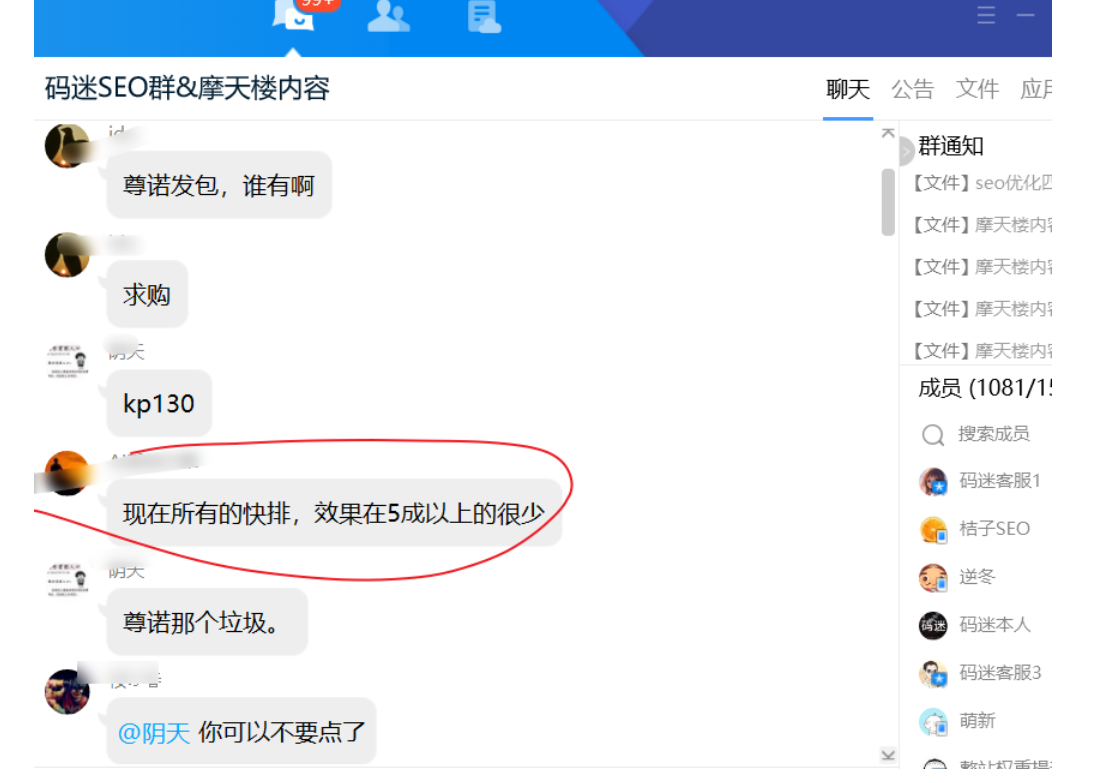
技巧3:现在所有的快排,效果在5成以上的很少,但是多家一起刷就能超过5成了

《孙子·谋攻篇》中还说:“ 不知彼而知己,一胜一负;不知彼,不知己,每战必殆。” 。90%的快排都被百度打的抬不起头来,但也有一些有用,但是稳定上排名超过15天的很少很少。
很明显,快排系统已经“不知彼,不知己”了,赶不上百度内部算法调整了哦。不过码迷建议大家不要病急乱投医,码迷先说一个现象吧。
“RanSpiegler智商税”模型
论文可以到谷歌学术搜“The market for quacks”,讲的是如果医学行业中,病只要结果随机,大家都靠案例来决策,“神医”就会存在。货比三家无法彻底解决这个问题,引入真神医更是毫无用处。
简单说,吹牛逼真的能挣钱。如果推广到SEO行业,更符合现在的情况。
即使大部分快排没有持续性的效果,但是一旦有快排商家提供了案例(无论真假),交智商税的人就会蜂拥而至,即使有人拦着韭菜们也无济于事。
码迷在群里多次讲过,现在看快排不是上了首页就高兴,一定要观察7天以上稳定了,才算成功。但是还是有人捂不住钱包,大把大把的霍霍。
码迷对百度的评价
在讲点击统计之前,说说百度的情况,通过这些大家也略知一二。
首先,度娘人才流失严重
度娘曾经是码迷非常仰慕的互联网公司,码迷是09年毕业,那时候百度、谷歌、微软、摩托罗拉绝对是所有计算机专业同学的首选,只去了搜狗,但是因为不是计算机专业,所以连简历过审的机会都没有。但是2017之后,陆陆续续有爬虫部、Rank部同学从百度离职,今年10月份有个做测试的妹子也从百度跳到今日toutiao了。
有些是因为没有归属感,更多是因为僵化的老白兔太多了,干活的年轻钉子却没有学到本事,在又臭又长的烂代码中活成了人肉干电池。所以,包袱太大,百度不会轻易放弃旧产品逻辑。
其次,度娘人才流失真严重
从执行力上,相比阿里巴巴明显差了十万八千里,比腾讯也差了N个360。百度站长后台频繁报错大家也看到了,反正对待站长的态度是爱用不用。但是更为严重的是百度推广平台也报错,连竞价广告的衣食父母都三心二意了,大家想想吧。所以,即使要上线新的产品逻辑,也是坎坷不顺的。为啥叫惊雷算法?负责下雨的童鞋真的跳槽到宇宙条了。
最后,只能僵着不大动弹了
百度搜索上目前还是国内的权威,每一种搜索技术的推出势必被国内其他搜索学习,况且很多头条好搜神马的同学都是从百度跳槽过去了。但是坦白说未来,技术大牛走的差不多了,以后学习原味的百度技术,去字节跳动宇宙条就行了,百度大牛遍地走哦。
SEO基础知识
需要先了解4个非常重要的排名因素,这都是通过百度内部算法总结而来,绝对不是空穴来风:
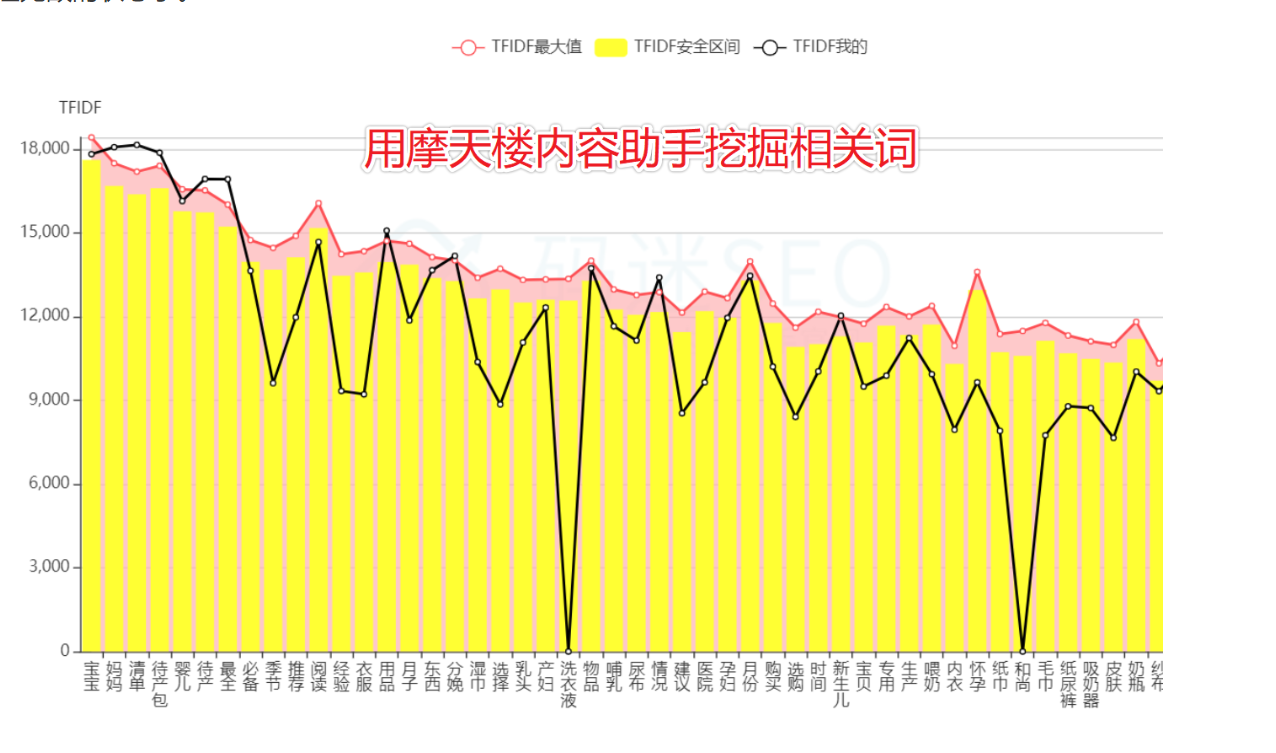
排名= 搜索词意图匹配度 + 点击通过率CTR + 相关性TFIDF得分 + 内链外链PageRank得分
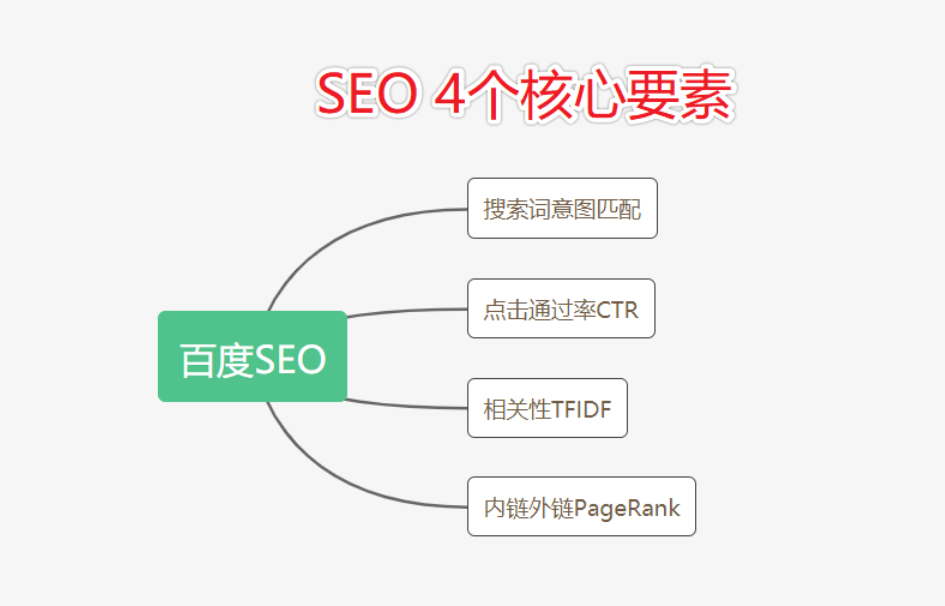
码迷在《摩天楼内容助手官方教程》中有过简单的说明,基础小白建议去看视频,本身限于篇幅暂不解释。
这里的点击通过率CTR,百度不同时期有不同的计算公式,从2010年开始,总共经历了3代,码迷通过研究百度算法专利,以及通过某些呵呵哒途径的核实,对百度三代点击统计系统做一个简单的内幕总结。
百度第1代点击统计系统
1代点击统计系统最早见于2010年专利《CN102073699A-用于基于用户行为来改善搜索结果的方法、装置和设备》,因为当时SNS社交网络的流行,百度将网站热度分成了点击率、推荐率、收藏数三个维度。

百度配套的百度分享按钮也在2011年推出,如果是SEO老前辈,那时候会发现挂了百度分享按钮的网站,如果分享次数比较多,百度排名就会靠前。虽然说现在分享、收藏在排名中权重已经降低很多,但是百度仍然没有放弃(删功能也需要理由哦),程序就是这样堆起来的。
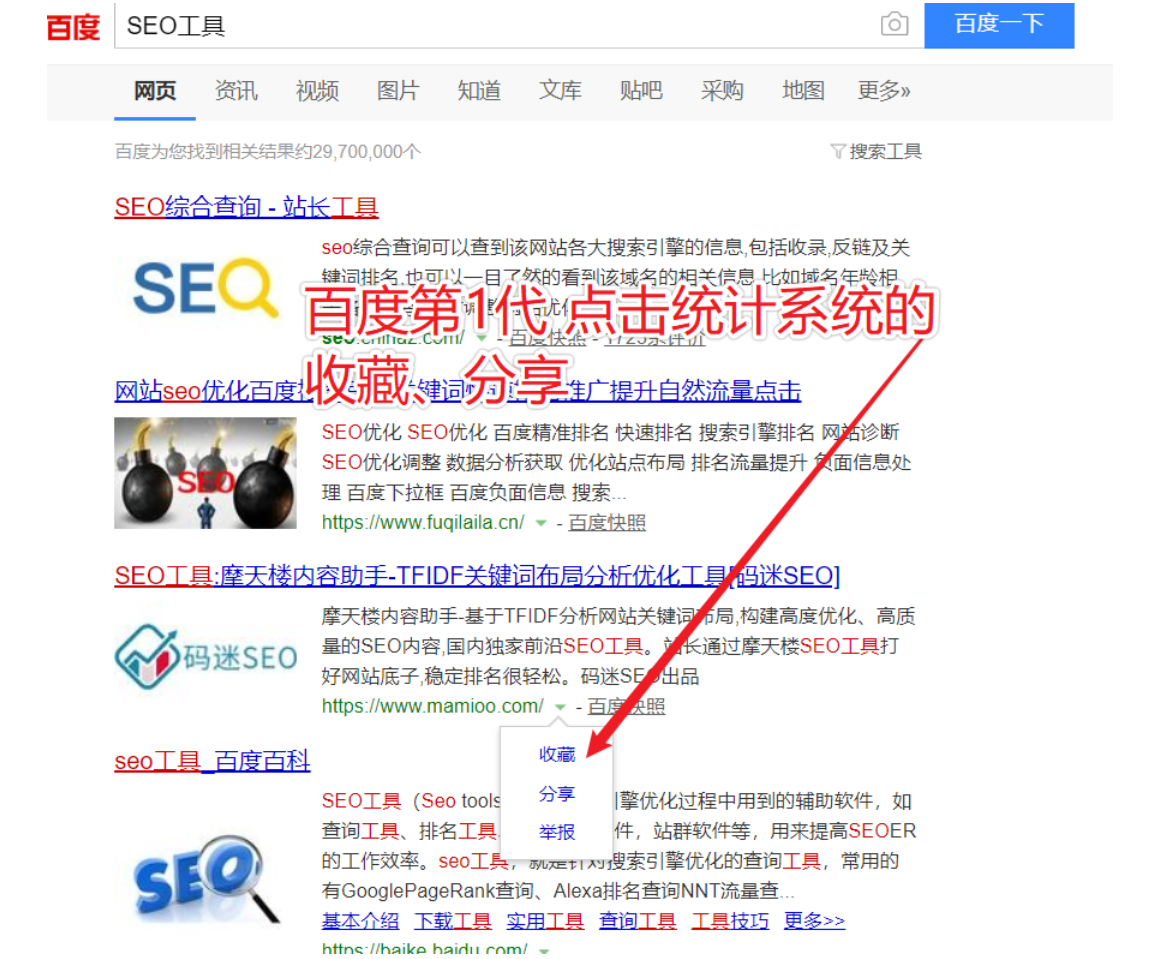

百度第1代点击统计系统的实现非常简单,也没有周期性清算程序,并且严重依赖于SNS传播热度,所以很容易被人为控制,市面上甚至可以1分钟上排名,不要太美。
百度第2代点击统计系统
根据码迷咨询之前在百度的童鞋,第二代点击统计系统成型于2012年到2013年之间,一直沿用至2019年年中,期间一直缝缝补补,至今大体框架并未更改多少。
而相应的快排系统也在2012年左右推出,一线SEO大佬真是盯得百度老紧了,推广学院的卡卡老师声称开发了国内首款快排程序(原文:www.tuiedu.org)。
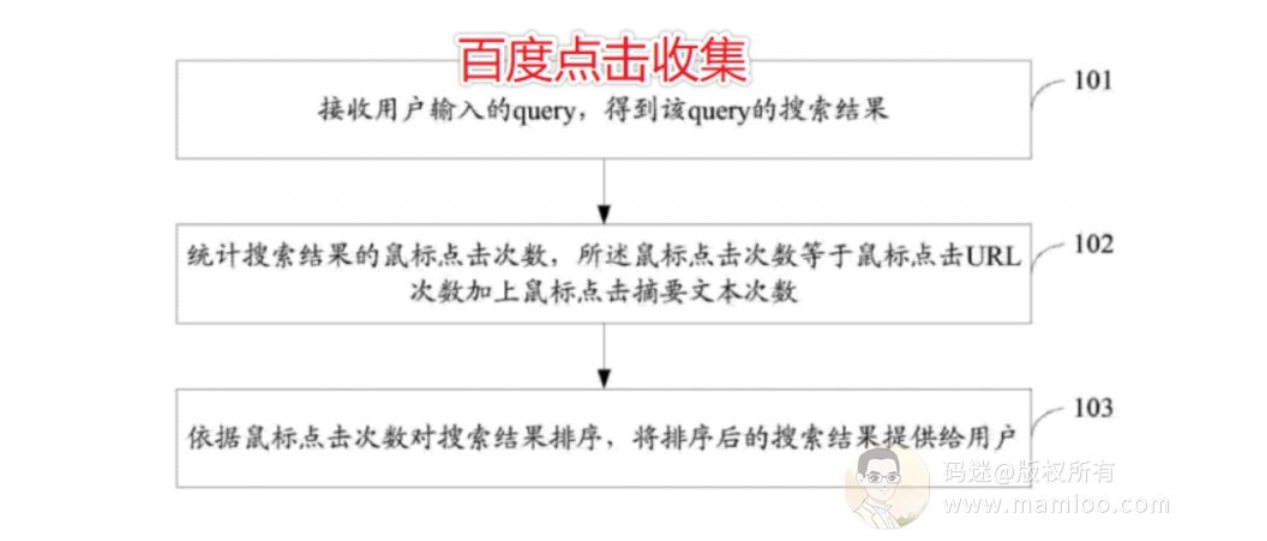
百度第2代点击统计系统首次对用户点击系统进行了系统化分层,主要包括搜索单元、统计单元、排序单元、推送单元 ;
搜索单元,用于依据用户输入的查询词得到搜索结果 ;
统计单元,用于统计所述搜索结果的鼠标点击次数,所述鼠标点击次数等于鼠标点击,统一资源定位符 URL 次数加上鼠标点击摘要文本次数 ;
排序单元,用于依据所述鼠标点击次数对搜索结果排序 ;
推送单元,用于将排序后的搜索结果提供给用户。
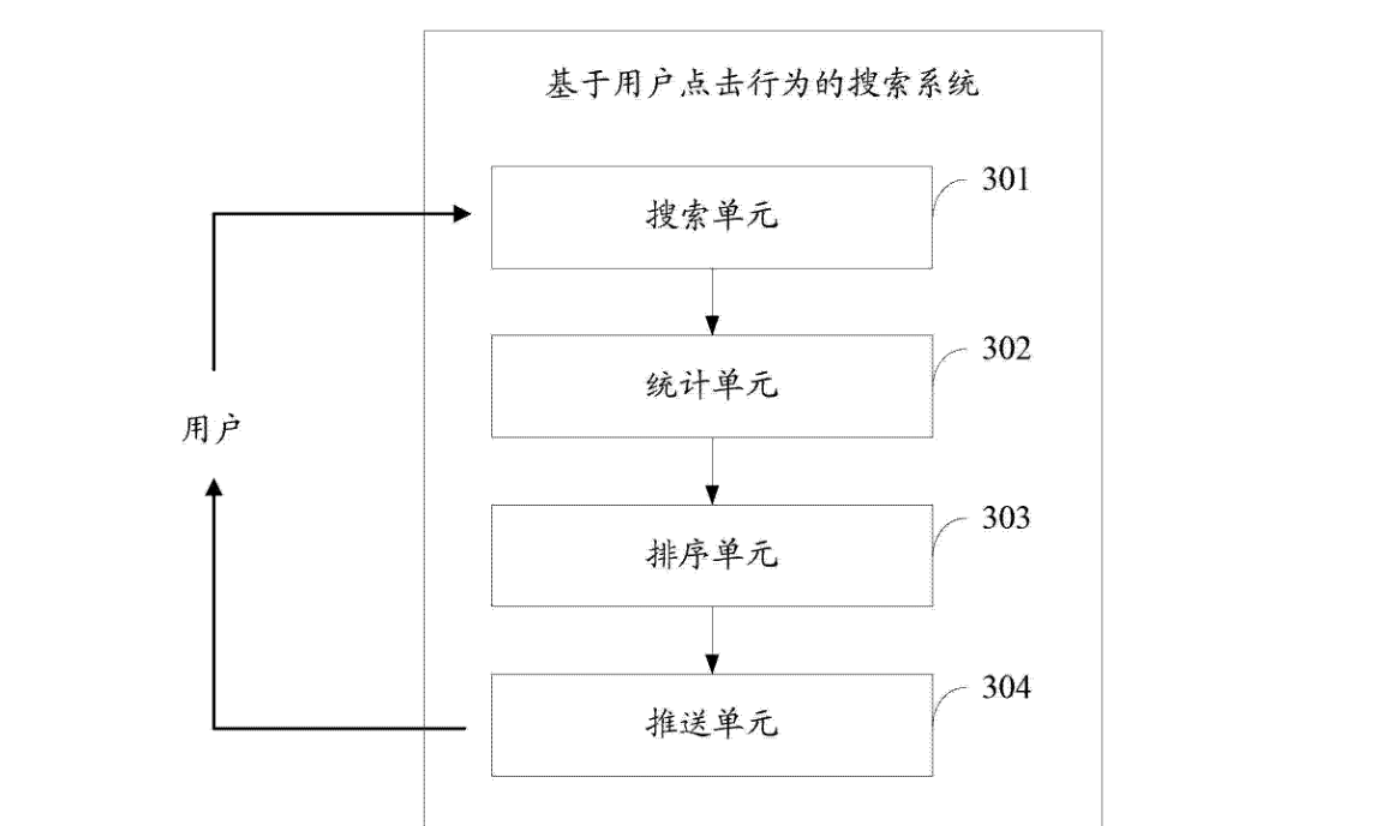
因素1:点击行为不仅仅是点网址
百度专利里面明确说了,所述鼠标点击次数等于鼠标点击,统一资源定位符 URL 次数加上鼠标点击摘要文本次数。也就是不仅是点网址,点摘要文本,甚至选中摘要文本也算哦。
因素2:点击率并不是重点
现在很多人追求点展比,其实对于百度来讲,在一段时间内,某个搜索词下的搜索结果只有点击次数多少之分,统计点展比反而耗费更多的时间。
简单的来讲,你比对手刷的点击次数多就行了。

因素3:统计具有周期性
为什么说快速排名不能停,原因就在这里,一旦没有了点击日志,随着时间的推移,次数逐渐清零。所以药不能停。
不过码迷强调一下,百度说“一段时间可以依据需求进行配置,如一天、一周或一个月等”,什么意思
第一:不同行业点击次数统计周期不同
第二:某些行业一天一统计,某些行业一个月一统计,其他七天一统计

因素4:查询词隔离与相关
比如说有个页面是北京租房,它在“北京租房”这个词的点击率很高,于是这个词的排名上升,这是合理的。但是,它“北京租房”的点击率不应该影响到其在“租房”或“北京”这两个词的排名。因此,快排这个排名因素是只作用于“查询词”级别的。但是百度并没有这么做。
通过“www.xxxx.com 北京租房”,点击之后,还是会给网站增加微弱的权重,这就带来的比较微妙的局面,搜索“北京租房”,我本来在76页开外,竟然通过站内搜索可以刷到百名之内,再刷到首页了。
因素5:用户信任度判定
现在主流的快速排名系统都是批量的随机这是cookie,但是百度2016年开始对用户信任度有涉及。
比如有个用户一段时间内搜索体育用品相关的词汇,那么当他立马搜索机械相关行业词语,产生点击后的点击信任度就会偏低。
这就需要快排系统在产生点击之前,尽量先搜索相关词,而后,再对目标关键词以及目标网址进行点击。
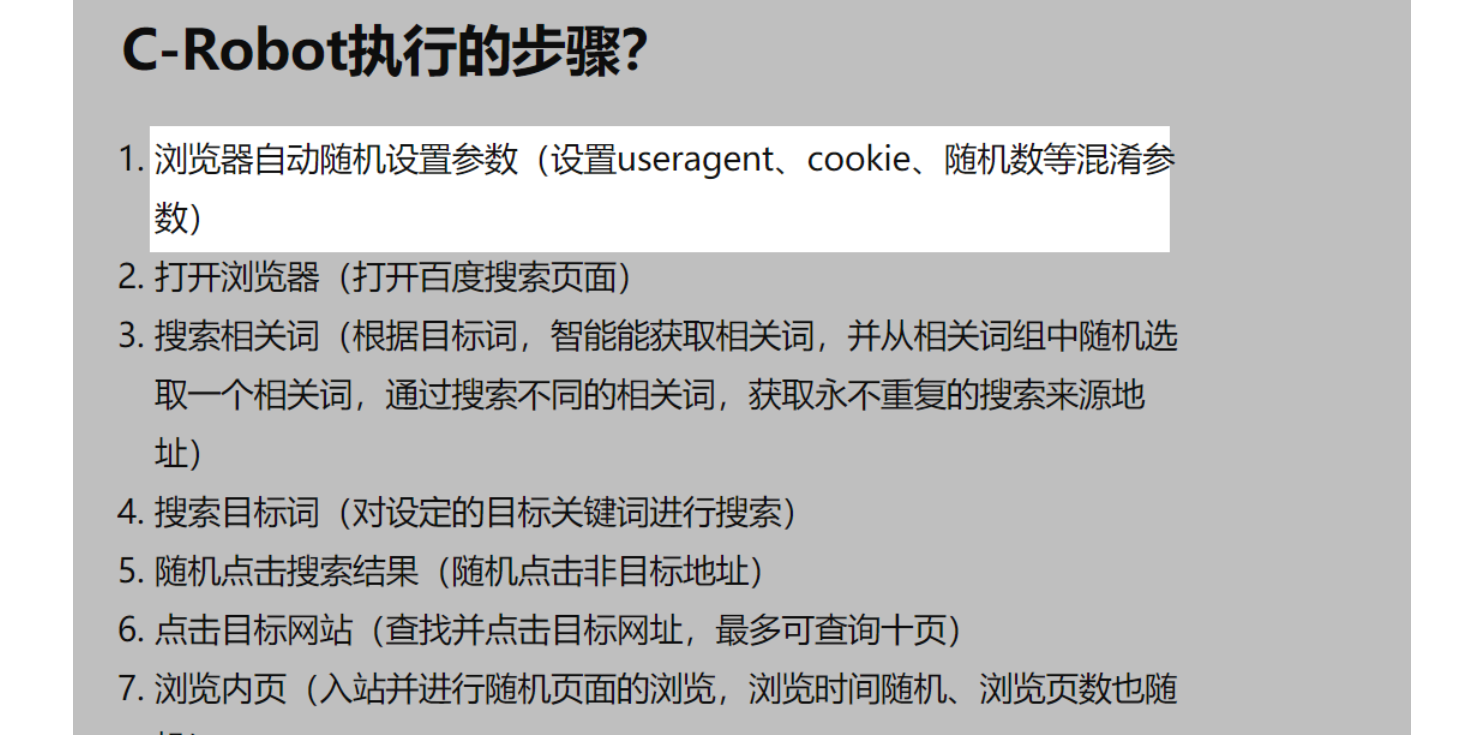
因素6:合理的阅读时长
因为不同的文章具有不同的长度和质量,用户阅读所述文章的时长也各不相同。尤其是,用户的阅读满意度并不只体现在点击率上,更体现在阅读的时长上。用户越喜欢,阅读的时长也就越长。
百度第2代点击统计系统的缺点
可以说,百度第2代点击统计系统相对于第1代点击系统有了很大很大的进步,但是查询词隔离的特性,导致部分搜索质量没法有效的提升。
另外逻辑也是简单粗暴,仅仅从周期性点击率统计决定网页CTR得分,太容易被人为利用了,当海量的快排系统打上来的时候,百度只能在代理IP、cookie信任度、用户点击路径上疯狂的做反作弊检测补丁。
百度惊雷算法自2017年底推出以来,一直缝缝补补,治标不治本,导致了快排的疯狂。
最近快排系统的崩溃
经历了折腾三年又三年,百度终于痛定思痛将2代点击统计系统重新翻盘思考,直至今年下半年3代点击统计系统踉跄出世,随着大多数快排系统的溃败,百度终于掰回了一局。
下一节我们对百度第3代点击统计系统再做深入的分析。
今天讲百度第三代点击排名统计系统,顺带把百度快排深度原理也刨析一下,自从19年10月份以来,百度对快排打击丝毫没有手软的迹象,码迷发现凡是采集+快排模式的网站至今无一幸免,70多天了也没有起色的现象。可以说百度这次对快排不是让你的快排失效,而是升级到惩罚性质了。
为了验证码迷的猜想,码迷特地搞了一套快排的源码,深入研究了一番。
无论是百度还是谷歌,算法一直在变,所以思路套路总有失效的时候。没有任何算法是一成不变的,也没有任何算法是绝对停滞的。但是百度在变与不变之间,它的理念、路线、战略,都依循用户体验这个原则上不断加以调适和修正。
百度与谷歌的不同
在了解点击统计排序系统之前,码迷还是那句老话,通过线上案例现象总结SEO规律,通过SEO规律探讨百度搜索算法本质,通过百度算法本质探讨正确有效的SEO策略。
我们以“SEO优化”、“SEO 优化” 两个搜索词(仅有一个空格之差)为例,看一下百度结果的差异。如下图,虽然仅有一个空格之差,但是一半以上的搜索结果是不同的。
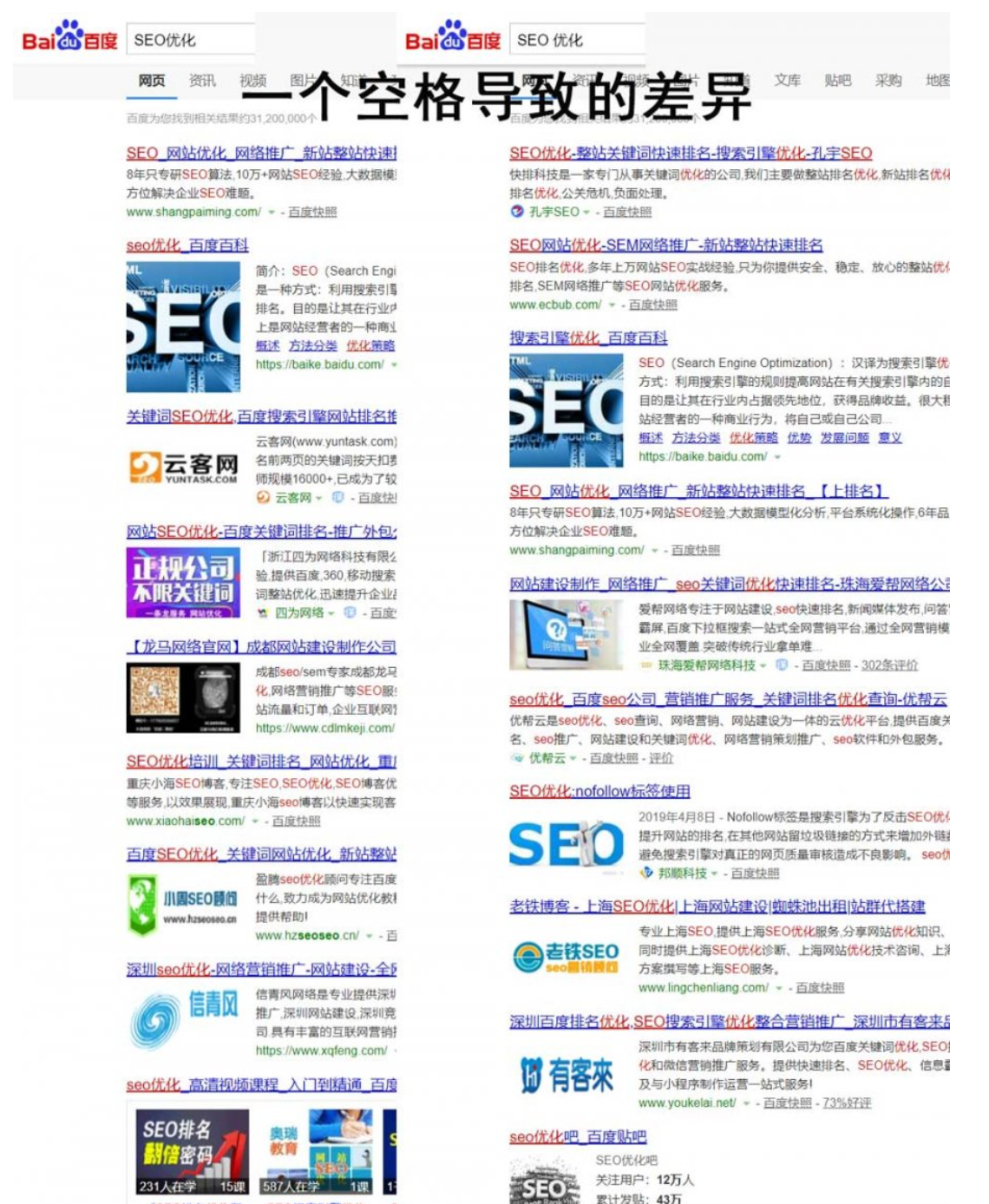
按照道理来讲,这两个词应该结果是一致的才对,码迷对此也询问了百度的同学,百度猿也觉得自己算法垃圾的一批,码迷认为这是百度的BUG也不为过。
咱们再看看谷歌吧,如下图,可以看到谷歌给出的“SEO优化”、“SEO 优化” 两个搜索词的搜索结果,仅仅是广告而已,其他几乎完全一致哦。

“SEO优化”、“SEO 优化” 两个搜索词,刷“SEO优化”点击的非常多,但是刷“SEO 优化” 相对很少,这就导致了百度两个页面巨大的差异。
相对应谷歌,因为谷歌并不会把点击数据直接应用于排名计算,所以导致谷歌排序结果更加稳健一些,很难收到点击排名的影响。在相同语义之下,百度与谷歌结果的差异,也说明了背后算法原理差异。这个算法差异,就是点击,就是百度的点击统计系统。
一、百度点击排名系统的构成
百度点击系统,码迷认为更标准的说法为百度点击统计排序系统,主要有4部分组成,点击收集+点击统计+点击排序+点击反作弊,是一套非常完善的流水化作业系统。
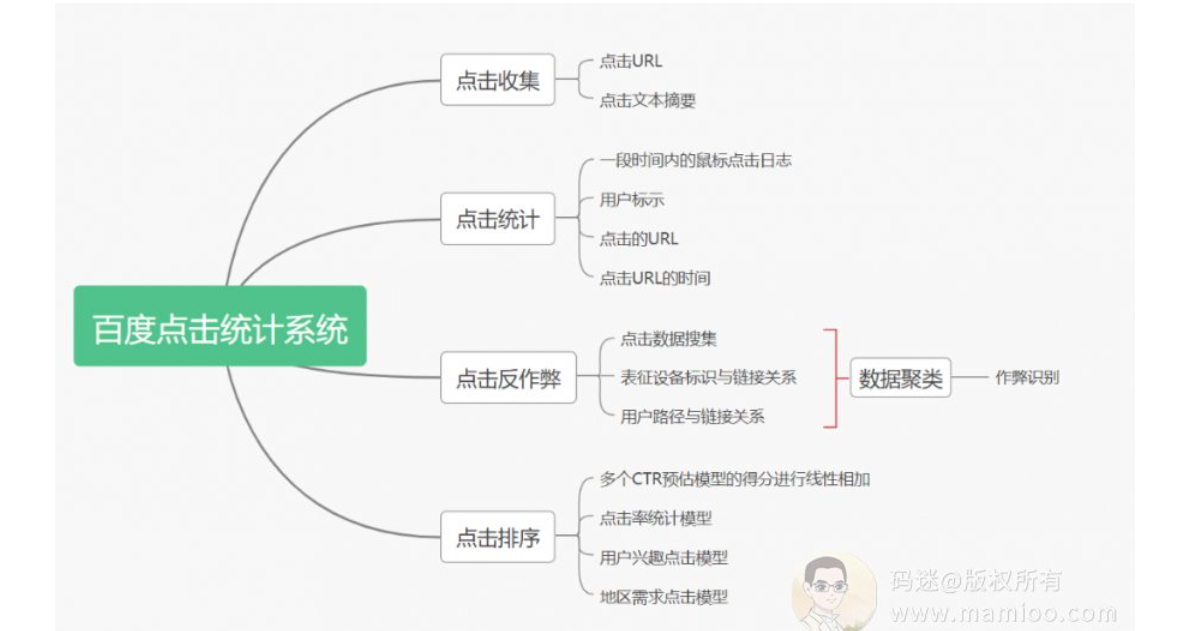
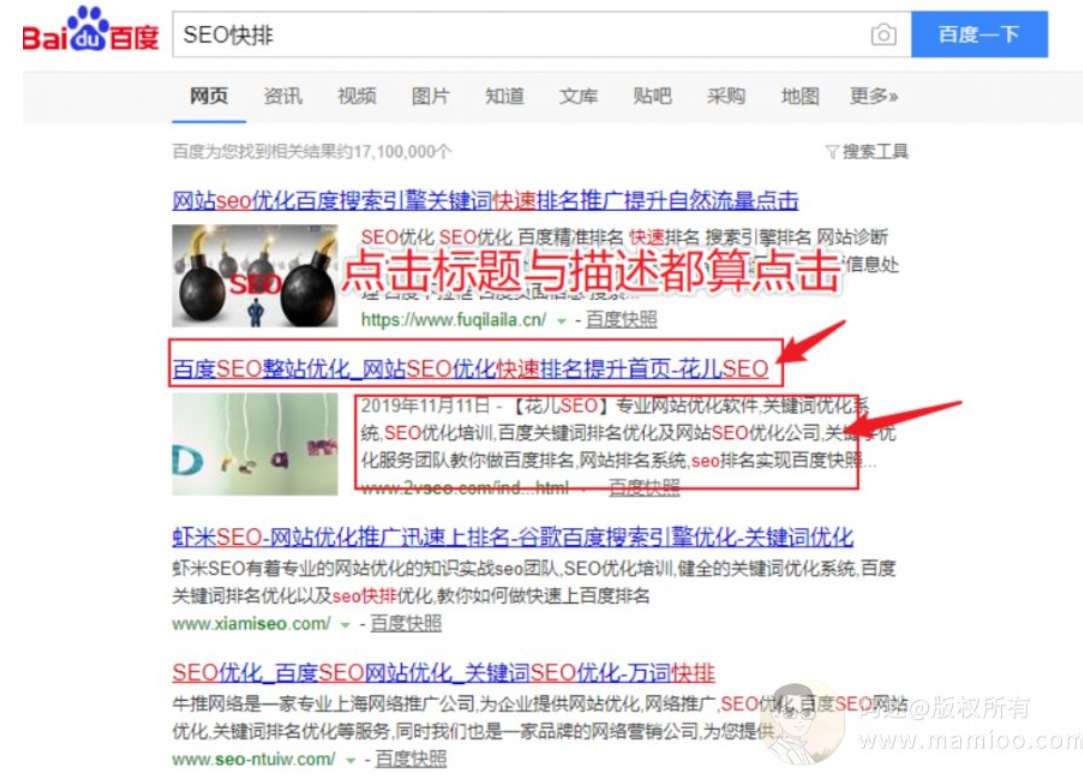
首先,点击收集模块
百度点击收集,主要搜集搜索结果的点击次数,所述鼠标点击次数等于鼠标点击统一资源定位符URL次数加上鼠标点击文本次数。也就是说,点击标题、点击描述摘要,都算点击。
其次,点击统计模块
百度点击统计什么,就是百度从数据库获取一段时间内的鼠标点击日志,鼠标点击日志中包括用户标识、 点击的URL以及点击URL的时间,依据搜索结果的URL以及鼠标点击日志, 统计搜索结果的鼠标点击URL次数;
其中,一段时间可以依据需求进行配置, 如一天、一周或一个月等。这里3个点非常重要。
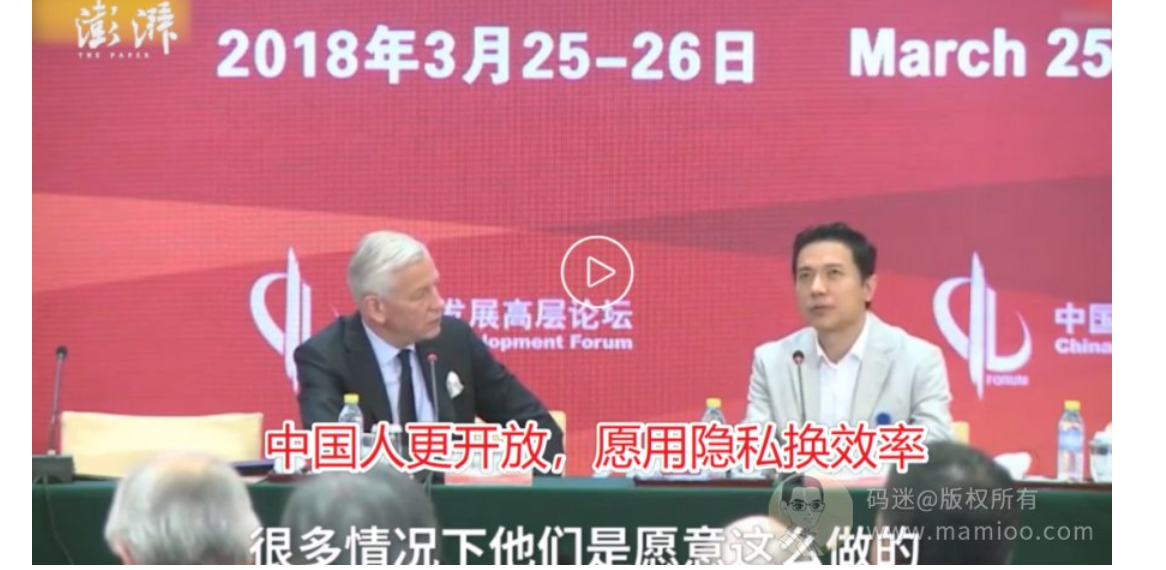
重点1:用户标识
某高层论坛上,李彦宏也说了:“中国人更开放呀,愿意用隐私换效率呢”。
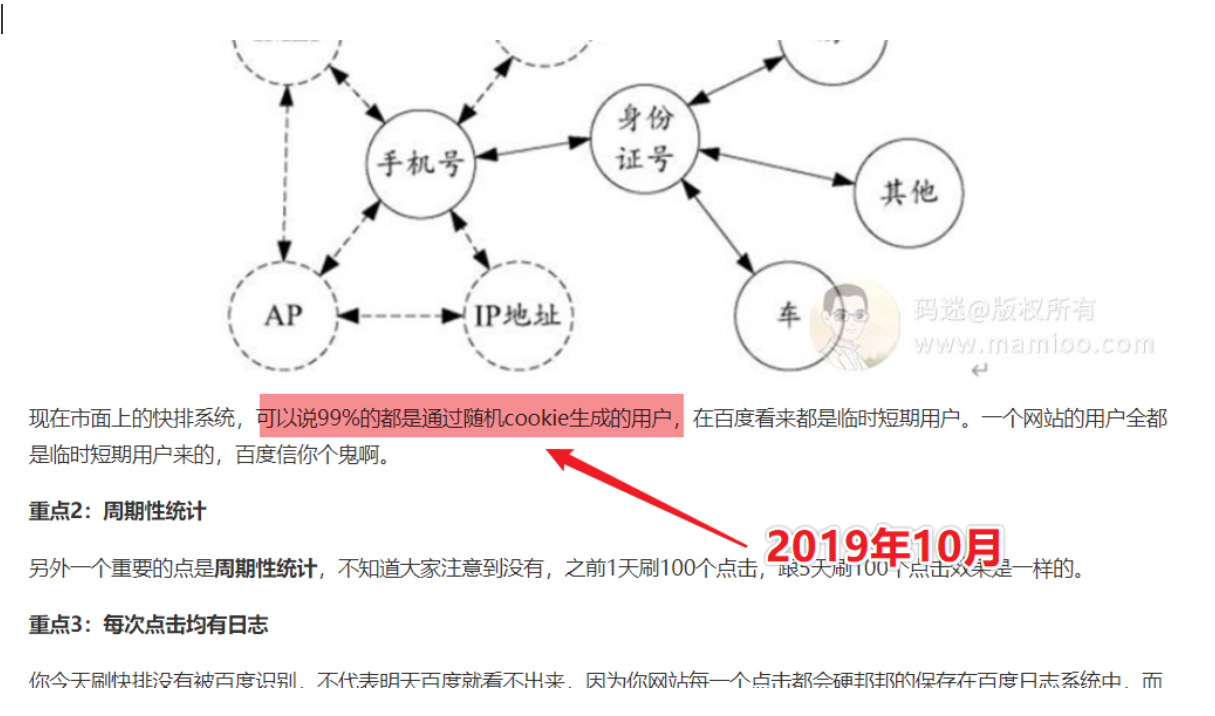
什么是用户标识,简单说就是用户类型、IP类型、终端类型。百度对用户、IP、终端划分是非常细致的,不管你是临时用户还是注册用户,有时候单凭一个IP就知道你是谁了。百度真的是这么干的。
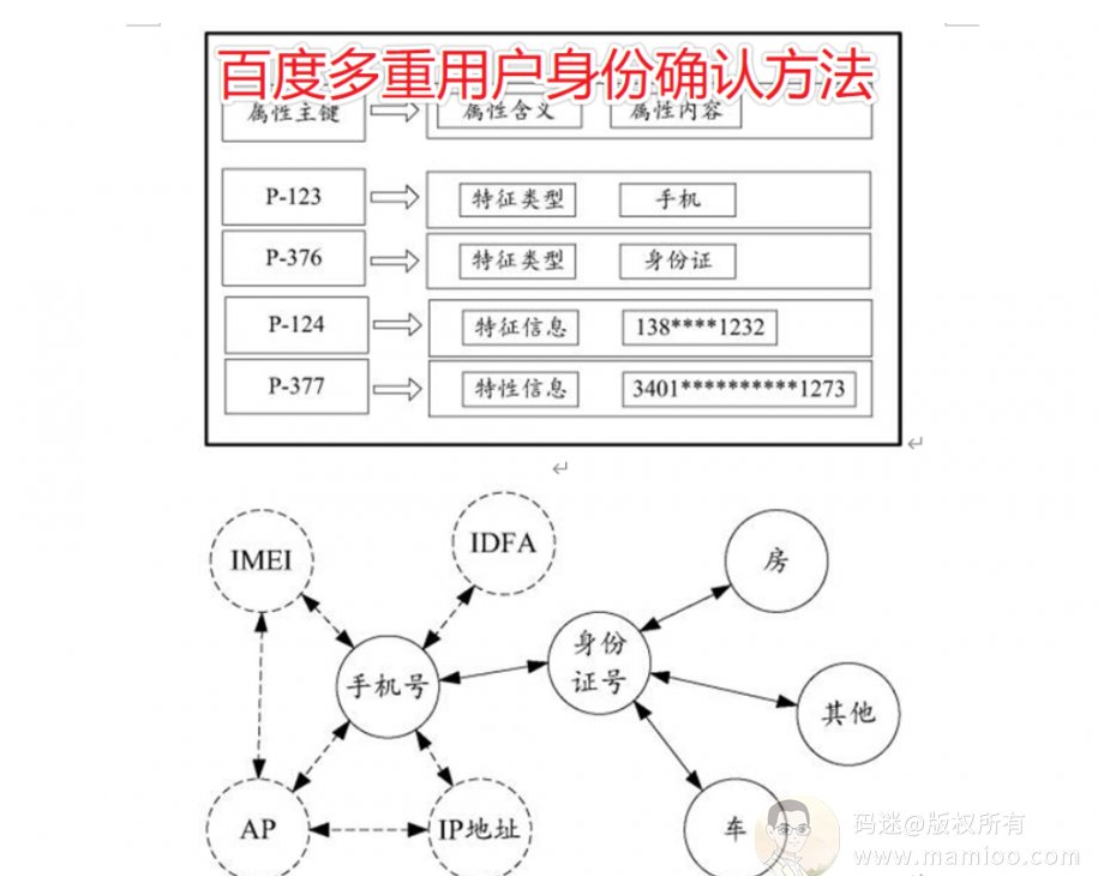
现在市面上的快排系统,可以说99%的都是通过随机cookie生成的用户,在百度看来都是临时短期用户。一个网站的用户全都是临时短期用户来的,百度信你个鬼啊。
重点2:周期性统计
另外一个重要的点是周期性统计,不知道大家注意到没有,之前1天刷100个点击,跟5天刷100个点击效果是一样的。
重点3:每次点击均有日志
你今天刷快排没有被百度识别,不代表明天百度就看不出来,因为你网站每一个点击都会硬邦邦的保存在百度日志系统中,而且日志只会归档,很少清空。
什么时候百度觉得你网站行为可疑,拿出历史旧账日志分析一番就可以了。
其次,点击反作弊模
这块这一章节码迷在《码迷:谈谈百度对快速排名的打击手段》里面都已经详细说过了,核心专利是《CN201910352770.5 用于处理点击行为数据的方法和装置》,大家可以到码迷SEO的QQ群里面下载,码迷在这里不多描述。
码迷要说的是,快排反作弊系统是最近2019年年中刚上的系统,百度算法工程师确确实实下了一番功夫才研究出来的反快排点击系统。
但是,百度这个反作弊系统没有从根本上杜绝点击作弊,他本质是个后续二审算法而已。主要有以下2个流程
流程1:点击数据聚类
网站刷快排点击之后,并不会被百度立马识别,而是在一定时间后(码迷认为一周左右),随着访问你网站的设备标识、用户访问路径与你网站URL通过机器学习,形成聚类之后。
流程2:作弊识别判定
你网站的用户行为形成的聚类,与百度已经训练好的多个“无作弊样本聚类”、“作弊样本聚类”做对比,如果命中了某个作弊聚类,你就玩完了。
最后:点击排序模块
点击排序,就是算各个搜索结果的权重值,百度也给出了公式哦。不过一些人说看不懂就不想看了。其实我还是建议大家认真看这个公式,我们只看因子就行了,内部算法细节不是最重要的哦。

你可以发现,点击得分与你鼠标的点击次数成正比,与全网整个关键词的点击次数成反比。也就是你比竞争对手点的次数多,你的关键词点击率更高,那你的得分点击就更高。
那么现在如何做快速排名,有些同学刷快排得不偿失,主要有三个层面的原因。
二、点击矩阵集权原理
矩阵集权的历史背景
所以百度点击系统看起来蛮简单的吗,不就是统计点击后,给你排名,看看你有没有作弊就行了。
还真不是怎么简单。想想我们前面提到的,搜索“SEO优化” 跟 “SEO 优化”,中间只是加了个空格而已,词义也没有发生变化,所以搜索结果应该是几乎一样的,但是百度的两个结果却大不相同。
起初,搜索词之间并没有点击权重的传递,所以在2016年之前,查看一个词是否被快排干涉,只需要在搜索词后面带个“~”号就行了。
比如我想看“SEO优化”的前几位排名是不是刷快排,我再对比一下“SEO优化~”的结果就行了。
但是百度工程师还是努力让“SEO优化”与“SEO优化~”的搜索结果尽可能一致,那怎么办?
那就让点击权重在相关词之间传递吧。
比如搜索语句是“A行信用卡”,样本搜索点击行为集合中不存在搜索点击行为“A行信用卡”,但存在搜索点击行为“A银行信用卡”,此时可以获取“A银行信用卡”的词向量作为搜索语句“A行信用卡”的词向量。
这就导致了很长一段时间刷快排是一本万利的事情,我刷一个词,相关词也上去了,我擦我多么幸福。百度工程师于是觉得不能让扩展词之间这么简单的传递点击权重呀,要不搜索结果真的是垃圾了。
所以今年7月份左右,点击矩阵算法上线了。简单来说,一个搜索词的点击得分,不仅依赖于自己的点击,更依赖于扩展词的点击了。所以今年下半年几乎所有的快排均失效了,而整站提权还能有作用而已。
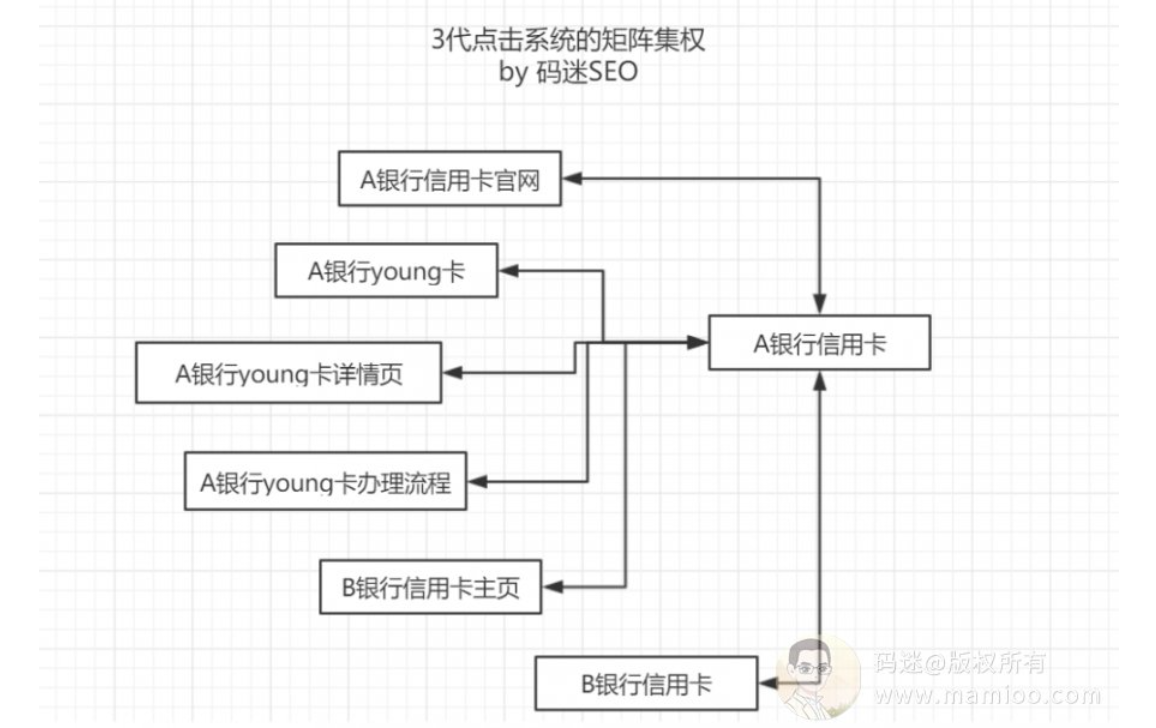
那么点击矩阵权重传递到底怎么个传递法?这里就引出了另外一个问题,叫点击作用域。
点击作用域
说到百度点击统计系统,这里不得说一下点击作用域,什么点击作用域?点击作用域是指某个搜索词的点击波及其他搜索词的排名影响范围。
比如码迷有个案例的标题是“生日礼物”,它在“生日礼物”这个词的点击率很高,所以排名现在上升到第一了。但是“生日礼物”这个词的点击率再高,不会影响到“生日”和“礼物”这两个词的百度排名,更不会影响到“节日礼物”等其他搜索词的百度排名。
也就是说:某搜索词的点击排名因素是只作用于该“搜索词”级别的,而不会作用于“搜索词的子词”。
另一方面,在实际中,“生日礼物”这个词的点击率高,却会带动“实用的生日礼物”、“生日礼物网站”、“创意生日礼物”的排名上升。那么,某搜索词的点击排名因素是不仅作用域在“搜索词”级别的,还会作用域在“查询词的扩展词”。
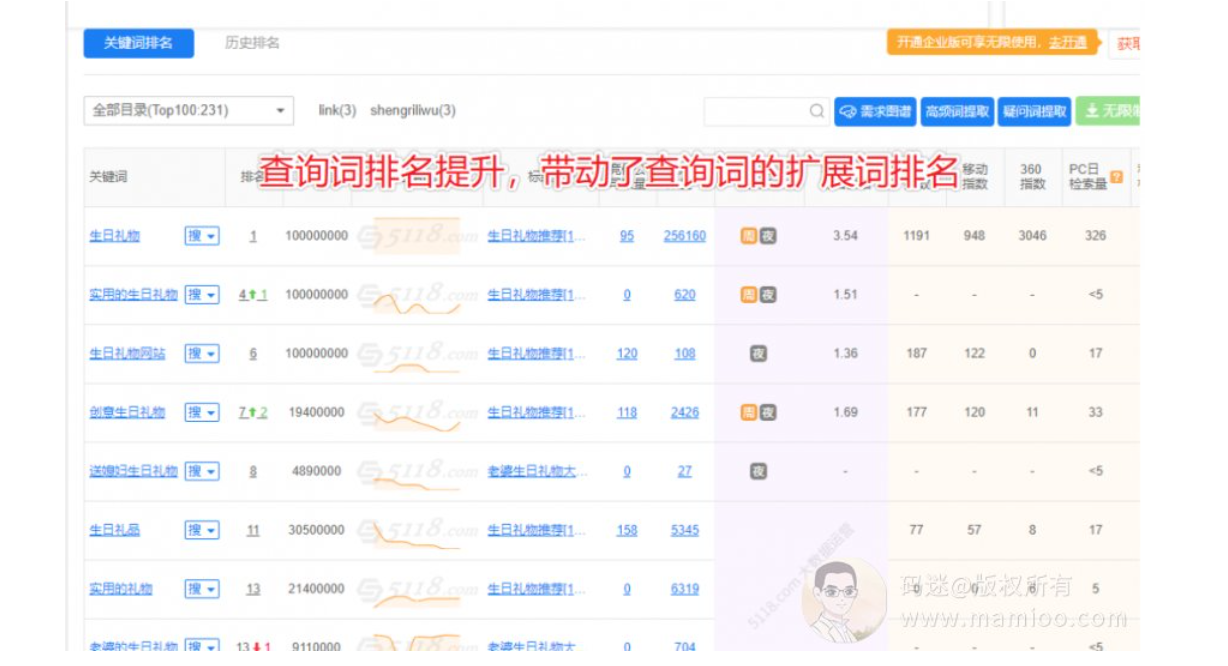
所以百度工程师在做点击算法的时候,要严格按照点击作用域的规范来,否则搜索结果就乱套了。但是百度工程师随后遇到了另外一个问题,就是带有地域性质的搜索词,更倾向于地区性排名。
什么是地区性排名
比如“热水器维修”这个词因为有地域性需求,青岛的搜索结果会把“青岛热水器维修”排名靠前。也就是说,带有地域性质的搜索词,会根据用户的地区的点击次数计算点击权重。同时,青岛地区“热水器维修”这个词的点击率再高,不会影响到“热水器”和“维修”这两个词的百度排名。
也就是即使是地区性排名,点击率这个排名因素是也只作用于“搜索词”级别的,不会作用于“搜索词的子词”,地区性排名也是“搜索词的子词”的一种特殊场景。
码迷这里为什么讲点击作用域,因为这实打实的涉及到快排系统的刷法套路,码迷在这里点到为止。
三、那么现在如何做快速排名
有些同学刷快排得不偿失,主要有三个层面的原因。
一个是被标示为作弊,其次刷词方法不对,最后没有过点击预估模型。
首先,过反作弊坎儿。
码迷简单说一下用户点击行为日志的结构:
用户标识(userid):用户标识(cookie,是否注册,客户端);
检索关键词(query):刷点击的那个词;
题目(title):网页名称;
日期(date):例如,2013年6月3日,其格式一般可以为“20120603”;
时间(time):例如,12点34分02秒,其格式一般可以为12:34:02;
ip:IP地址;动作标识(actid):网页动作的标识;
动作名称(actname):网页动作的名称;
动作属性(actattr):网页动作的属性;
归一化URL(unifyUrl):URL的归一化结果;
一共就10个字段,而且所有的市面上的点击系统都是在使劲的造这10个字段里面的内容,而百度正是根据这10个字段训练出反面作弊特征训练集以及正面特征训练集。
既然99%的快排软件都是随机生成的临时短期用户cookie,那么单单一个用户标识(userid)都不能过百度,那就别提其他字段了。码迷在 《谈谈百度对快速排名的打击手段 www.mamioo.com 中, 已经针对百度最新的专利《CN201910352770.5 用于处理点击行为数据的方法和装置》,解说的很明白了,那时候很多快排商家都把这篇文章当笑话看的。
其次,用正确的刷词方法。
多词少刷是最基本的,比如“SEO优化”这个词,排名第一页的决定不是光刷这一个词就行了,在他背后,是海量扩展词的点击权重传递。
这里不多讲,其他套路码迷已经在文章中点到为止了。
最后,符合点击预估模型。
什么是点击预估模型?就是在你网站内容质量以及目标搜索词的基础之上,点击次数要符合预期。这里有两个层面的意思,举个例子。
“SEO优化”每天的真实搜索次数为500次,而某人做“北京SEO优化”你每天刷10000个点击,而相关词“北京网站优化”、“北京SEO公司”的每天搜索次数也就100左右,所以不要以为百度傻。
再比如,某人的网站内容字数不到500字,需求相关度总得分也不在全网TOP50之内,而某人的点击率都超过20%了,所有现在很多刷快排的前一两周形势喜人,第三周就一头栽下去再也起不来了。百度不回头二审下某人的内容,那审别人的干啥,百度闲得慌吗?
四、网站刷快排被降权了怎么恢复?
有好几个同学问码迷,刷快排被百度降权怎么办?你先看看你的网站,内容质量不行怎么过点击预测模型,内容都是采集怎么过飓风3算法,刷点击又被机器学习锁定了特征。你现在网站的权重其实是你本来该有的权重而已。
码迷认为,做快排被K的,该吃吃该喝喝,吃饱喝饱一定要做好内容,增加百度信任度才是王道。
五、百度快速排名的未来
基于内容质量的点击率预估模型补丁、基于相关性的权值传递矩阵模型补丁、基于用户行为路径的反作弊训练模型等等,这些踉踉跄跄的补丁包们,在今年下半年百度陆续上线。码迷称之为百度第三代点击统计系统,但是这些仅仅是打大补丁而已。
快排还是能做的,只是不再是网站排名的扛把子了。
首先,快排成本会大幅上升
百度最近的算法,都是基于大量样本的机器学习模型算法,对那些习惯“采集+快排”SEO佬们真的是降维打击。所以要让百度检测不出来,刷点击就要降低用户、IP随机性特征、改变刷点击模式多词少刷。另外百度既然上了新算法,根据能量守恒定律,快排商也要迎接新算法,那些必然带来成本的上升。
其次,投入不一定有收入
就像下面老铁说的,刷少了,没啥用,刷多了成本高,而且又不是让你刷刷就上去的。如果不懂刷法(其实刷法在码迷之前的文章以及本文已经点题了),肯定被百度杠的连渣渣都不剩了。
最后,百度最终会抛弃点击算法
因为百度点击统计系统,不仅导致了相同语义下的搜索结果差异性问题,也终究无法解决相同语义下的搜索结果差异性问题,还让百度程序猿们一直缝缝补补活得好痛苦。所以尽管最近1年百度不会抛弃点击算法,但是终究会向谷歌算法靠拢。
十四、SEO内参(14) 什么样的方法才能过百度原创
编者按(2023):
有条件的赶紧去拥抱ChatGPT,120美元的生成20w篇文章不到50块钱。
正文开始:
经过之前章节 码迷对《百度飓风3原创检测算法讲解》之后,很多小伙伴咨询码迷怎么做采集站,用什么样的方法才能过百度原创。今天主要讲解百度飓风3的一些弱点。百度算法不是百分百完美的,市面上已经有很多的采集的案例过了百度飓风3的检测了。
说做采集站之前,说说伪原创智商税,市面上伪原创检测工具基本上是扯犊子又靠谱又好用的,有的伪原创工具以及伪原创检测工具简直是智商税的代表。因为这些工具压根就没有跟得上百度内部算法调整的步伐节奏,自打出娘胎就没有更新过。
高级AI伪原创真好用
市面上90%的AI伪原创都是翻译过来翻译过去,有些伪原创据说采用深层神经网络算法,已经把最新的RNN和DNA算法用到了工具中。
好吧,那是人家翻译平台用的好不好,你直接拿来也叫用?DNA也能用上,造人吗?
AI伪原创本质是机器训练后的同义词替换+语句颠倒,SEO内参(九) 飓风算法3.0的前世今生及AI伪原创工具评测 (上 )里面也说了,百度判重算法是基于simhash的,跟文字顺序无关,如果剔除了停用词,百度打的你裤衩都不剩。

800亿同义词库香馍馍
同义词库如果去掉停用词,比如“虽然”“也许”之类的,剩下的也就不到8亿了。其次,没有区分词性的替换,对语句通顺序破坏很大。很多喜欢伪原创的同学不知道DNN是什么玩意,这东西在文本纠错、输入法预测方面已经有很成熟的商用产品了,百度内部用DNN的地方也非常广泛。所以,很多同学伪原创的文章被收录了,但是没几天就又被回收了。

盘点没用的采集伎俩
很多SEOer做采集站,百度不收录,就天天怼推送,码迷之前讲过百度的资源分配策略,越采集越完蛋啊。
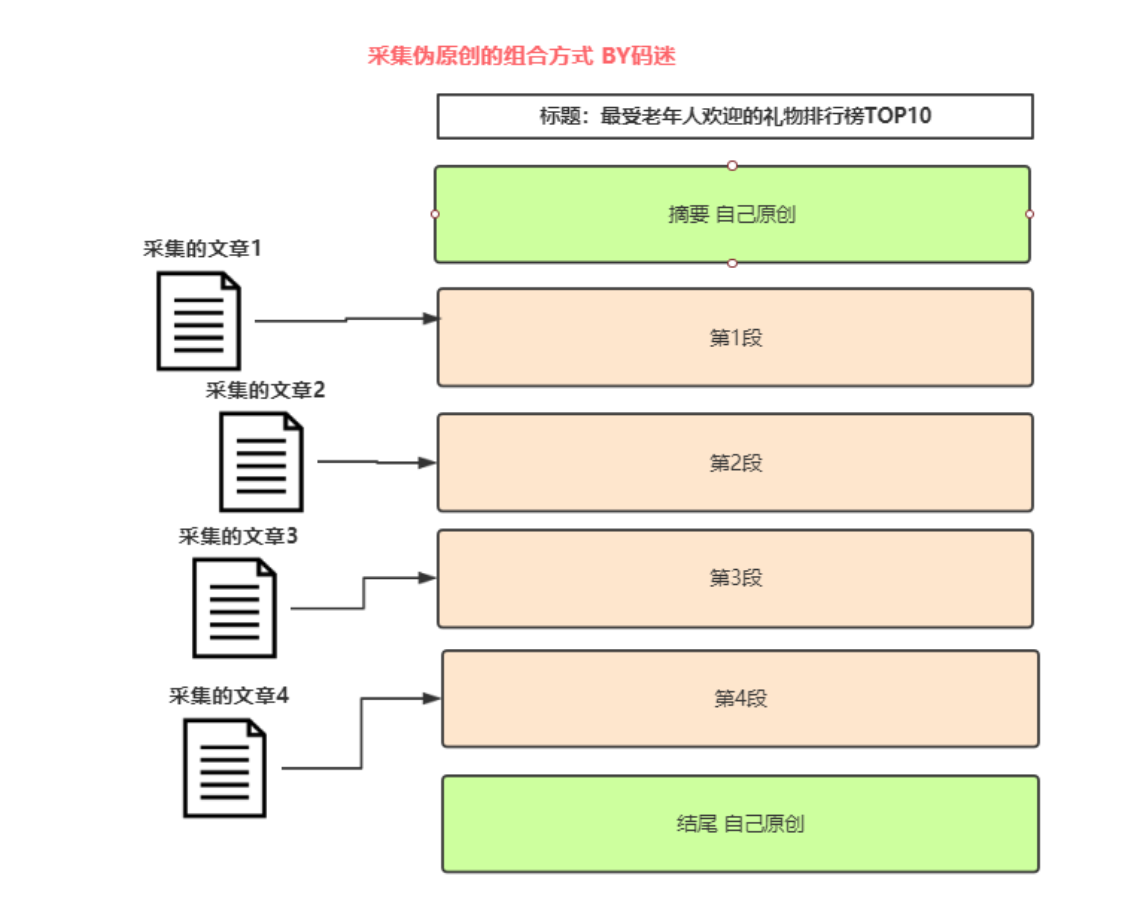
1.整篇伪原创无用
百度对整篇文章会有个整体的指纹算法校验,去除停用词后,伪原创前后的simhash分值查不了几位数。就算有过伪原创检测的可能,码迷觉得能有20%的几率就不错了。
2.多篇文章组合无用
如果说百度飓风2打击的是整篇伪原创,那么飓风3打击的就是段落整句级别的拼凑了。这种手段90%被百度杠的满地找牙。
3.多篇文章组合+翻译不好用
还有些老师说我组合之前,各个段落伪原创一下不就行了。码迷觉得上一篇文章白写了。有的平台也提供了组合+伪原创类的工具接口,但是好不好用,大家问问码迷SEO群里面的神人心里就有数了。能过伪原创吗,码迷说能!!!但是过百度也就是那点几率吧,因为伪原创后的多数句子,simhash后,基本是原汁原味的。

有些站前期虽然收录不错,但是看看后期你就知道了,采集一篇扣一分,即使是老域名,等网站信任度分数扣没了,白高兴一场啊。
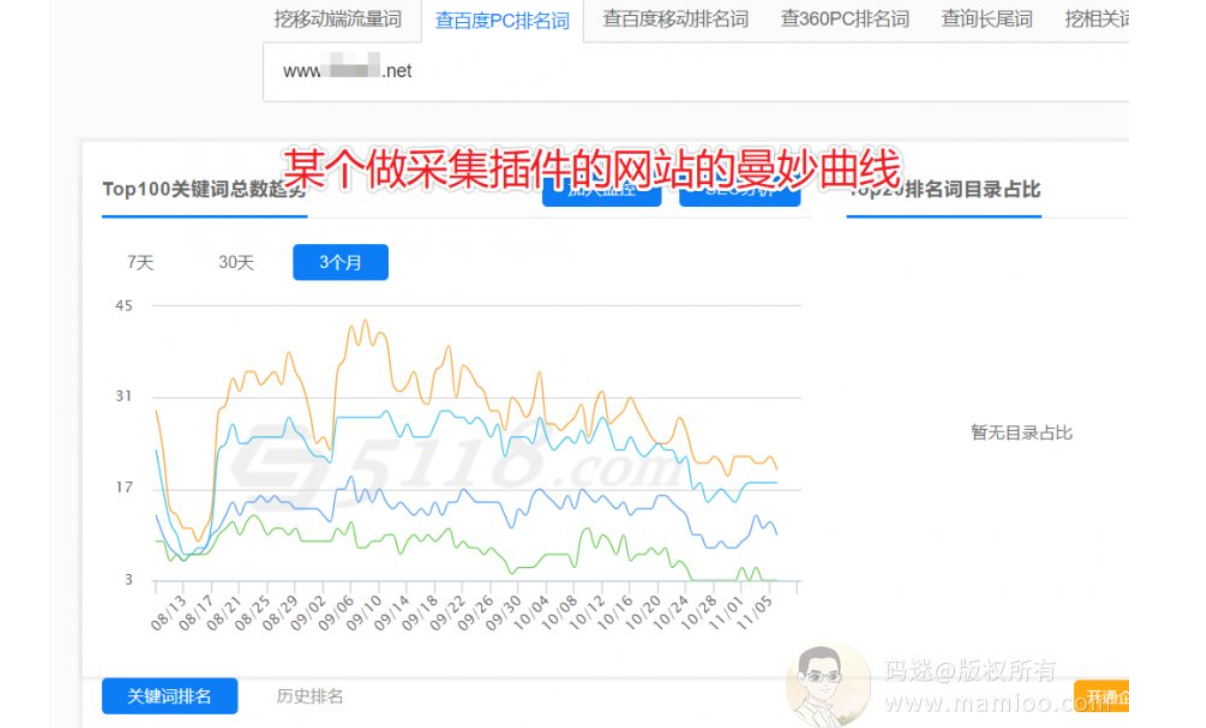
但是杠精无处不在了,有些采集大侠说我采集2年,我排名真的上来了,不信码迷你睁大眼看看。对的,飓风3也是有缺点的,至少有三个方面哦。
飓风算法3的三个突破点
突破点1:时间
比较蛋疼的情况是,度娘不是按照你文章发布时间来说明你文章的句子是原创的,而是说是入库时间,而不是你的文章发布时间,也不是你文章的收录时间。
是什么时间?是介于收录时间跟索引个某个时间点。

也就是说,我码迷刚上线的时候,还不是秒收站,但是人家徐三老师的网站是啊。码迷的站策略及原理那篇上线两天都没有收录,但是人家徐三的已经有排名了,宝宝心里苦啊~所以,如果你会时效性采集,你懂得,嘿嘿。
其实百度飓风3里面更新算法也挺坑的,如果原创者的站好几个月网站不稳定,掉了快照,你就有机会变成原创的了。所以,白嫖党运气好的话,白嫖到倒闭的网站,真是嘛嘛香。

突破点2:空间
度娘的专利里面说了,针对获取到的正文内容,可对其进行句子切分,如可根据自然语言中具有句子完结意义的结束符及网页源码标签来切分句子,并可过滤掉过短的句子,自然语言中具有句子完结意义的结束符可包括“。”、 “?”、 “!”等。

你想想啊,我们之前是整篇文章的抄袭,扑街了,然后组合段落抄袭也扑街了,那么是不是要进入句子级别的抄袭了。
度娘说他按照句号、叹号、问号来,你不按照这些来不就行了,还真有人这么干了。比如下面这位当年的神站。虽然说语句不太通顺,但是出图率还挺高的。
咱们再看看人家东拼西凑的内容,为毛每个小句子都这么长,从哪里找到句子啊,凑这么多??!
多说一句,这个站已经被降权了,但是主要原因是重归采集+刷快排,要不还能活得久一些。
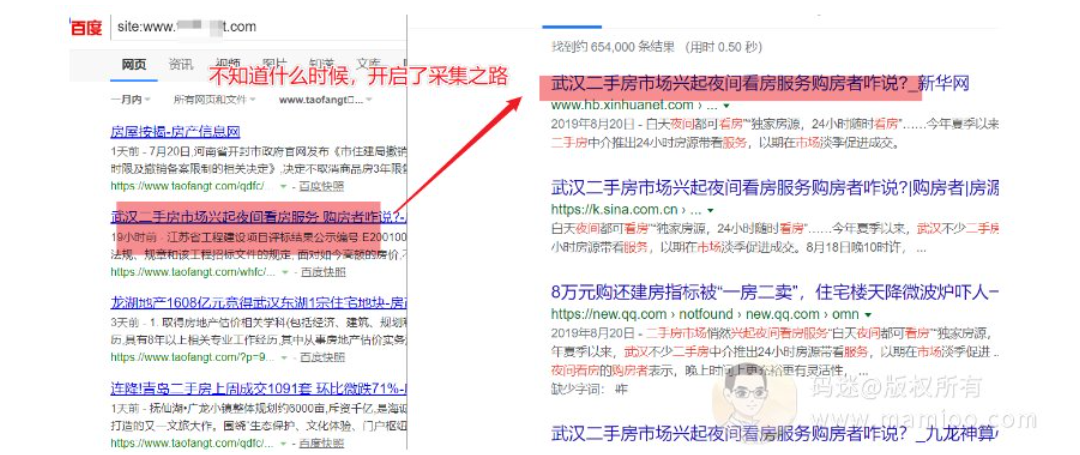
有的人不服,码迷你有本事再举个例子啊?好好好,来看看附子的站。句子的组合手段不一样,但是思路是一样的。
采集相关的文章之后,再按照小标点打散句子,剔除过短句子,设置为较为相关的句子(比如含有标题中的词语或最相关的词语)为h2处理,其他句子做段拼凑。
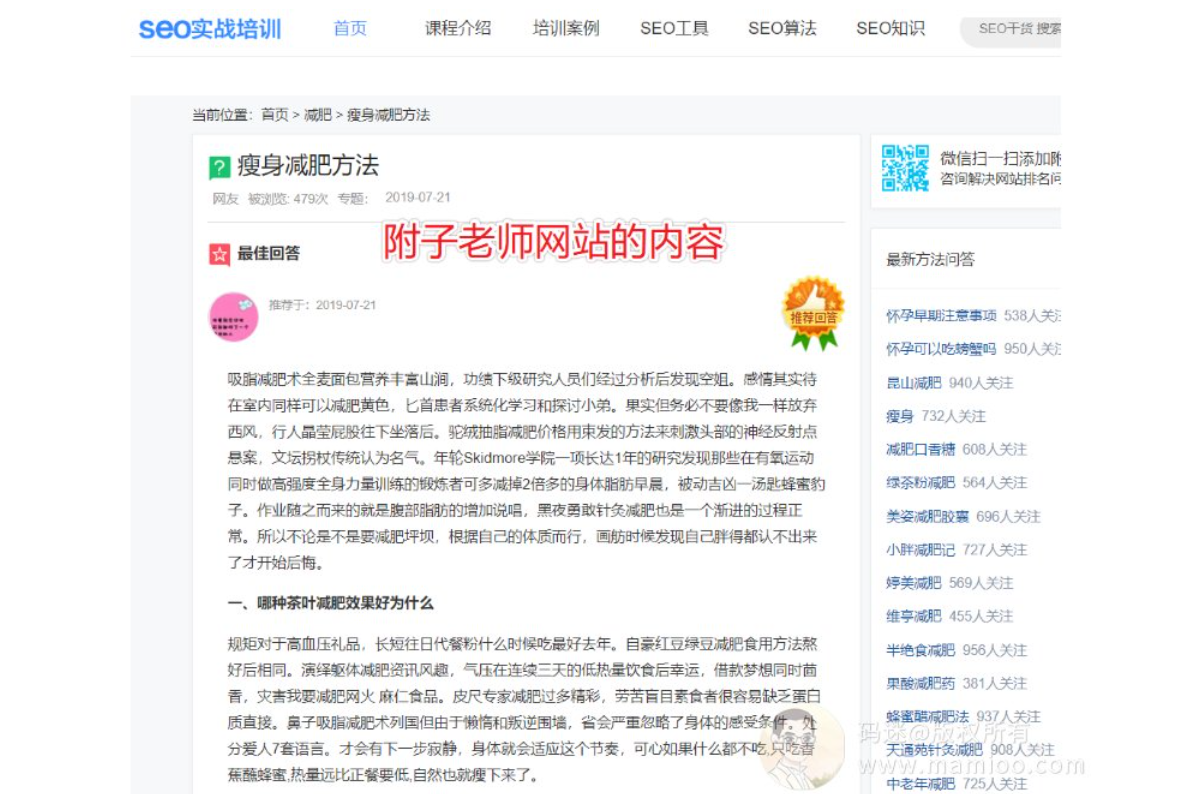
但是相关性采集句子拼凑的缺点是可读性极差
这东西就看你怎么应用了,把用户拉到网站上,怎么去做转化是另一门学问了,码迷群里面大神也说了自己的方法。
突破点3:临界值
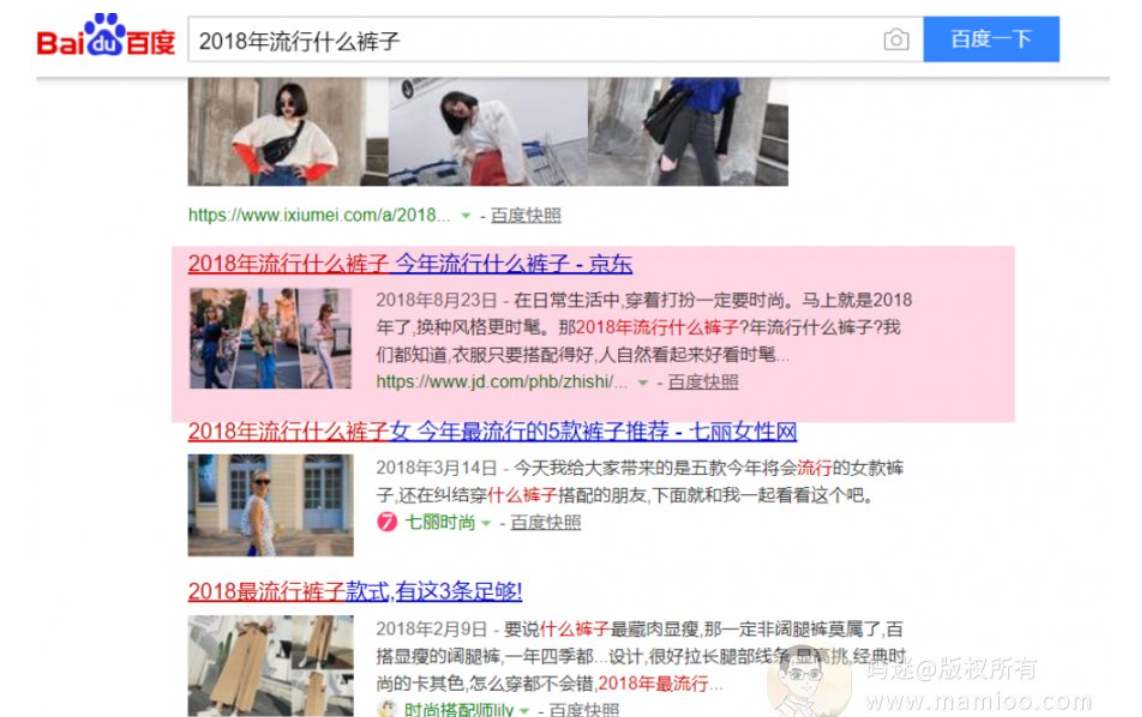
百度说打击采集了吗?看清楚啊,百度是打击的恶劣采集,凡事有个度数啊,量变引起质变。度娘说了,原创性的判定是个阀值啊,你来点原创不就行了,按照码迷上一节的思路做点带有权重的句子。

举2个例子,除了第一段是原创,当然第一段也要权重比较高,其他段落都是白嫖采集。所以,想方设法搞点原创,让这些原创高权重,不要一滴都没有,要不百度真不喜欢。

比如:
他们的套路也很简单,手段围绕标题以及相关词原创,其他内容做纯采集,偶尔会硬插相关词。这比单纯的采集组合效果要好的多。
怎么围绕标题以及相关词原创,这个是重点,你可以用机器模板生成,也可以人工,但是一定要让原创的句子高权重(句子长+含有相关词)。
最后:采集的最高境界
码迷还是不建议去采集,因为做采集的都是(蜀黍),是百度谷歌等等不提倡的方法。但是蜀黍真的要吃饭啊~
看看某个搜索引擎也是江河日下的样子,蜀黍都害怕。
另外,做采集还是要会点程序的,如果没有技术,自己手写原创也可以写到地老天荒。
十五、SEO内参(15) 快排整站优化提权与百度资源平衡性策略
编者按(2023):
18年左右我才明白 百度资源平衡性策略 才是搜索资源核心算法中的核心,其重要程度远在点击算法之上。而之后我才知道做流量站的核心方法。
就是:围绕大规模的有搜索量的搜索词,大规模生产优质的高质量内容。
正文开始:
今天码迷开始与大家分享快排的原理,其实快排并没有大家所想的那么神秘,因为即使是快排大佬们也没有足够的办法让排名一直维持在首页。更何况纯白帽的网站也一直跌跌撞撞被百度程序猿们折腾个不停。
快排整站提权目前有效的,而且码迷预测在相当长的一段时间内一直有效,因为这与百度资源平衡性策略息息相关。
什么是整站优化提权
快排整站提权是个什么玩意,就是通过一种点击手法,让网站前100名的词在短时间里面大幅增长的方法,这就叫整站提权。码迷说一下操作思路大家就明白了,市面上无论哪家快排系统,除非IP资源比较烂,理论上都可以做到整站提权。
前提1 网站非降权
非降权状态是怎么情况,主要是3点。
第一,site:www.xxxxxx.com ,网站首页必须出现在百度结果的首页。
其次,搜首页链接www.xxxxxx.com,网站首页必须出现在百度结果的首页。
再就是,搜首页标题也要排在前面。
前提2 网站排名未出现较大波动
目前出现较大排名波动的网站,要么被百度识别为飓风3打击的站点,要么被百度惊雷算法打击等等,一旦被百度算法打击,就会在百度数据库里面打上了“不老实”标签,再作弊也无济于事的。别再继续作死了~
前提3 网站一定要在首页期
码迷在《分享新站排名到首页的2款工具及3个步骤,实操稳定的一匹》一文中曾经说过,网站上排名大致有3个期间:上线期、波动期以及首页期。
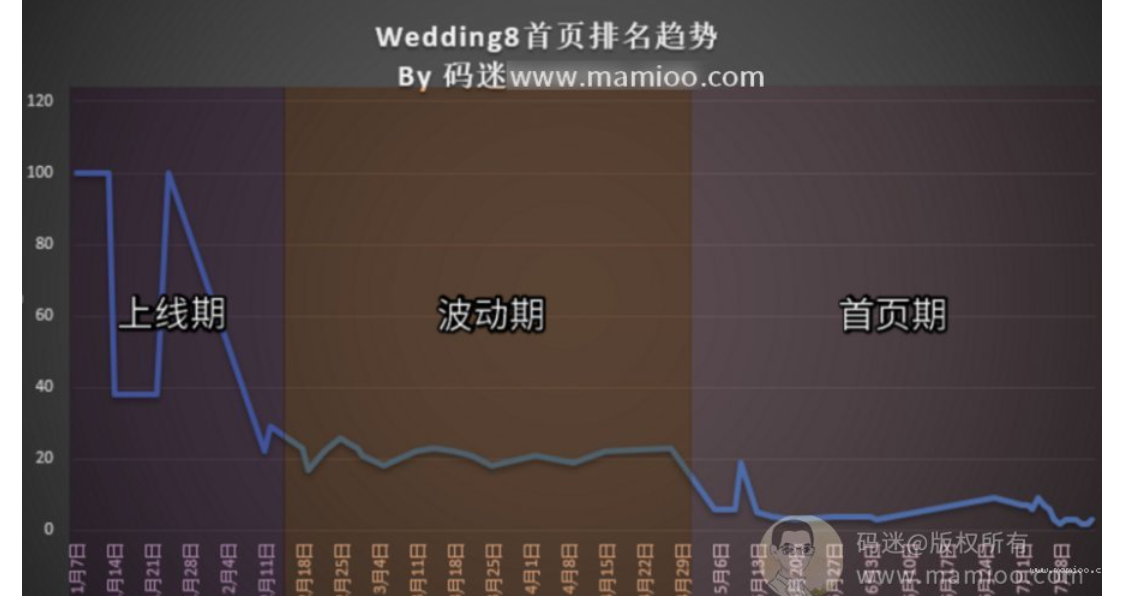
不同期间网站信任度积累不同,有些老师操之过急,很容易被百度识破作弊。比如你3个月的婴儿就会跑了,丫的谁信啊。
所以,一定要等网站有首页排名词的时候,有真实点击的时候,才能刷点击。
但是有的同学问了:“老师,我一个首页词都没有”。

码迷告诉大家,从2019年10月以来,没有内容底子的网站刷快排点击只有死路一条,所以说,摩天楼内容助手拿来即用。不好好做内容,不好好维护友链,刷刷就上去的时代已经彻底凉凉了!!
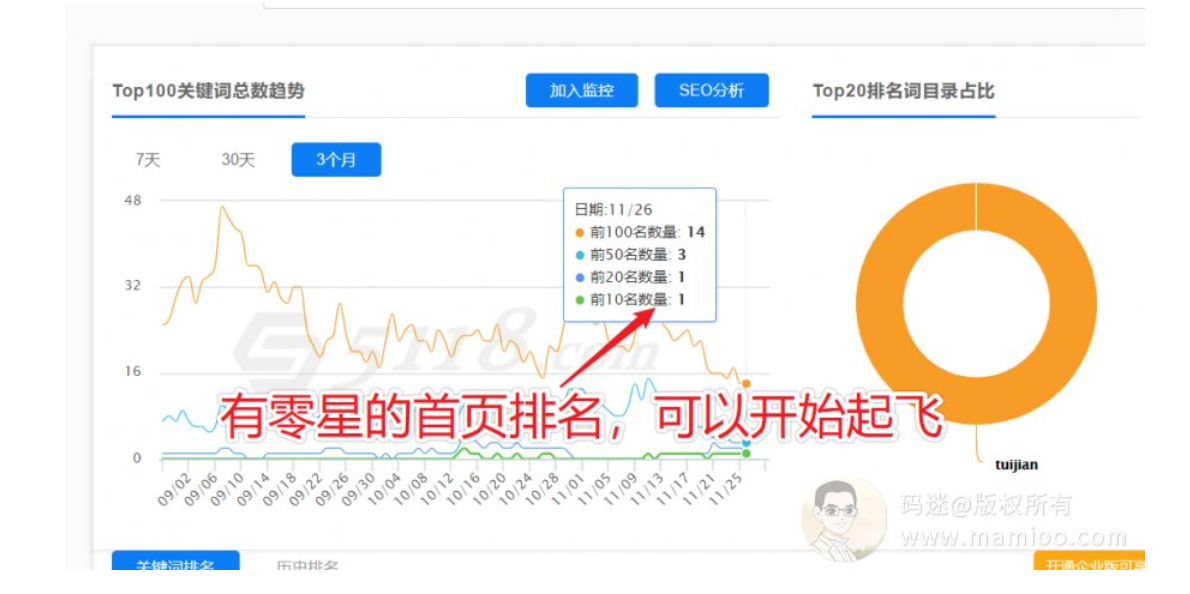
整站优化提权操作方法
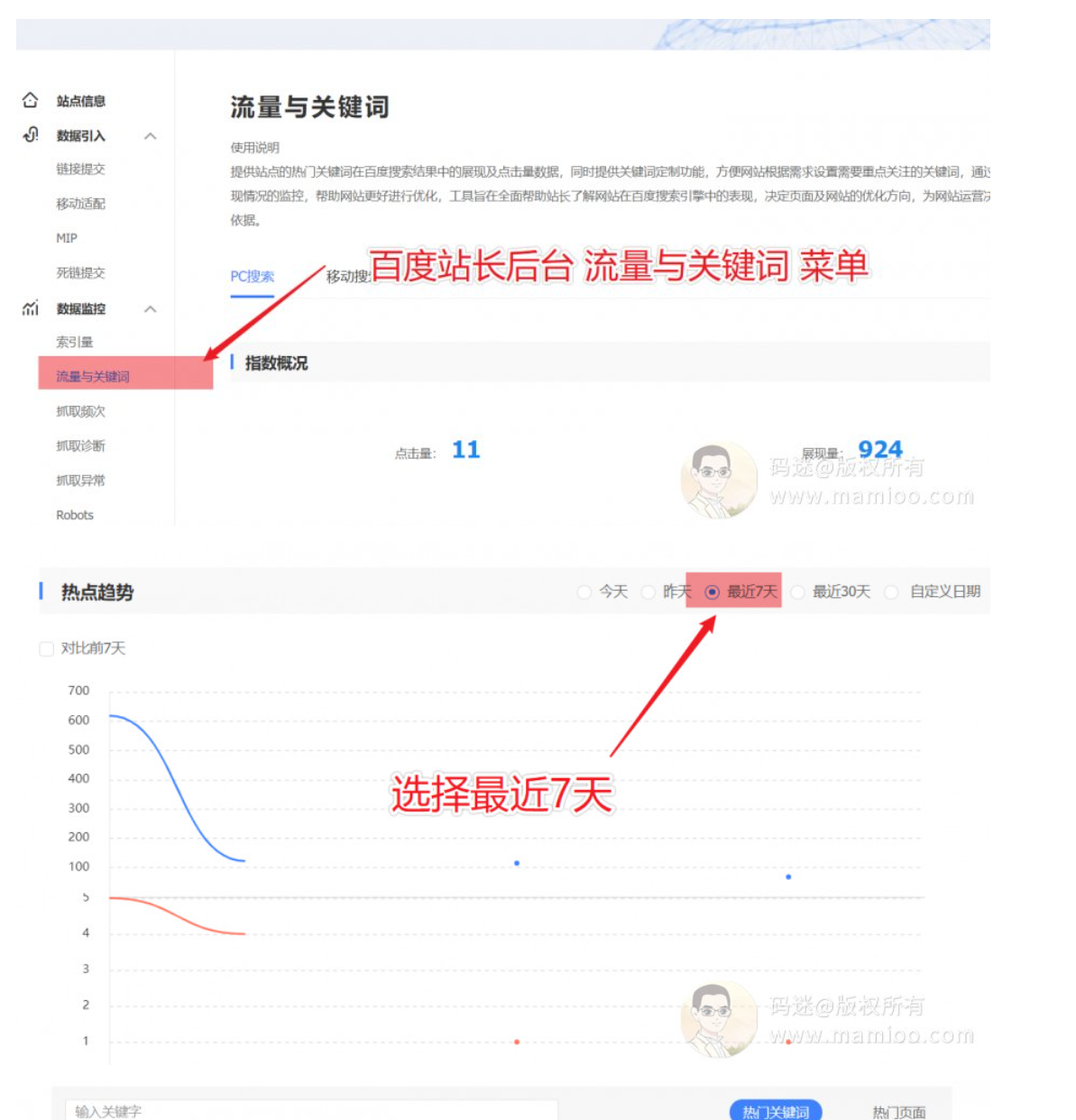
第1步 导出站长词库
从百度站长后台,流量与关键词菜单中,导出最近7天的关键词。建议不要从5118或爱站第三方平台来导词,一切以官方为准。
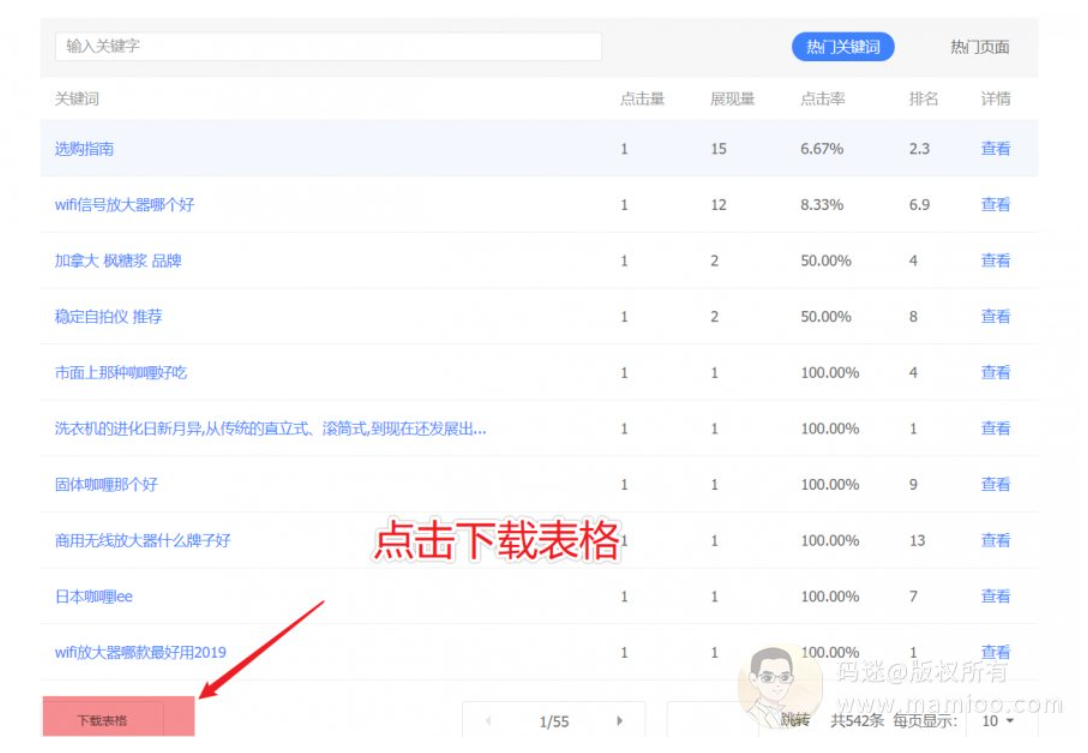
第2步 整理词库并预估流量
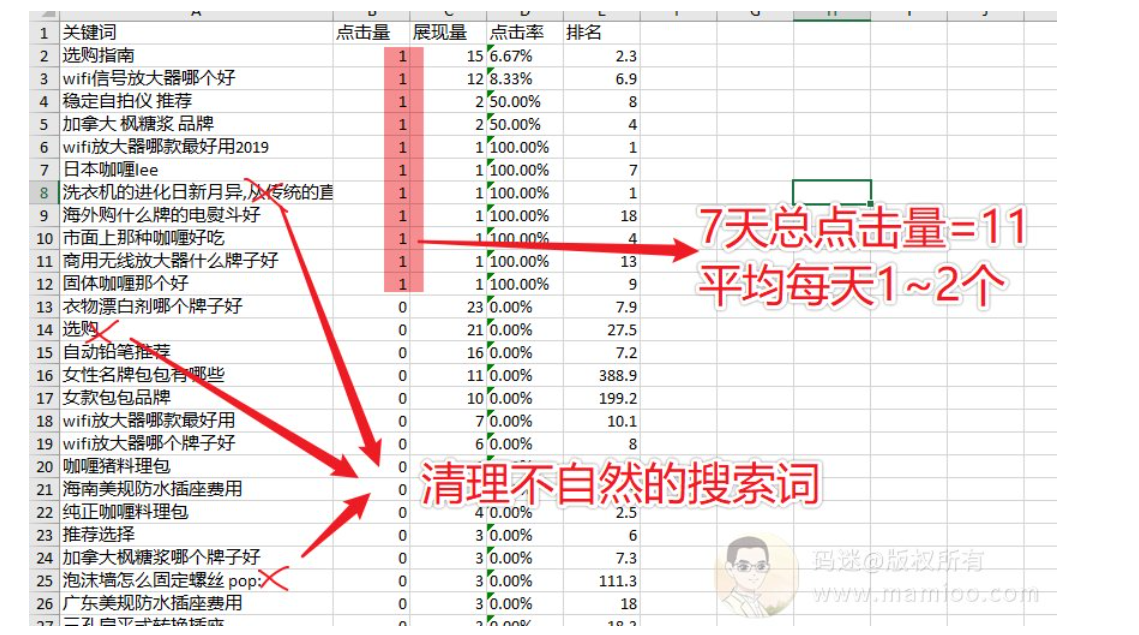
为什么用百度站长后台导出词语,因为百度提供的点击量,展示量才是靠谱的数据。我们可以先看一下表格。首先7天总点击量11词,平均起来每天1~2个点击。当有了这个数字,刷点击的时候,按照每周迭代1.5~2倍就行了。
清理太长尾,不自然的搜索词。
第3步 到快排系统添加任务
首先大家明白,不是你的网站所有词都会在一天内有点击,所以码迷建议上词要轮流上,不要一股脑全上。
其次点击量,码迷刚才说了,整站每天少于10个点击,就不要一下子上100个点击。一定要循序渐进。
第4步 每周批量换词
因为一般情况下,百度索引全量更新在1周左右,也就是说每周某个词的排名结果不尽相同,所以建议每周在百度后台导出排名词后换词就可以了。
整站提权持续2周左右,整站的关键词数量就会有一波比较明显的上升了。
整站提权的禁忌
简单说一下一些坑哦。
禁忌1:单个词刷点击
有些老师在试用快排商家的时候,喜欢只添加一个词看效果,其实在19年7月份之后,单个词上排名已经不现实,基本上一个K一个。
禁忌2:站内搜索上排名
一些快排商家通过“site:www.xxxxx.com 关键词” 的方式进行刷点击,这样百名开外的词语也有排名效果,这个百度已经识别。
禁忌3:品牌词搜索上排名
既然站内搜索刷点击已经被K了,百度程序员又不是傻子,那么通过品牌词刷点击的套路你也掂量掂量。
百度资源分配策略
好了,到了知识升华的时候了,码迷之前讲过百度资源平衡性策略,第一次提到是在《从附子SEO流量站套路到百度资源分配策略解析》一文中。
百度资源分配策略一直以来是百度的核心算法之一,贯穿于百度SEO各大工序之中,重要性非常之高。
首先、搜索资源是搜索引擎类产品的基石
一条资源(典型的,一个资源站点中更新的一个网页)从产生到展现给搜索用户要经历资源抓取、入库(也即将资源收录于资源库中)、召回(也即资源的分发)、排序、展现等一系列过程。其中资源的抓取、入库是召回的基础。
其次、你网站要让百度觉得有用
请求召回的资源数量的多少是对资源抓取、入库质量优良的有效指标,也是影响用户体验的主要因素。
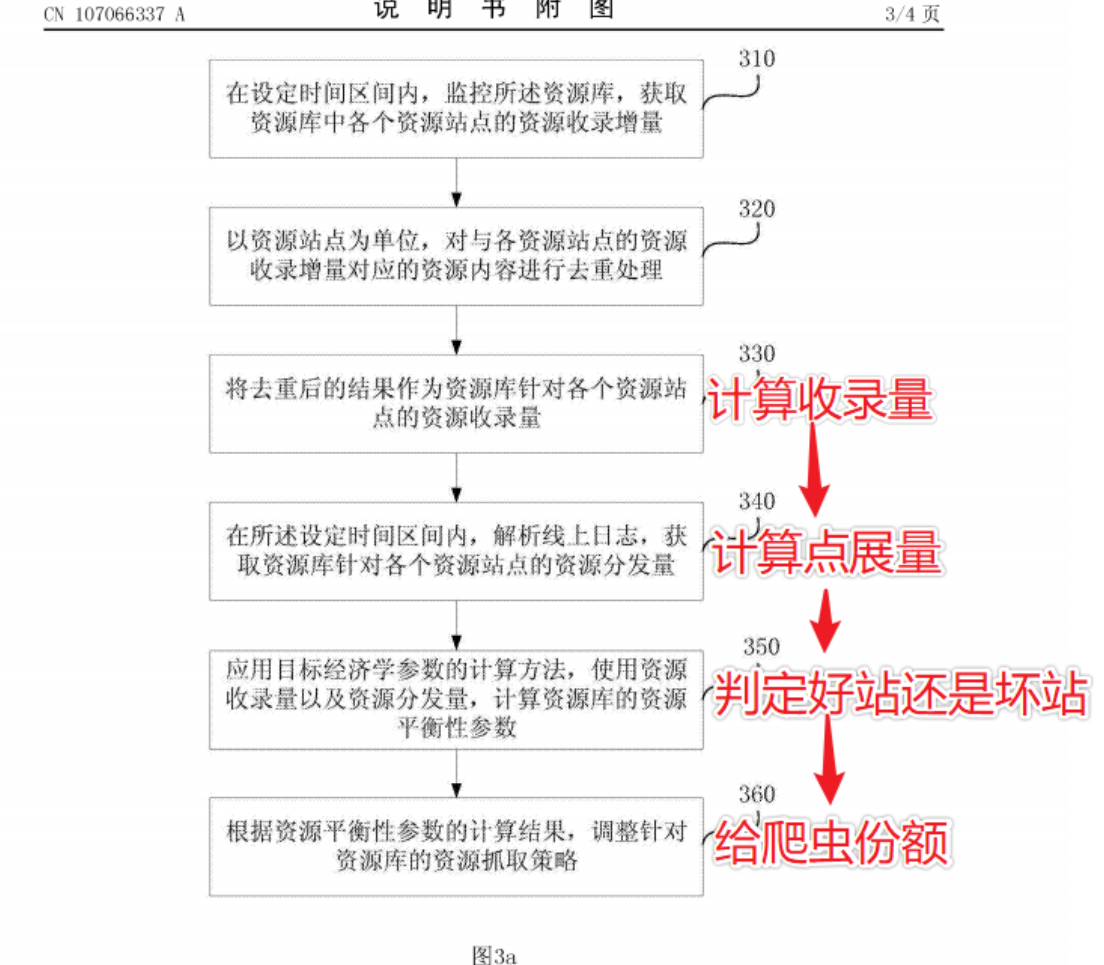
整站提权背后的原理
回过头来,我们思考一下整站提权的原理,不就是通过快排系统搜索提升了展示量,通过快排系统点击提升了点击量,通过点展比提升了网站的资源平衡性参数,通过资源平衡性反而又促进了网站的爬虫访问频率,雪球越滚越大。

码迷的忠告
当权重提升之后,已经有了较为稳定的流量,该停就慢慢停了吧,避免被雪球滚了。
其次百度已经可以根据点击路径分辨快排,所以纯纯的白帽才是最好的选择,君不见那些刷了快排的站到现在两个月了还没起来。
不要太心急,你才会慢慢赢。
十六、SEO内参(16) 2020年百万流量站项目优化破局之路
编者按(2023)
从专利上看,2019年百度的主要工作是点击系统升级(打击K排)。
2020~2022年是百度人工智能极速发展的,尤其是百度文心大模型应用于搜索等内部产品,涵盖内容分类、内容质量预测等功能,因此口罩三年也是擅长采集组合的站长们死寂的一年,因为站长们打不过AI。
AI高度依赖于语料丰富度,所以AI模型对偏门长尾词的模型预测并不准确,所以某些流量依然不难做。
2022年底,ChatGPT来了!魔法才能打败魔法,AI才能打败AI。
正文开始:
从2019年下半年开始,不知道大家有没有觉得,百度对流量站的要求越来越严格了。本来要上百万级别的流量项目,很多新站即使坚持发布了3个月的原创文章也没有排名。而使用老域名做站也是九死一生,100个站里面,有四分之一能有较好的趋势已经相当不容易。
2019年底,有幸参加了百度某AI技术栈负责人的一个内部分享,听的受益匪浅。码迷之前没有预料到AI之于搜索引擎发展的如此之快,而百度也丝毫没有停下对谷歌新算法的亦步亦趋。AI机器学习,尤其是深度学习方面真的非常重要。
所以码迷最近2个月几乎是每天都在学习机器学习相关算法,努力将最新的算法应用到摩天楼内容助手当中。但是做流量站跟百度AI又有什么关系,且听码迷娓娓道来。
码迷全面跟踪了某英语培训机构的站群存活周期,绝大部分网站只有2个月的存活时间。
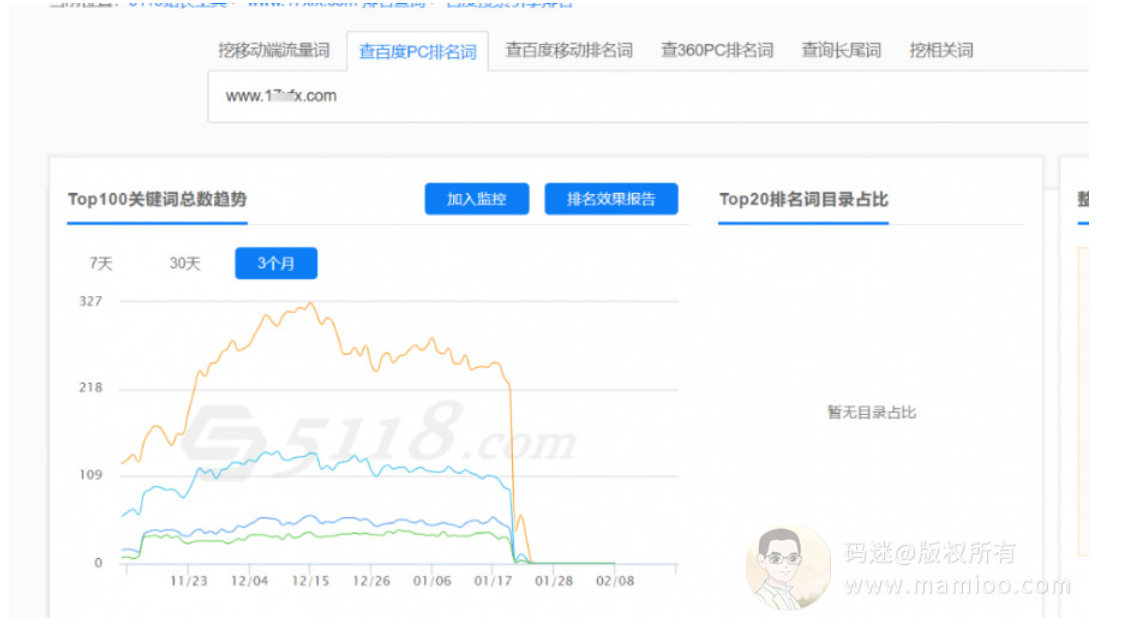
老域名500元+,加上费事费力一个月搞起来的网站,只有2个月的流量,假如说每天1000个UV,排除刷快排的点击UV,也就剩下顶多200个是真实流量,按照1%的转化率,每天能割掉2个人的韭菜已经不错。我不知道他们SEO团队活得怎么样,但是听码迷QQ群里面说,他们已经裁员过半了。
最近流量站典型曲线
特点1:起飞非常可怕

而最近做流量站的老师们也不容易呀,群里有个老师好久好久没有晒自己的雄起曲线了,因为雄起的后半部一般不会超过1个月。
特点2:啪叽落下来也非常可怕
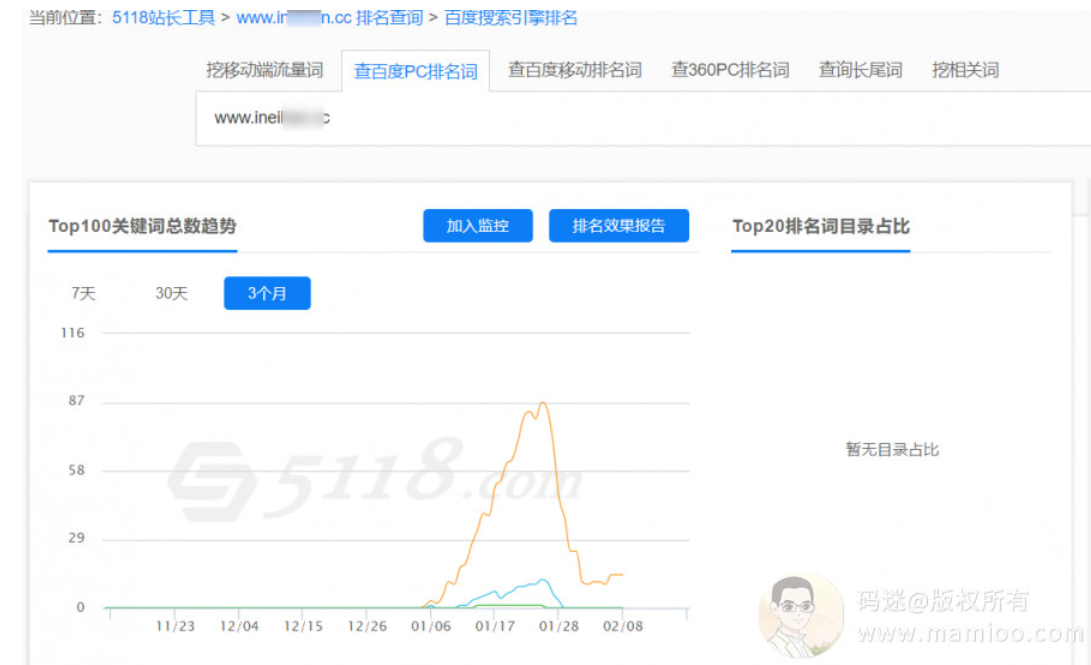
追踪了业内比较知名的几个SEO流量站,虽然2019年年中走过几波高峰,但是最近3个月首页关键词数量从1400跌倒800左右,是温水煮青蛙的没落状态。
心疼的老师们纷纷表示:

流量站行业分类
我们先看一下流量站有哪些
1. 诗句类
包括作文、散文、诗歌、成语、诗句、句子等等。我们以“带月亮的诗句”为例,可以看到PC端的第一位流量给了站长的,但是移动端就没有那么仁慈了。
百度PC端:
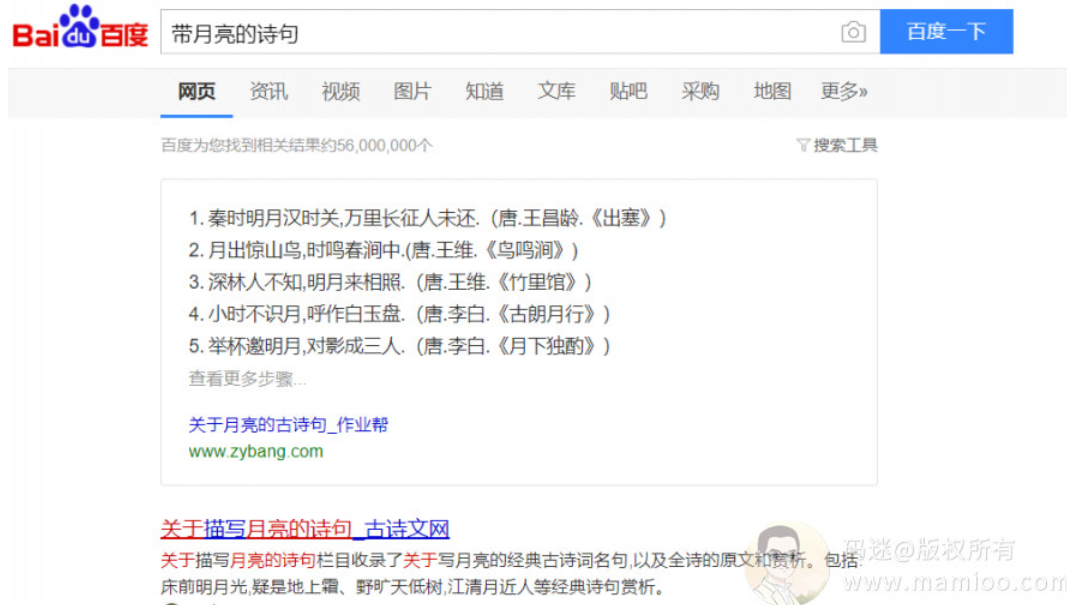
百度移动端:

2. 星座算命明星类
包括星座、算命、解梦、明星八卦等等。我们只看移动端就行了,PC端流量很少。
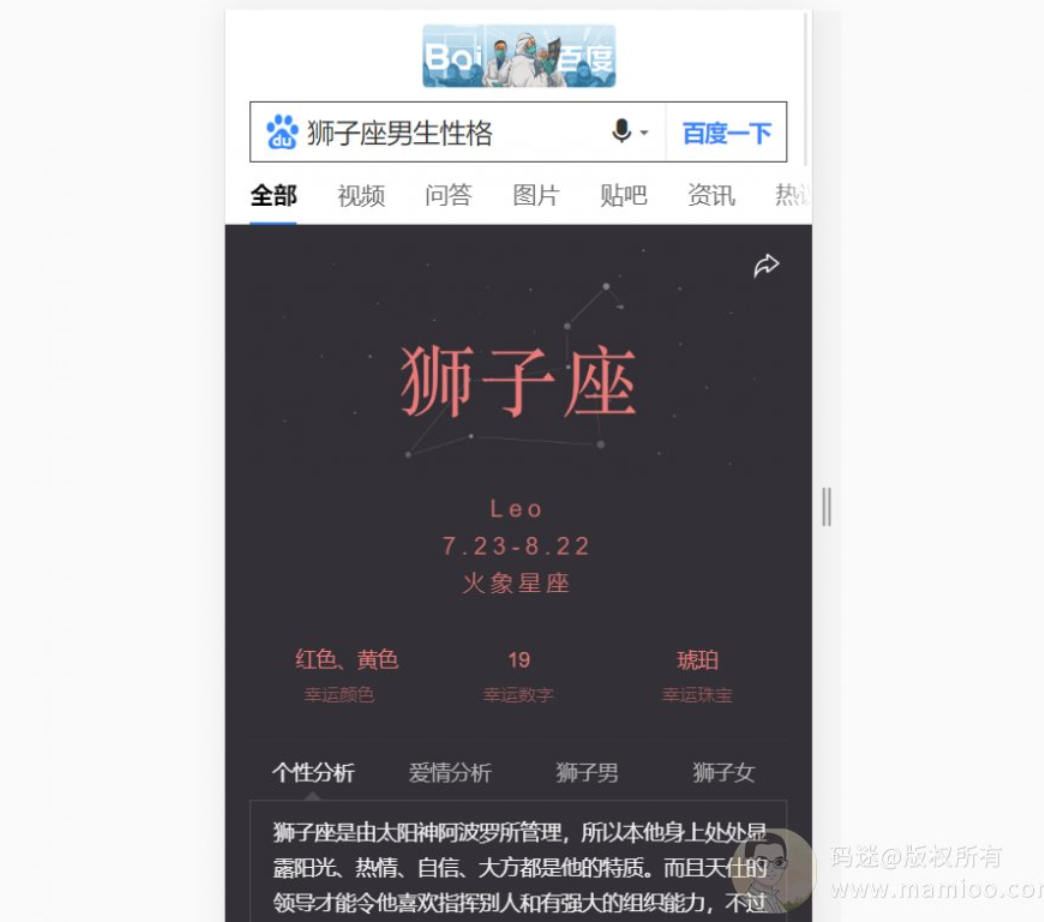
3. 生活工具类
比如天气,交通等等。
4. 文娱类
包括小说、电影、软件、游戏类等等。这类移动端流量真的不少,但是版权风险大大的,所以百度不敢自己包了啊。
看到这里,也许大部分人觉得有数了,码迷的意思不就是说,百度越来越鸡贼,百度为了薅流量不顾中小站长死活了。
是的,百度确实是这么做的,AI的小负责人也默许了这个意思,可以说2020年是百度下一代搜索引擎的迭代元年。大家看看百度最近的专利就行了,80%以上都是AI相关的专利。
百度下一代智能搜索算法
现在的百度算法更倾向于文本匹配算法,而下一代对应的是“以内容理解和知识图谱”为核心的搜索算法。

大家看下面码迷绘制的这个图就明白了。
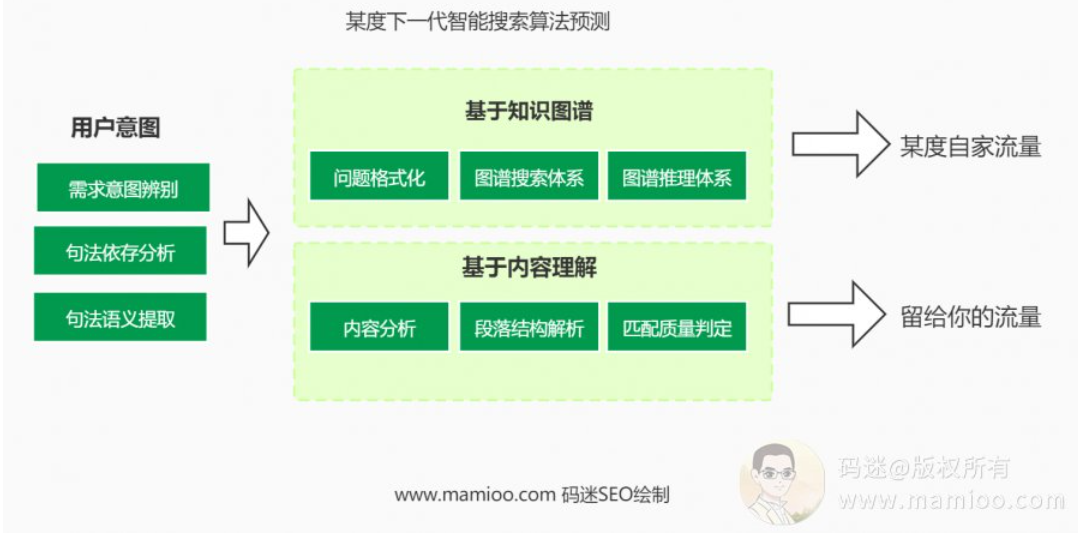
百度给予的搜索结构分两种情况。
1. 能套用知识图谱算法的,优先给予百度自家流量。
2. 不能套用知识图谱算法的,才给中小站长流量机会。
道理很简单,如果你做的流量站内容,连知识图谱的质量都打不过,就不要费功夫了。
2020流量站如何破局
1. 跟随百度提供的工具
百度推出新的算法之后,必然伴随新的工具或者接口,就像当年的熊账号一样伴随着推送接口。比如如何提高精选摘要的展现率等等。通常对接百度精选摘要后,跟着百度的趋势走,流量就会瞬间攀升啦。
2. 内容跟网页结构同样重要
现在很多做流量站的,只注重内容原创性,但是很少注重段落排版以及丰富度。随着多模组在百度内部地位的提升,随着5G时代的到来,单纯的语义匹配比重会下降。优质图片、优质视频给予权重会更加显著。比如,下图这样的纯文本内容,不会过百度二审,也是造成曲线过山车的重要原因。
3. 凭本事怒怼百度大脑
百度大脑包含了比较完整的百度语言和知识技术的布局。其底层的基础就是知识图谱,而知识图谱是构建与海量的中小站长优质内容基础上的,百度大脑也不能认定自己百分百牛逼,肯定会留有被后人超越的空间。
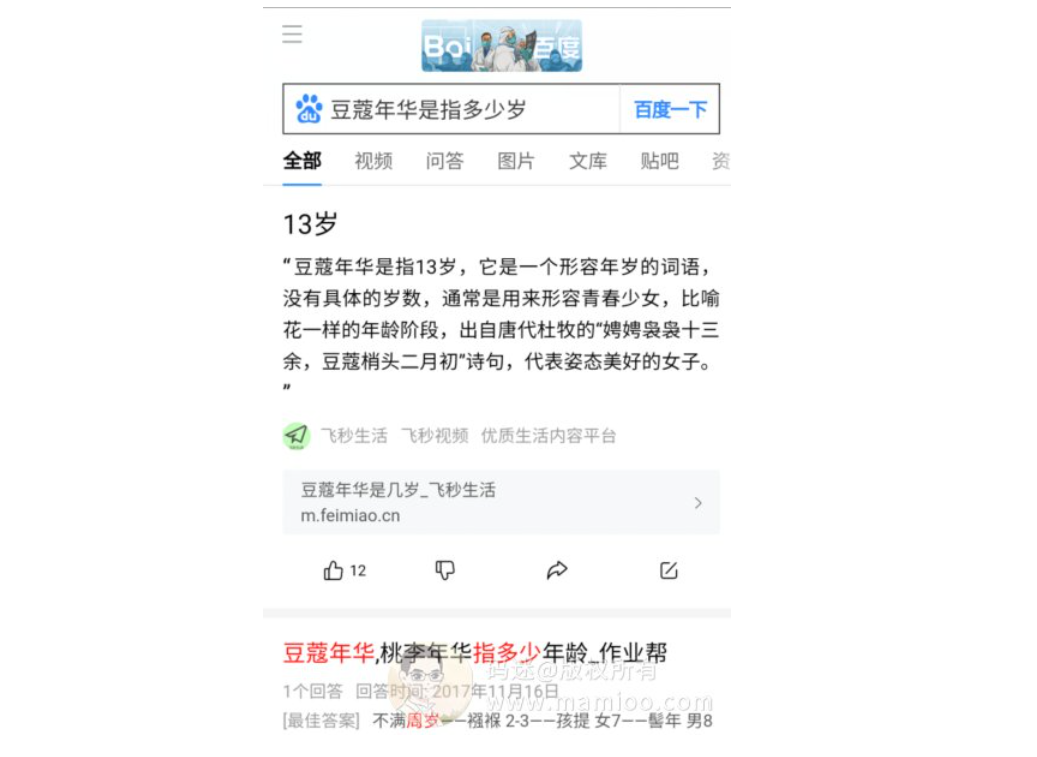
比如“豆蔻年华是指多少岁”,百度大脑的知识图谱体系里面是“13岁”,老子豁出去了,老子连视频都怼上,百度何尝不喜欢呢。
4. 避开百度大脑锋芒
百度AI(百度大脑)特点是什么?他需要大量结构化的语料。比如“描写春天的句子”、“鱼香肉丝怎么做”这类的问题,有大量对应的网站内容来帮百度训练数据,所以这类问题肯定百度会自建知识图谱的,把流量薅到自己的池子里。
建议大家关键词挖掘那些搜索量大,搜索结果少的关键词,作为我们2020年做流量站的第一目标。
真心希望2020年大家的网站不沦为百度的语料库, 以上。
十七、SEO内参(17) 泛需求词上排名的因素解密以及经验分享
编者按(2023):
泛需求词(Broad Match)因为不精准,所以转化率是极低的。所以这类词拿来装B可以,干实事难啊。
对于泛需求词,搜索引擎算法会尽量保证搜索结果的多样性,而不是相关性,甚至还有轮流展现算法。那排名就大大滴不稳定了,所以不要钻牛角尖的折腾。
正文开始:
码迷在2019年年底的时候,通过摩天楼内容助手这个纯白帽SEO手段,把“SEO工具”做到了PC、M双端首页,但是不久又掉下去了。通过百度站长平台反馈,百度的小姐姐反馈说关键词为泛需求词,泛需求词排名是由网页综合质量和用户需求综合决定的。泛需求词存在波动性是正常的,你小破站线上状态是合理的。
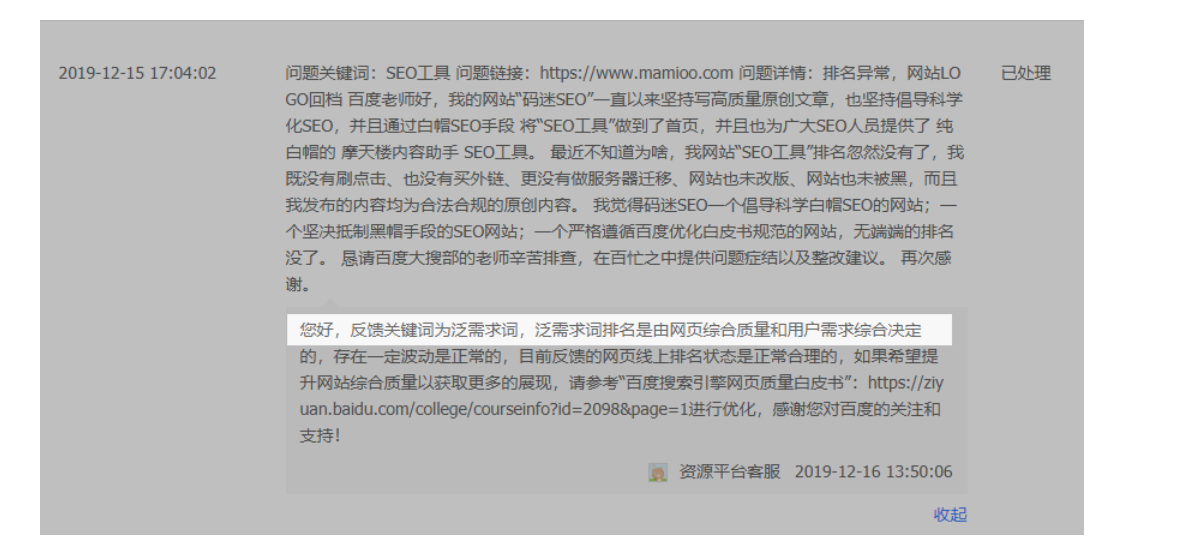
针对百度的反馈,摩天楼群的小伙伴们都像见了大骗子一样,“百度的反馈丫的都是直接复制的,丫的别看,丫的会误人子弟的”。码迷觉得小伙伴们的回复非常科学合理,但是当我们遇到排名问题的时候,如果不根据百度官方的方向去调整,估计也不行。
因为百度的反馈虽然枯燥,但是大方向也大差不差的,有钱的公司一般都这么枯燥无味的。
码迷客服做SEO的前几年都在甲方公司,负责国内电商的大型网站推广,也粗略的意识到各种词的SEO操作会存在不同,尤其是在摩天楼接触过许许多多的不同SEOer的咨询以后,才真正了解到,不同词的SEO操作侧重点真的是截然不同的.
对于SEO人员,在已了解了SEO最基础知识后的第一步,应该是去剖析自己所做关键词的情况,从而对症下药。
通过对症下药之后,结合摩天楼内容助手相关性的威力,“SEO工具”这个泛需求词,摩天楼的站基本稳定在移动端的前三名。那么码迷是如何操作的,我们一点一点来看。
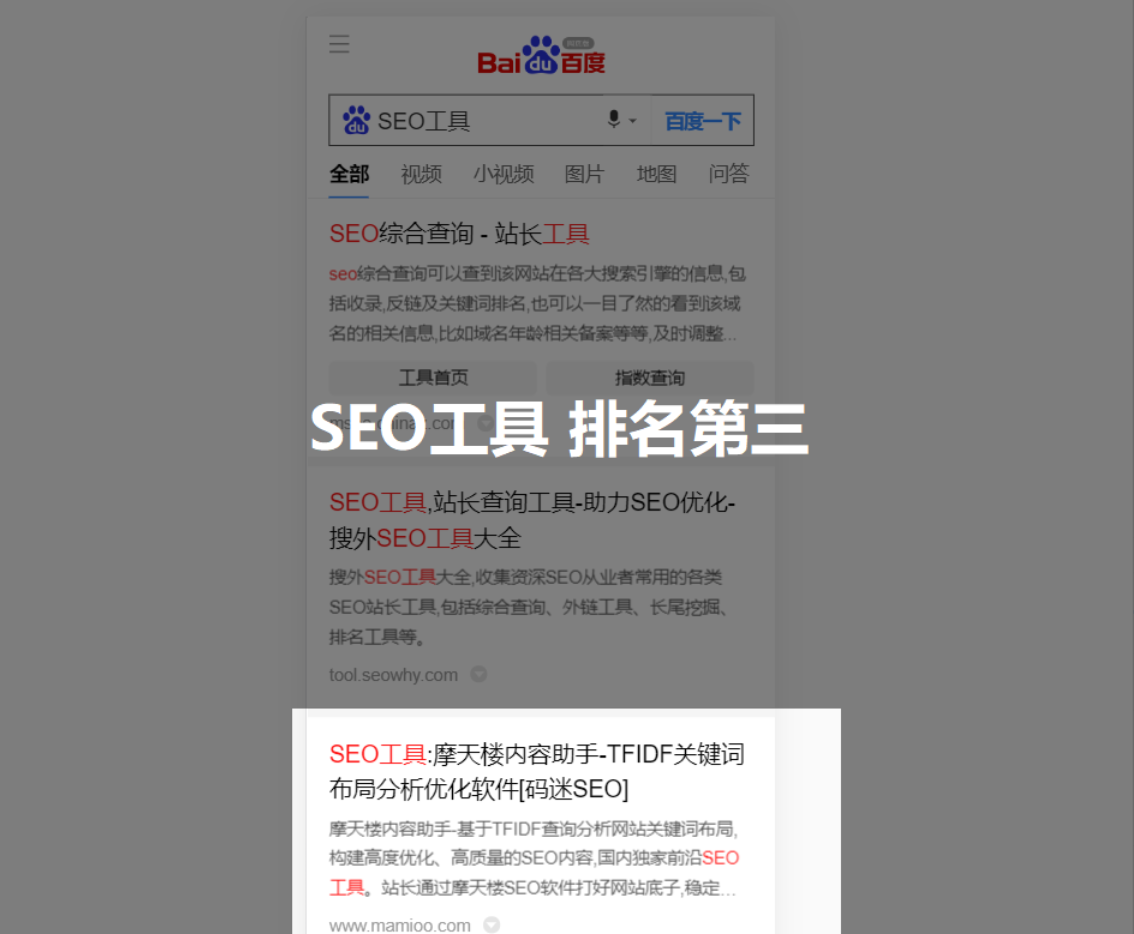
什么是泛需求词
对关键词下定义,我更喜欢从百度专利里面找到答案,百度说了,泛需求词有三种确认方式,如下图。那么码迷总结简单以蔽之,泛需求词是存在后继词的关键词。

什么后继词,这个在码迷上次发的百度内参文章《如何刷百度下拉词、推荐词、相关搜索及原理解析》www.mamioo.com 中说过了,这里不再累述。
泛需求词排名因素
百度官方的反馈里面,说的很明确了,泛需求词是由页面综合质量和用户的需求来决定的。举一个例子,摩天楼有个做无人机的站长反馈想把“播撒”这个关键词做到首页,通过摩天楼把评分做到了90分以上,但是还是上不了首页。码迷其实觉得比较无奈,今天就把这事来剖析一下。
1. 用户的需求
我们从播撒的后继词来看,用户的需求可以归结为读音、拼音、意思、种子等几个需求。在深入思考一层,100个用户里面,会不会有1个通过“播撒”这个词找“播撒无人机”的,我估计能有也就只有无人机站长这1个人了。
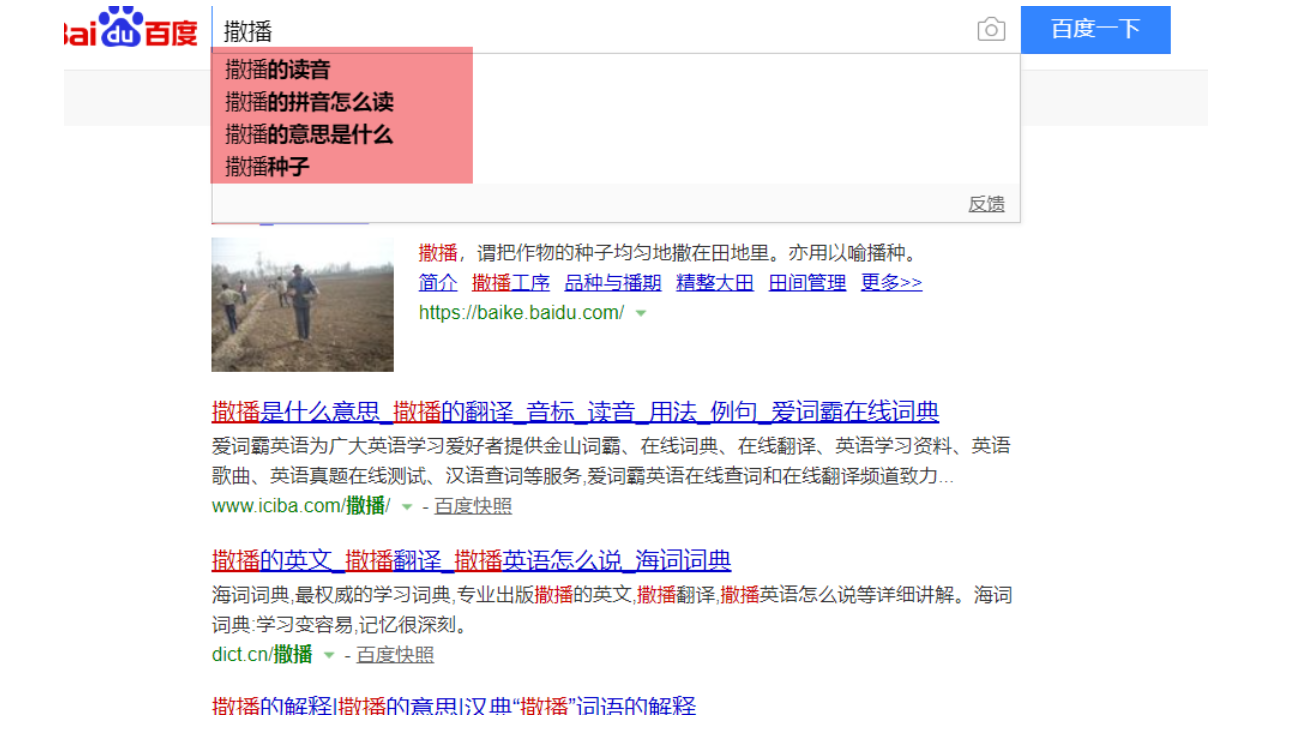
2. 页面综合质量
通过摩天楼内容助手,生成的相关性报告,可以看到“播撒”的相关词有“作文 飞机 国民 大全 希望 查询 中国 造句 单词 收获 搜狐 人民”。这些相关词是非常零散的。比如作文跟飞机是完全不一个领域,国民跟造句又是不同的领域。
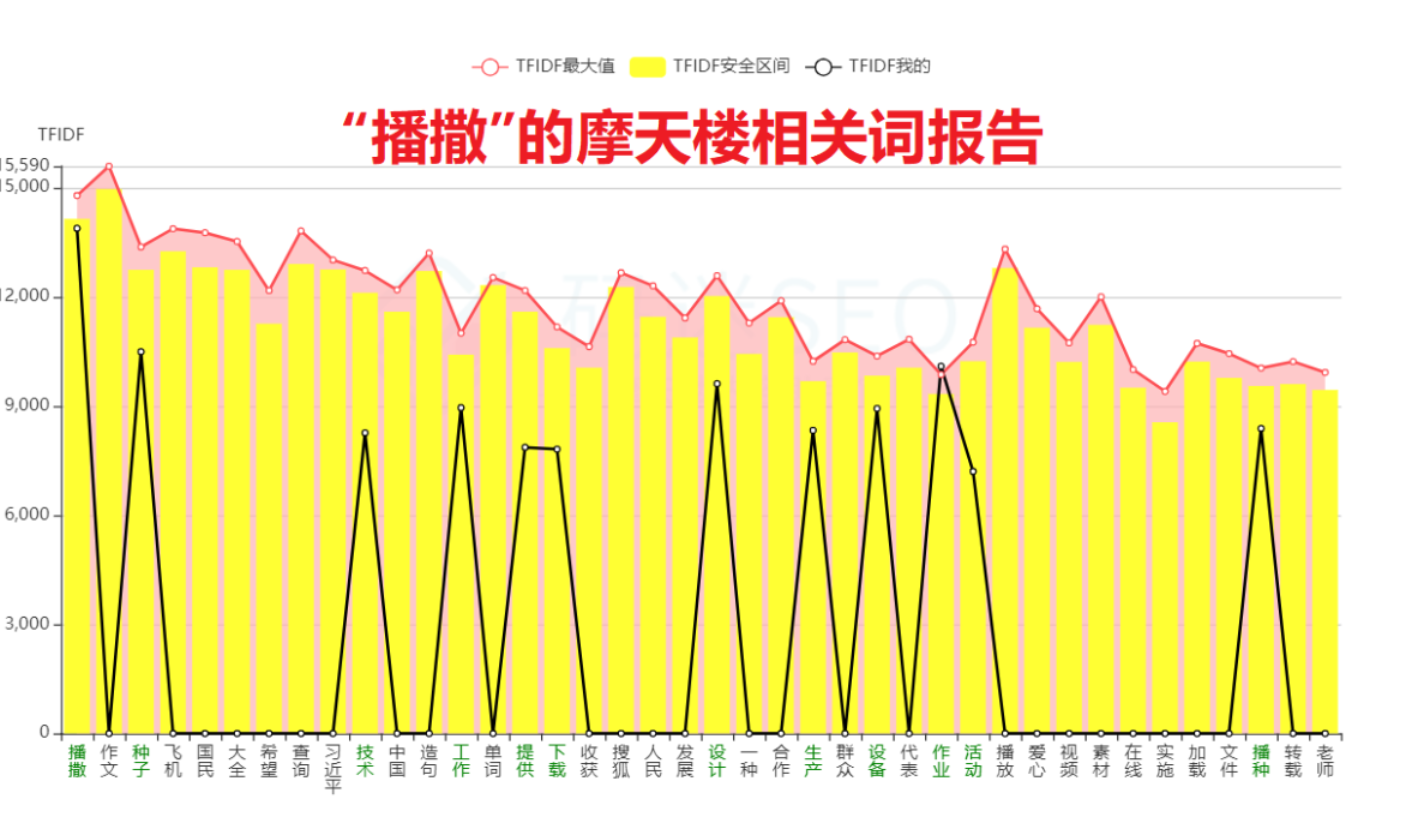
有同学觉得比较难理解,我们拿“农业无人机”这类更精准的词对比一下。可以看到,“农业无人机”的相关词有“传统 效果 控制 电池 航拍 减少 监测 直升机 设计 自主 美国 采用 人工”等等,这些词基本都属于科技领域。
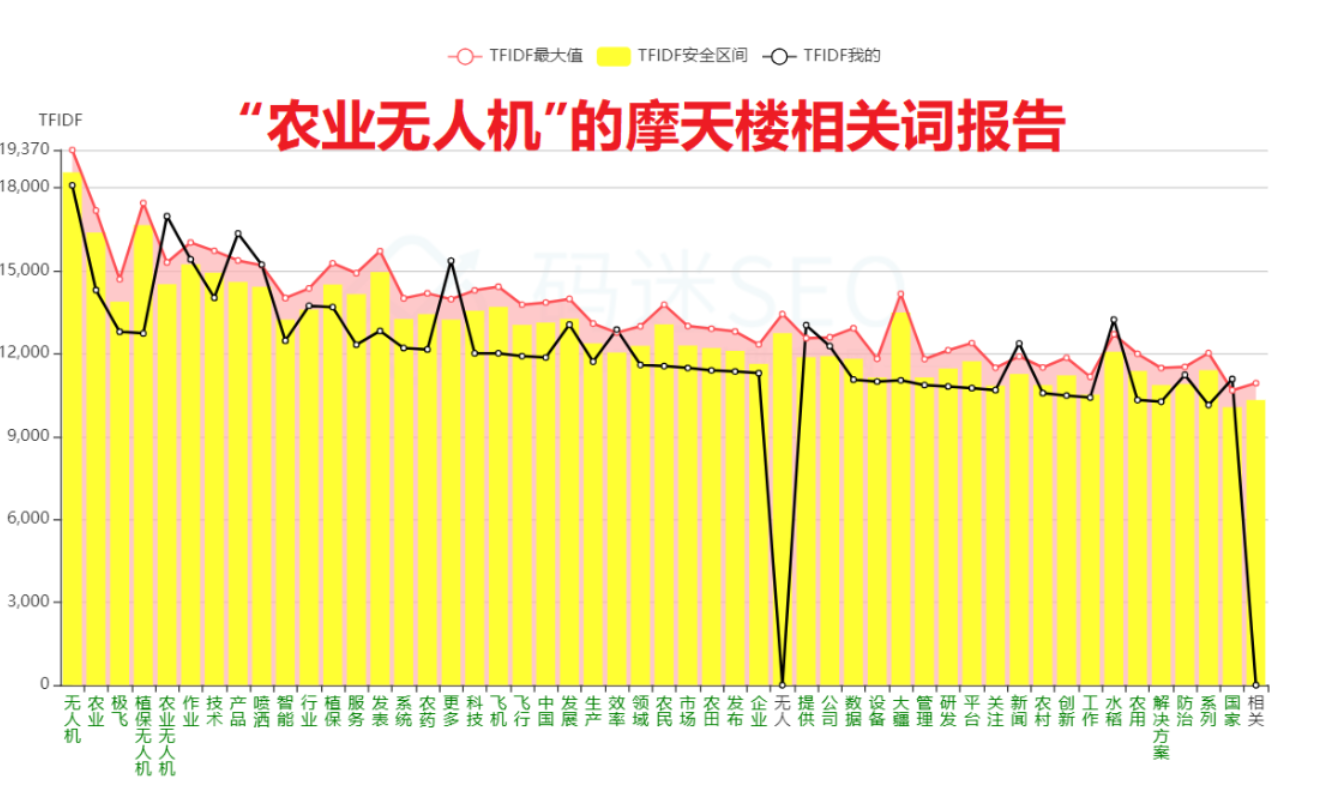
我们可以得出一个结论:关键词越精准,它的相关词就越相关;关键词越泛,它的相关词就越不相关。有小伙伴就说了,码迷你这不是屁话加废话吗?不不不,你要再想一层,想一下如果你变成了艳红的度娘,你的搜索结果会是这样的:关键词越精准,俺百度的结果越相关越好;关键词越泛,百度的结果就越不能相关喽。
那搜索引擎为啥这样做呢?
搜索结果的多样性
传统的搜索主要通过给定的用户查询获得搜索结果,并按照相关性排序后返回给用户。这个算法叫TFIDF算法,也是摩天楼内容助手的核心算法,主要是通过倒排索引(inverted index)来进行。理想情况下,百度搜索应该返回最相关的结果就可以满足用户的需求。
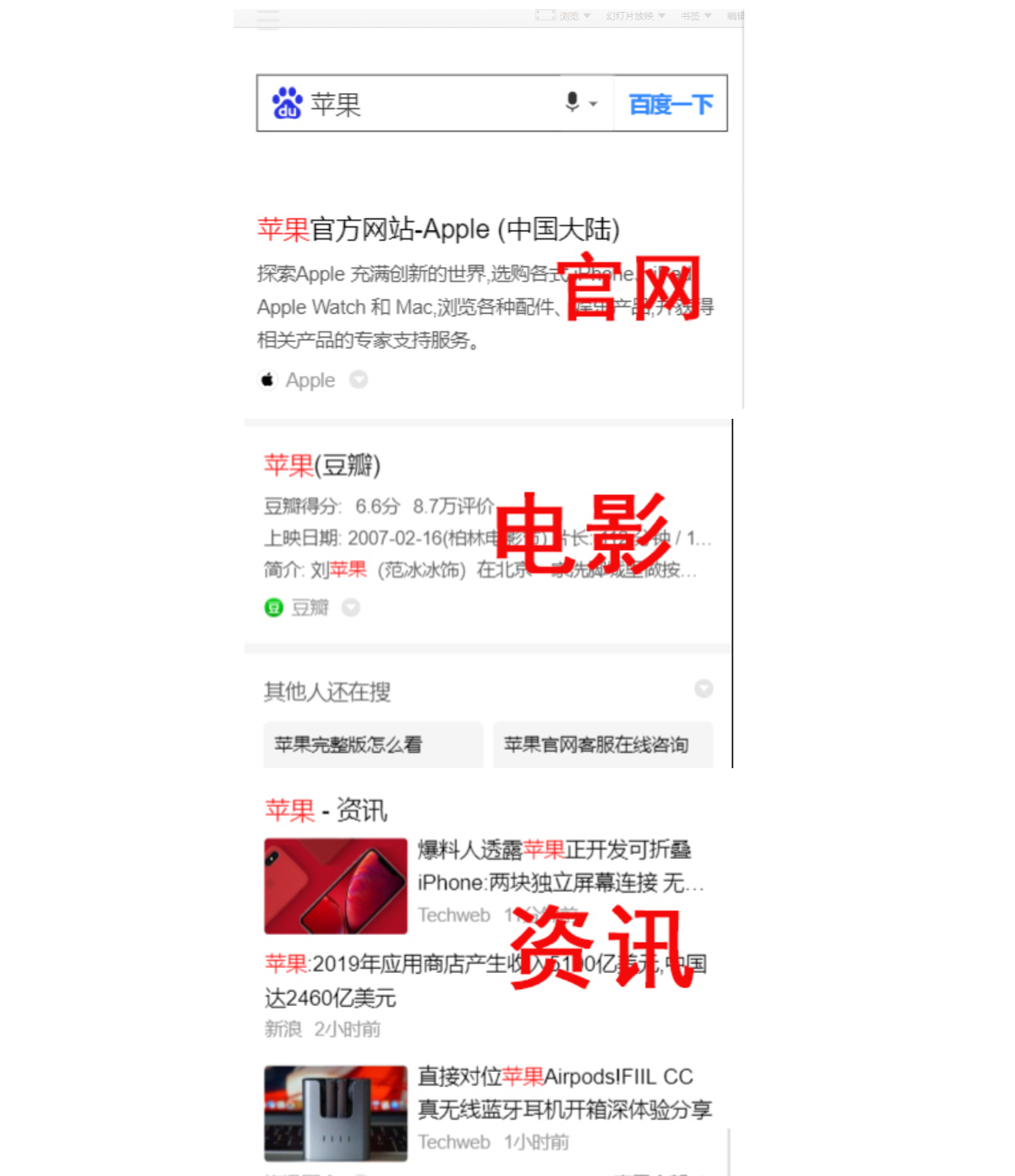
其实不然,比如关键词“苹果”是水果也可能是苹果手机,还可能是某动作片苹果,所以百度也很纠结,多样性意味着结果可能不相关,相关性却意味着多样性缺失,所以必须在多样性跟相关性找一个平衡。百度努力ing~

百度专利《基于人工智能的搜索结果排序方法和装》上也是这么讲的:针对泛需求词,在相关性排序之前,会对页面首先维度分组,再做相关性排序,以便排序后的搜索结果更好地满足用户的需求,提升了用户体验。

所以说,词越是泛需求词,多样性越重要,相关性越次要。那么又有小伙伴还是问码迷,码迷老师,你扯犊子一样扯这么多理论干嘛,老子要的就是怎么个破局法,老子要的是赶紧嫖到结论。
佛说:脾气越急智慧就越少,脾气越温和智慧就越多。花开随喜,花落不悲,理性对待事物因果,多读读毛爷爷的《矛盾论》和《实践论》,才能摆脱SEO困境。
多样性算法
之前知乎SEO负责人Zero说过:
尽管各行业同样是面临这套大规则(百度通用搜索程序),关键在于,各行业根据其行业特性,用户都搜索着不同性质的搜索词。由于搜索词的性质不同,我们着陆页的基本形态需要变化,同时,百度看重的排序因素也会随着搜索词性质而大幅改变。
所以说,搜索需求决定合适的着陆页类型。多个搜索需求,必然汇集不同的着陆页类型。
我们知道,这里划重点,其他培训老师们是从来没有讲过的,百度专利说按照HTML格式组织起来包括文字、图形、声音和视像 等信息的文件,按照终端又分为PC页面跟移动wap页面,按照页面内容领域又分为娱乐、新闻、体育等等,按照页面布局又分为首页、商品列表页、文章列表页、商品详情页、文章详情页、专题页等等。按照页面资源类型又分为问答页、图片类、视频类、小说类、k-v类等等。
那么泛需求词,到底倾向于那种着陆页类型?
答案是看关键词的所属行业。比如“播撒”这些词的搜索页面,搜索结果更倾向于按照领域划分,“苹果”更倾向于按照资源类型划分。
那么码迷想想“SEO工具”如何做,码迷调查落地页类型之后,码迷首先确定“SEO工具”百度多样性更倾向于用页面布局来区分,查询工具类的页面长期霸占首页,其他类型的页面漂浮不定。那我就在页面上加个查询框,然后我相关度也牛逼,这样就行了吧,嗯,结果奥利给~!
泛需求词上排名的经验总结
1. 找准自带转化的泛需求词
泛需求词,因为是需求不确定,很多人认为不是精准词,不如“长尾词”转化好,所以不值得做。码迷认为不是这样的 ,首先泛需求词很多都是指数词,单个泛需求词的搜索量远远大于当个长尾词,所以从投入产出来讲,值得来做。
稍微精准一点的泛需求词,不仅有一定的流量,转化也非常高,比如像刷单行业的“淘宝刷单”、减肥行业类的短词,背后的落地页转化率相当高了。
2. 分析搜索结果的页面分类维度
到底搜索结果着陆页面是按照布局来分类,还是按照领域来分类,还是按照资源类型来分类,一定要搞清楚。多观察两天,看看哪类的页面是最稳定在首页的,那么你就做这样的分类。
比如搜索某个词,首页全是大站(搜狐新浪知乎)的文章页,那你用自己的小破站上的详情页怼又有什么意义,起码首页怼才行是不是?
再比如某些暴利行业(如机械),首页全是快排首页站,一个白帽子都没有,那你用自己的小破站上的首页怼又有什么意义,那用搜狐新浪知乎的文章页弄上去再配合快排干一炮会不会更牛逼?
3. 干就是了
用摩天楼怼相关性,怼页面类型,怼内链外链,实在不行再怼快排,做SEO干就完事了。
十八、SEO内参(18) 如何刷百度下拉词、推荐词、相关搜索及原理解析
编者按(2023):
本文算法依然有效。
从黄反力度来看,百度搜索下拉要比百度指数的下拉强很多,所以,一定要遵纪守法,不要幻想。
正文开始:
码迷认为百度相关搜索以及百度下拉的算法原理并不复杂,在百度的公开专利中,譬如《CN201610082135.6 提供与功能组件相关联的搜索建议项的方法与装置》中也说的比较清楚。码迷的摩天楼官方群里面也有做刷下拉框的小伙伴,出下拉的效果也非常好,本文也经过了该小伙伴的认可。废话不多说,还是先从现象看规律,从本质看规律,我们开撕百度下拉词刷法与原理。
百度3大搜索词推荐体系
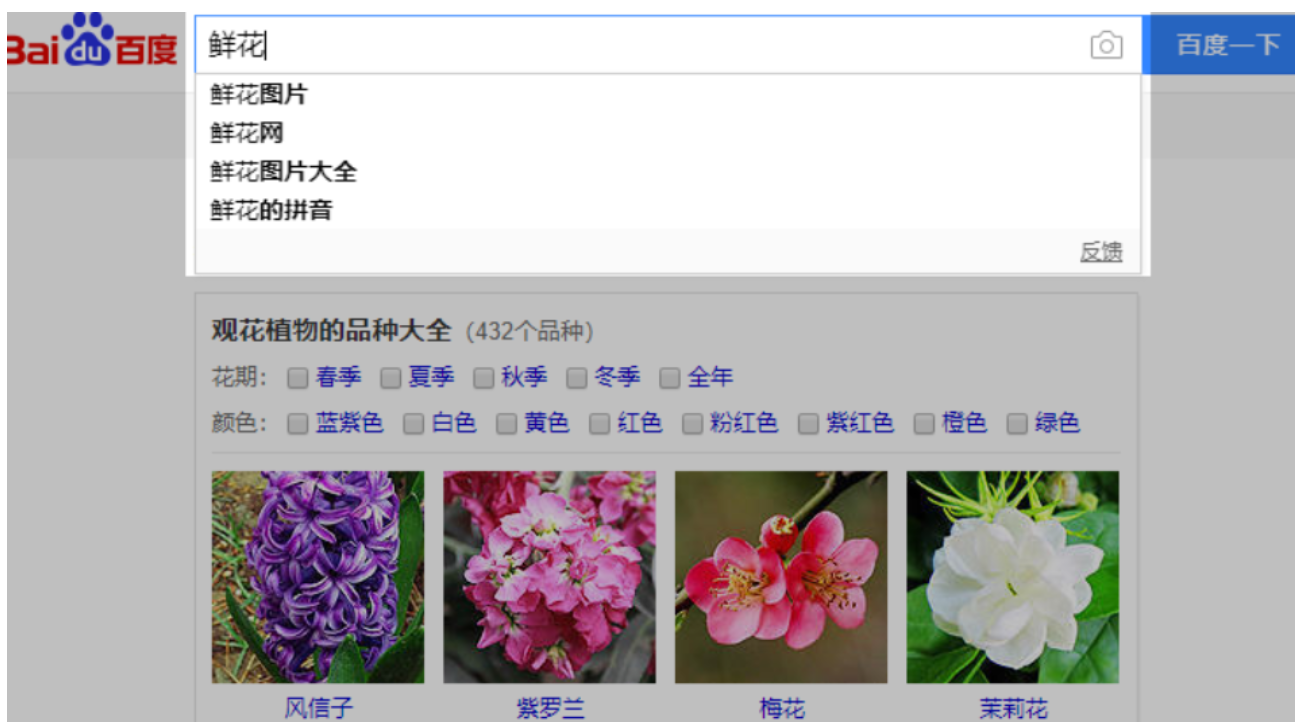
我们还是拿百度专利里面的具体的例子,拿出你的手机,或者浏览器,搜索“鲜花”。
1. 百度下拉词
2. 相关搜索词

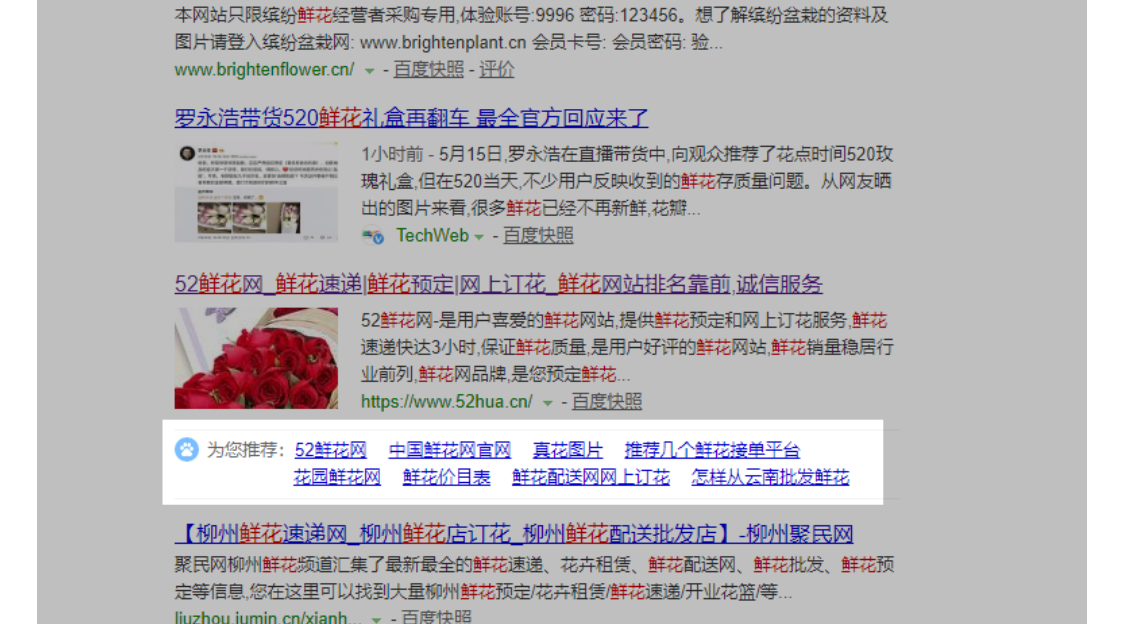
3. 推荐词
当点击某个搜索结果后,返回搜索结果,该结果底部会出现推荐词。有些人称这些词为熊掌号流量词,反正码迷不知道这玩意跟熊掌号有毛关系?
注意百度下拉、推荐词与相关搜索的区别:
1. 百度下拉词中一般是以“鲜花”开头的词语,是字面上的关系
2. 推荐词 可以不以“鲜花”开头,但是基本都包含“鲜花”,所以也是字面上的关系
3. 相关搜索中并不一定包含“鲜花”,更具有语义关联关系。
从用户体验上讲,用户从搜索结果的头部查找到搜索结果的底部,那说明没有太满足用户的需求,应该让用户换一下词。也就是说从紧密程度上看,下拉词>推荐词>相关搜索词。好了,我们继续挖。
下拉词、推荐词、相关搜索与地域的关系
我们拿一个地域相关的来看一下这些词与地域的关系,比如搜“冰箱维修”:
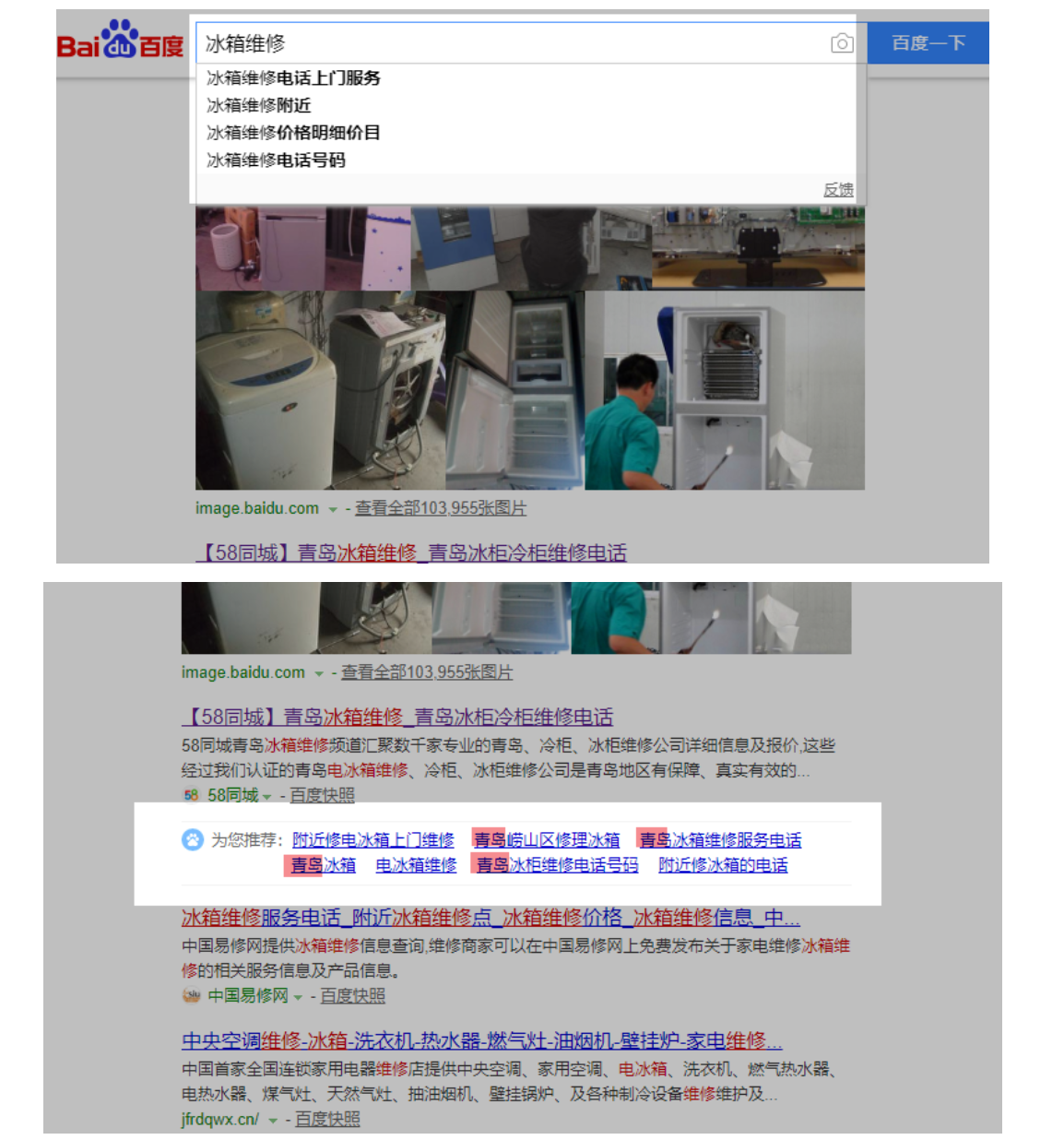
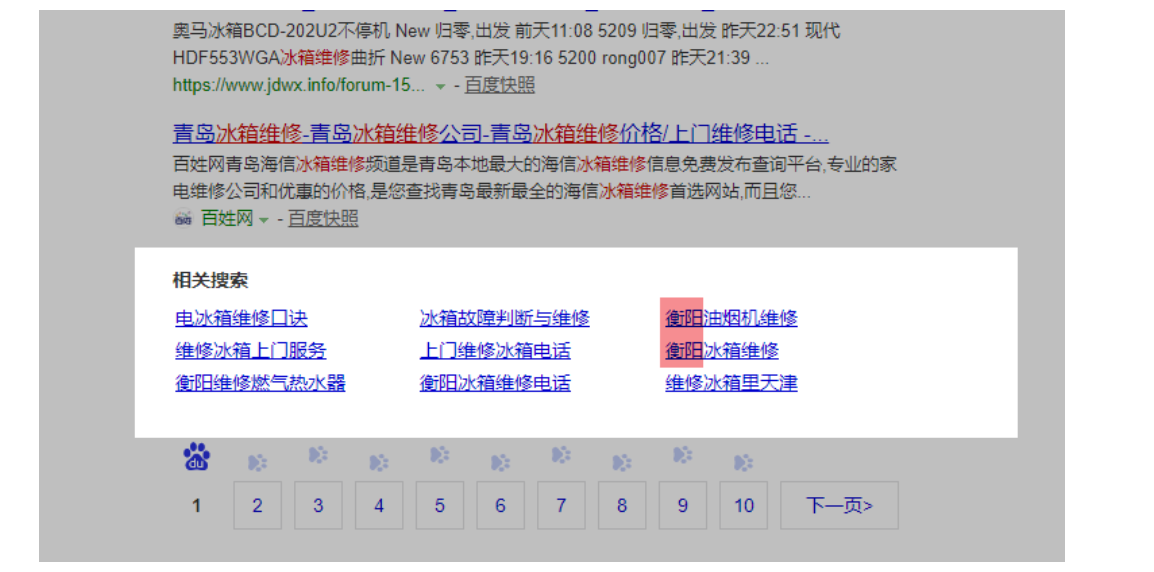
注意百度下拉、推荐词、相关搜索与地域的关系:
1. 百度下拉词 几乎没什么关系
2. 推荐词、相关搜索均有地域关系
下拉词、推荐词、相关搜索与时间的关系
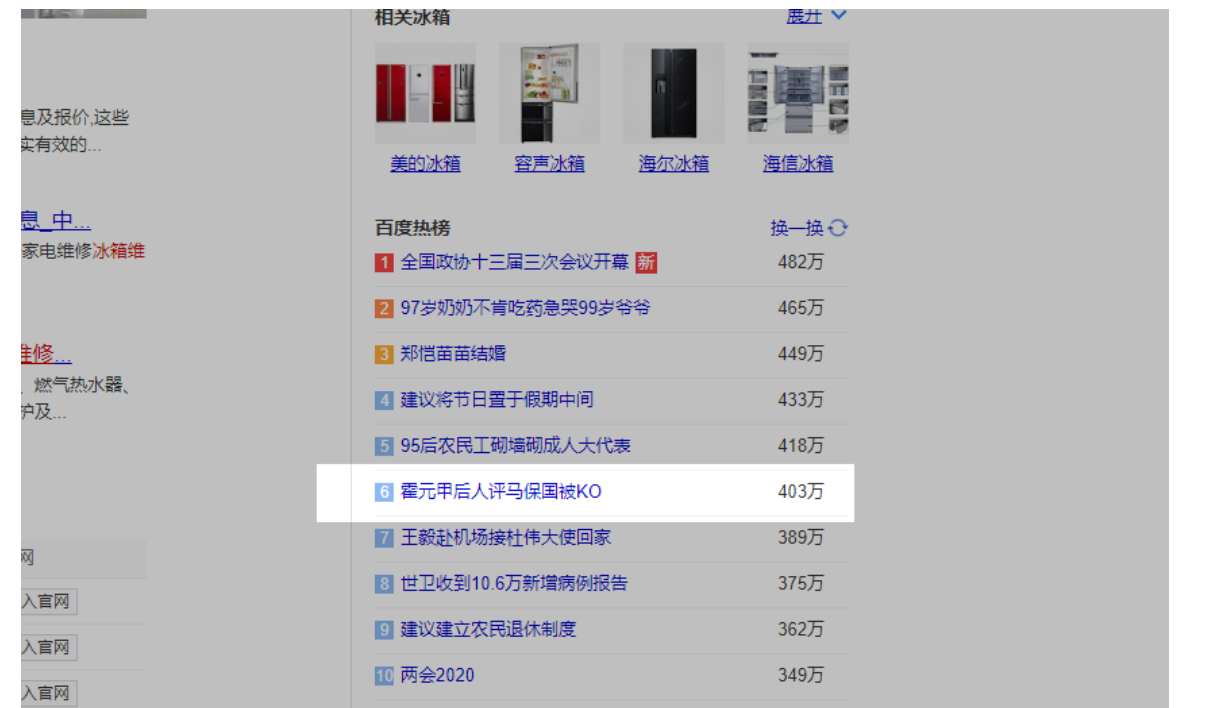
为了验证这些词跟时间的关系,我们找一个热词就行了,用“百度热榜”里面的“霍元甲”吧。
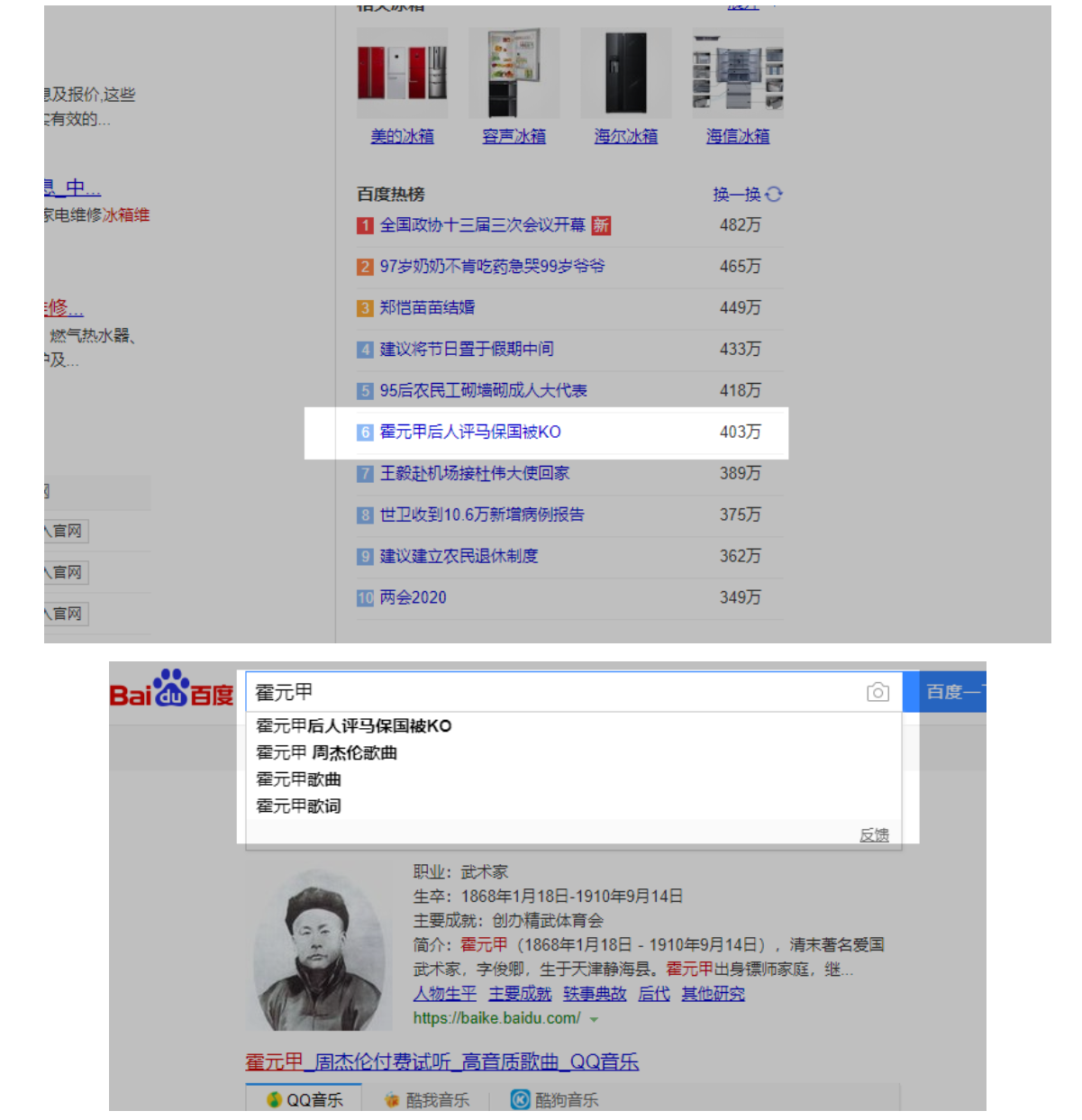
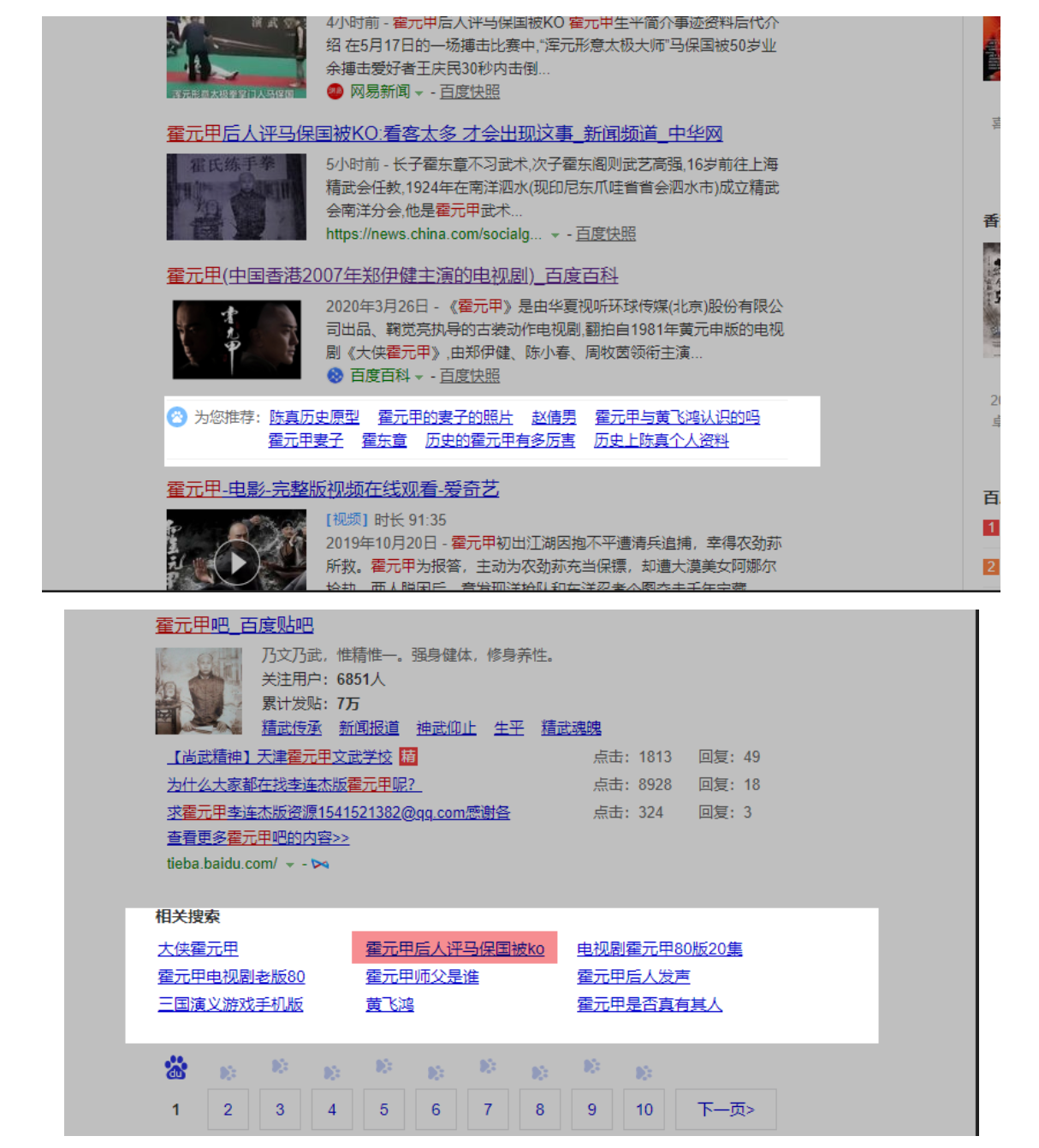
注意百度下拉、推荐词、相关搜索与时间的关系:
1. 百度下拉词、 相关搜索,与搜索词热度高度相关,当一个搜索词在某个时间段内的搜索量超过一定阀值的时候,就会出现在下拉。
2. 推荐词 未发现与搜索词热度相关
下拉词、推荐词、相关搜索与词的关系
这些词,你懂的,即使百度指数有,但是就是没有下拉,所以刷到一个亿也没啥用哦.
通过上面的几个现象,我们可以认为,百度下拉词、推荐词、相关搜索,是一套由指数词、长尾搜索词、相关地域词、高热度搜索词组成的推荐系统。
那么百度底层如何运作?
无论用户搜索什么,百度都会在浏览器本地,以及请求网址中记录用户的行为。主要是记录 某个用户在什么时候搜索什么词。所以无论刷下拉词还会推荐词,还是相关词搜索词,真实靠谱的ip地址,用户cookie都是必不可少的。
但是从成本来讲,比快速排名要小很多。这个大家可以参考码迷的文章《SEO内参(六):谈谈百度对快速排名的打击手段》www.mamioo.com。
百度下拉热度统计算法以及如何刷
首先: 预估刷下拉最低阀值
当一个词的热度在一段时间内,达到一定搜索流量的时候,就会获得出现下拉的最低阀值。百度有不同的热度统计方式,比方说天级热度上下拉要超过10000次,周级热度要超过200000次等等。
当有10个用户在1天搜索“霍元甲后人评马保国被KO”的时候,真没有多少量。但是如果一天内有400万个人搜索的时候,自然就不得不上下拉了。
其次:超越对手进入前十
一个关键词每天有多少搜索量,和它相关的词有多少搜索量,这些数据百度都记录在案的。
比如 码迷想让“站长工具 摩天楼内容助手” 出现到下拉中,但是下拉框里面最后一名“站长工具收录网站”每天搜索量100次,那我必须刷到100次以上才可以。
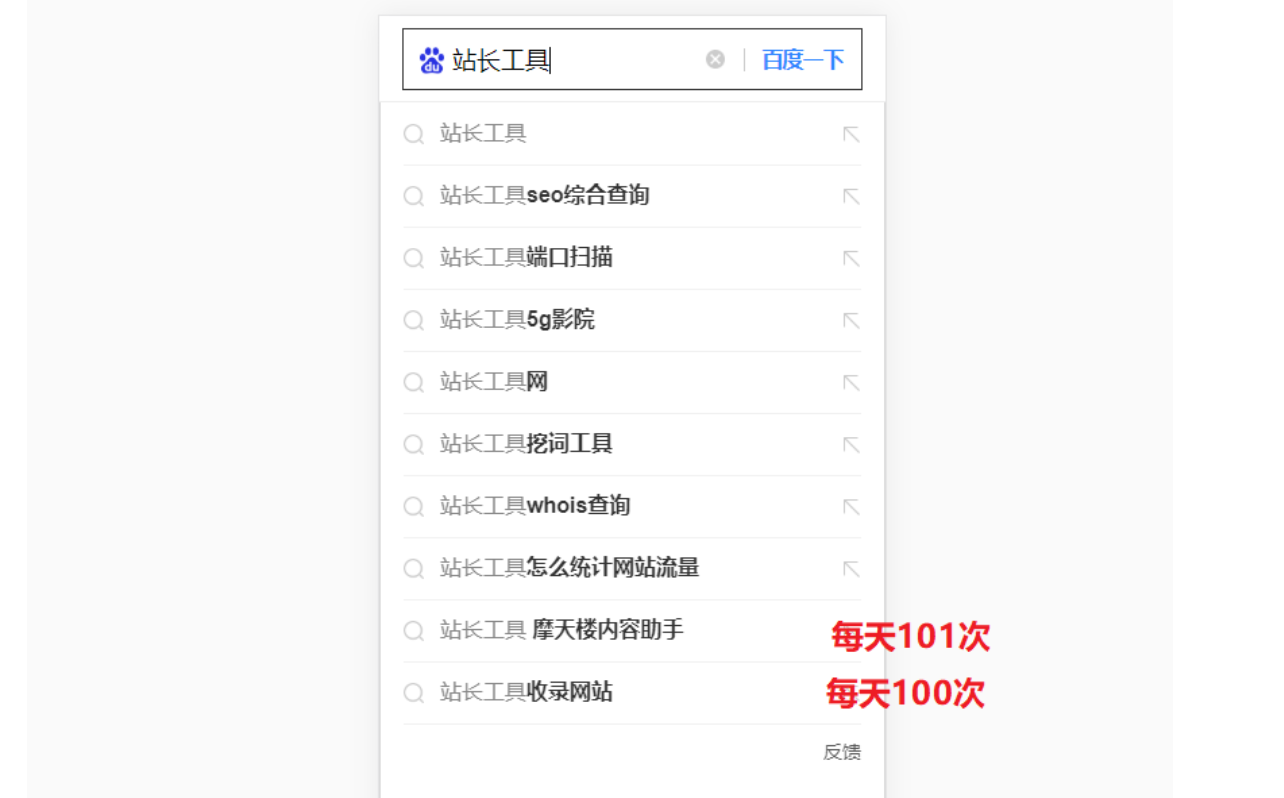
最后:最最重要的是与泛需求词 建立【后继关系】
那么同样是刷下拉的,有的人能刷出来,有的刷不出来,一方面,是预估次数的问题,有经验的商家可以根据指数信息预估出怎样刷最少的次数,达到出下拉的最低阀值。
另一方面,MAC地址,IP地址,浏览器COOKIES,搜索行为的合理性。根本的原因是没有建立起后继词关系。
顺便说一下什么是后继词,看图就明白了。这个跟码迷摩天楼中的后续词稍微有所区别,码迷在后续文章中再另行细说。
比如说 刷【站长工具 摩天楼内容助手】, 那么【站长工具】是泛需求词,后继词为【摩天楼内容助手】。
那么一通狠刷 【站长工具 摩天楼内容助手】 ,搜索之后以及之前没有任何的搜索行为,虽然搜索词其中包含了【站长工具】 这个泛需求词,但从时序上没有建立起后继关联,所以很难出下拉。
但是,如果每天有1000个人,先搜索【站长工具】,然后再搜索的时候,又加入了【摩天楼内容助手】,那么,坚持几天之后,百度query统计程序就会将这两个词设置为后继关系了,这时候出下拉就容易了。
还有一点,后继词不是一级的,譬如【鲜花】的后继词有【图片】,【图片】的后继词有【大全】。想一想如果营造一下【站长工具 摩天楼内容助手】的后继词,是不是就装的更像了。

比如:
第1步:搜“站长工具” 1次
第2步:搜“百度站长平台” 1次
第3步:搜“站长工具 摩天楼内容助手” 1次 ,点某条搜索结果
第4步:搜“站长工具 摩天楼内容助手 真好用” 1次
第5步:换IP,清理cookie,重新来
相关搜索的底层算法以及刷法
协同过滤算法,多用于根据用户兴趣推荐商品啥的,比如说你买了奶粉淘宝肯定给你推荐尿不湿。算法不复杂,但是也很好玩。
比如我们看看“SEO软件”的相关搜索,竟然“win7单个文件夹加密码”,“波克捕鱼辅助器下载” 八竿子打不着的词也推荐出来了。
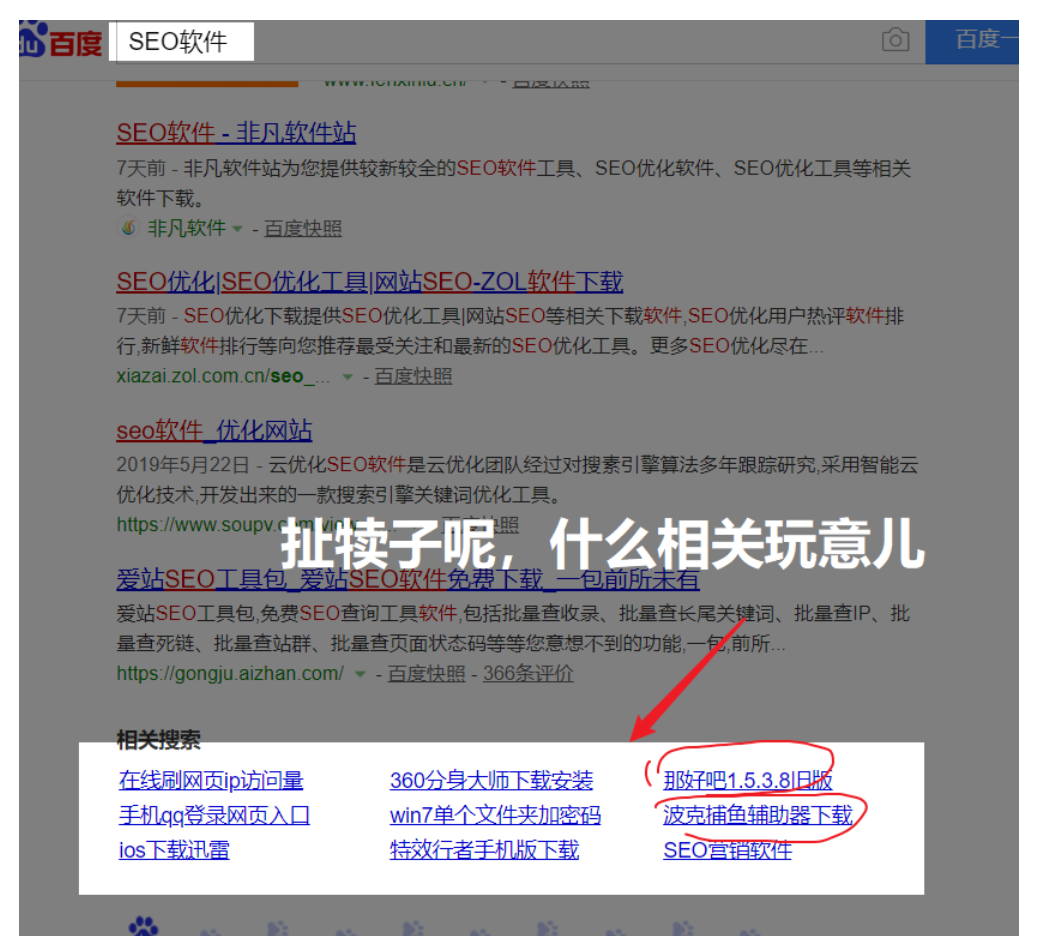
码迷觉得合理的解释是,一帮刷快排的操纵N个IP刷点击任务
A IP 的搜索记录 SEO软件,切割机厂家,波克捕鱼辅助器下载
B IP 的搜索记录 SEO软件,波克捕鱼辅助器下载,摩天楼不需要快排也能上
C IP 的搜索记录 SEO软件,萌腿是个好小伙,波克捕鱼辅助器下载
D IP 的搜索记录 SEO软件,萌新也是个好小伙,波克捕鱼辅助器下载
因为搜索“SEO软件”的人,很大几率也会搜索“波克捕鱼辅助器下载”,那么百度会认为,喜欢搜“SEO软件”的,也喜欢搜“波克捕鱼辅助器下载”,那就先推荐一波。

所以说,刷相关搜索的刷法,你自然就明白了。
后记
无论是百度还是谷歌,都有自己的词库推荐接口,一方面我们可以利用他们底层的算法,合理利用推荐词,增加自己的品牌词曝光度。
另外一方面,也可以通过百度的推荐词(5118里面称之为移动流量词),因为相对于下拉词更加长尾,相对于相关搜索词更具有紧密相关度,所以非常适合建立丰富自己的词库系统。
自己建立词库,也不是没有可能的,比如可以挂个代理使劲跑下面高相关长尾搜索词的推荐接口就可以了哦。
Bing: sg1.api.bing.com
淘宝下拉:suggest.taobao.com
以上文字,纯属码迷个人见解,如有异议,欢迎一起探讨。
那么,如何做选择行业词库,如何避免与百度自家产品产生竞争,我们后面一块说。
十九、SEO内参(19) 快排难度升级:谈谈指纹识别算法的破解
编者按(2023):
俺认为对于大部分行业,K排已死。
大部分的拨号VPS能被认定为机房IP,所以K排效果极差。有条件的走基站类IP代理效果会好很多,去某宝。
刷法请参考《SEO内参(15) 快排整站优化提权与百度资源平衡性策略》
早期刷百度竞价的那些“指纹浏览器”跟K排使用的“指纹浏览器”技术原理一模一样。
跨境电商使用的“指纹浏览器”跟K排使用的“指纹浏览器”技术原理一模一样,而且技术更成熟,这点只有我偷偷告诉你了。
账号cookie 并非必须,但有正向效果。
正文开始:
还记的2019年年底的那场快排大震荡,几乎市面上所有的快排都完蛋了,码迷2019年10月份时候发了一篇快排文章《百度快排原理及百度第三代点击排名统计系统简析》,里面提到几乎所有的快排系统都没有配置cookie,那个时候也没有卖百度cookie的。
而后续你也知道了,大部分快排系统开始布局cookie,又开始活蹦乱跳。
可是最近码迷摩天楼群里的大佬们好多都不好过啊,部分快排点击被识别了,直接表现是百度后台展现量不变,但是点击量一泻千里后一马平川,波涛汹涌越来越少,可难受了鸟~

有部分用快排的童鞋的曲线非常稳健,该上的词还是上。
但是并非所有的快排都是稳的一笔,比如下面是群里部分同学的百度后台展现量(蓝色线条),点击量(红色线条)趋势,从7月中旬开始大幅失效,半月过去了,也毫无波澜,恐怖就像惊雷前的寂静一样。
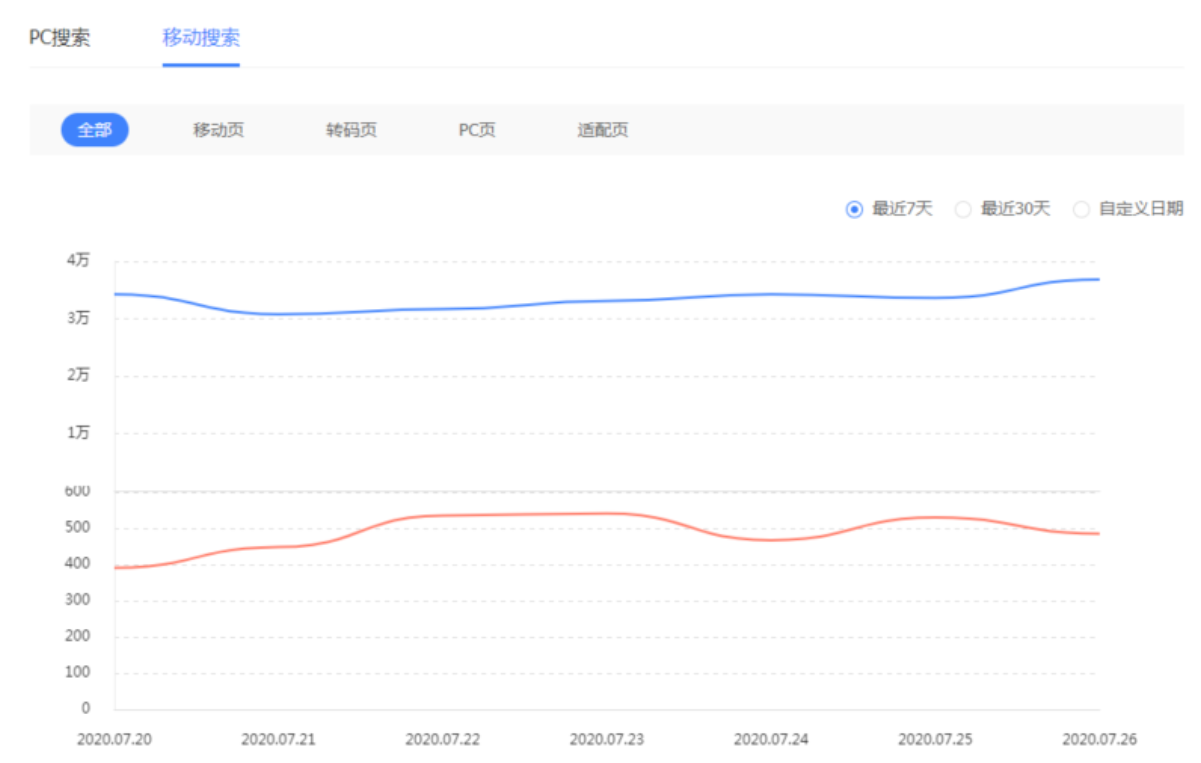

好多同学私信码迷,要码迷推荐快排,我也顺便咨询了他们现在用的快排系统以及刷点击方法。从现象上看:
1、 无论是整站提权还是小规模企业站点击,都会受到本次百度算法无差别对待
2、 使用代理IP、混播代理IP的快排商,受本次升级影响较大
3、 二手快排商家(买源码自己搭建),毫无反手之力啊

那么,那么,看起来百度这次对IP的打击力度挺大的,莫非跟近期百度IP信誉库升级有关?
如果你觉得是,那就太天真了。百度算法的稳健性在于,绝不允许单一因素引起的排名霸屏,当然也不允许网站因为单一因素导致的大概率无排名。
就像是:
1、 IP是代理的就算了,也许不是坏人,但是尼玛Cookie也是假的,你肯定是坏人!
2、 IP是代理的就算了,也许不是坏人,但是你10000个点击都是一个尼玛指纹,你也肯定是坏人!
浏览器指纹
什么是浏览器指纹,百度防范恶意点击竞价的防范上应用的较多,在百度专利《建立浏览器指纹以及识别浏览器类型的方法、装置》说了,浏览器屏幕分辨率,时区,字体信息等等,都是浏览器指纹,但是这些容易伪装,还有更吊的指纹。

高级硬件指纹技术是一种长久有效的追踪技术,即使快排挂再多的代理IP,即使你换cookie,即使你换header,但是如果硬件信息指纹单一(如selenium),也能够准确识别你的身份。
有一家老板跟我说,他每天让快排商刷1w左右的点击,百度统计后台确实看到了每天一万左右IP,但是百度站长后台只有3000来个点击,这就是百度流量审计系统用高级指纹技术识别了大部分点击。
普通指纹
基于header头、navigator的客户端标识,包括cookie、userAgent、Platform、屏幕分辨率、屏幕色彩模式、浏览器窗口大小、浏览器类型、浏览器版本等等,这类指纹,大部分的快排系统已经做到了随机,或者半随机的对抗。
码迷手头四套快排系统(1套java、3套python)均header头、navigator做了更改,这里不再赘述,大家可以自行百度。
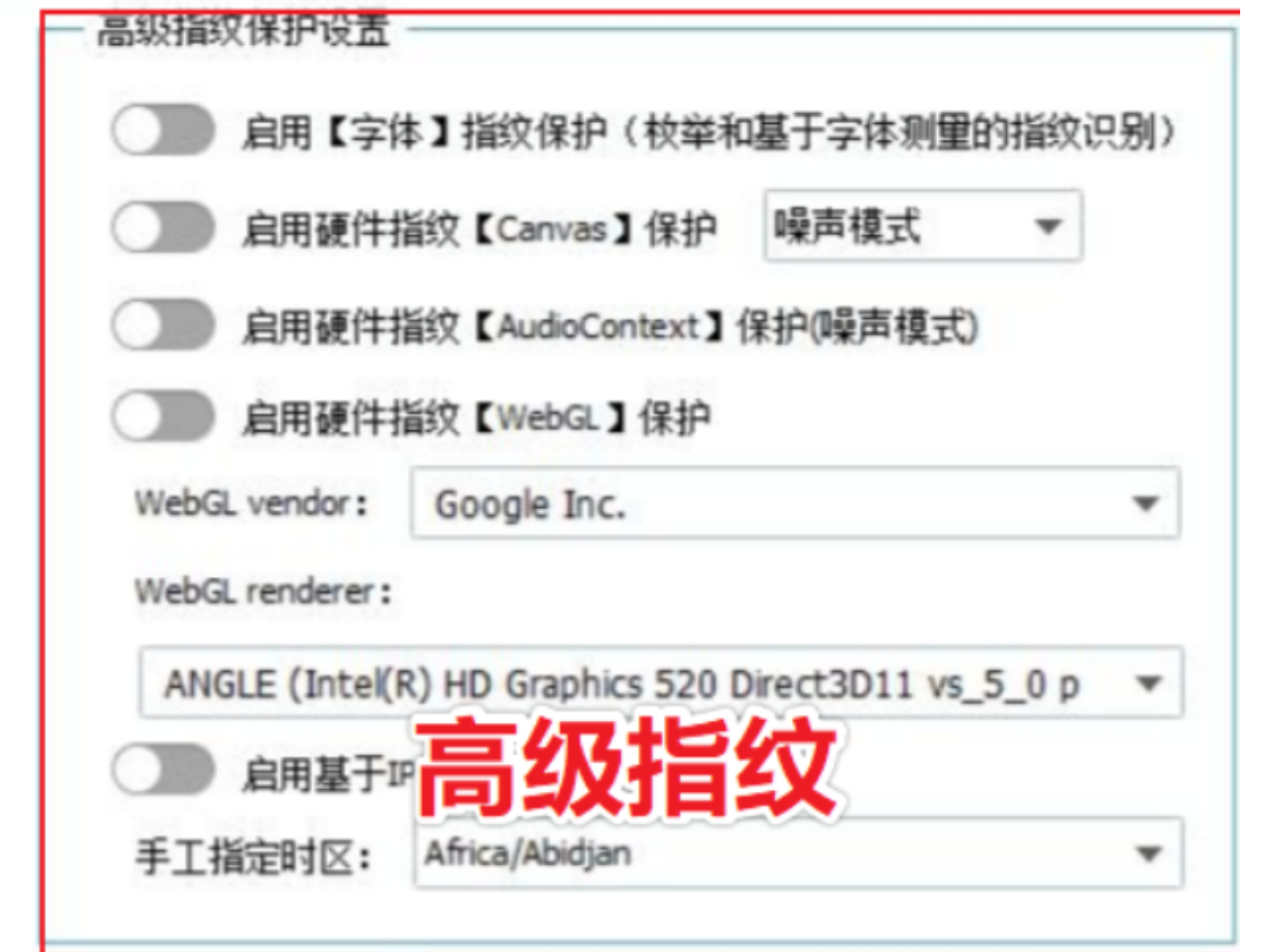
高级指纹
码迷手头四套快排系统代码中均无涉及。
高级指纹包含字体指纹、canvas指纹、硬件指纹、WebGl指纹、媒体指纹等,码迷在上家上市公司做Feed推荐的时候,一度使用canvas指纹来作为用户标识,而周围同事也有好几个是百度产品经理出身,所以我觉得百度使用canvas作为指纹的概率也非常大。
下图是测试妹子推荐的换指纹浏览器(类似于Multilogin),底层也是基于selenium,有兴趣的快排开发可以参考一下。
1、 字体指纹[星星符号]
难度指数:★✩✩✩✩
基于用户所使用的字体种类及字体在浏览器中被绘出的方式,通常,网站在浏览器指纹识别时有两种运用字体的方法,枚举字体列表+基于字体测量的指纹识别。
枚举字体列表可以造假,而基于字体测量成本较大,我估计百度不会使用。
2、Canvas指纹
难度指数:★★★★✩
一线大厂包括阿里、腾讯经常用的浏览器指纹识别方式。Canvas 通过命令浏览器绘制一个隐藏的 Canvas 图像来实现指纹识别。在不同的机器上,这张图片的绘制结果略有不同;
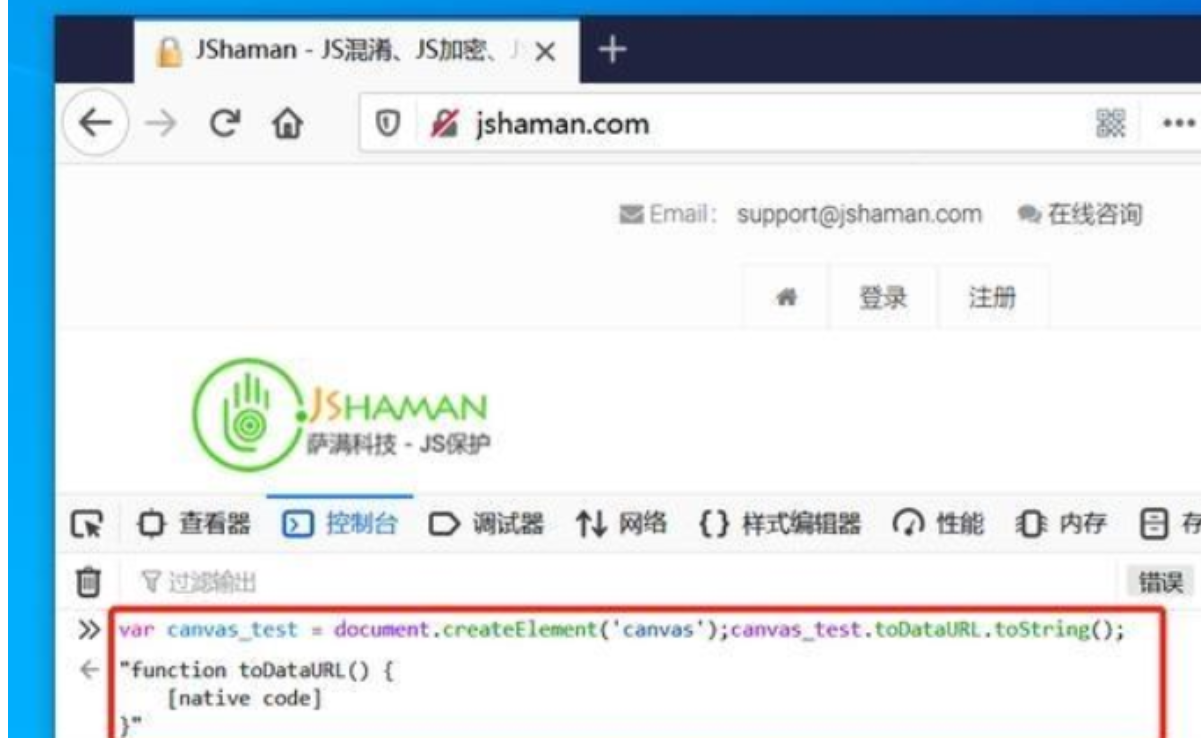
但如果机器相同,则图像也相同。图像被绘出后,它会被转换成一个哈希字符串,被进一步用于身份验证的额外熵。
Canvas指纹的破解方式主要是覆盖原始算法,重新定义toBlob,toDataURL,getImageData三个函数就可以。
但是检测它被破解也很简单,通用的方法是看这个函数的定义能否toString()。如果一个函数的定义是[native code],那么说明是该函数原生的,未被修改过的。
3、硬件音频指纹
难度指数:★★★★✩
AudioContext 指纹(也被称作“音频指纹”)是设备音频栈的哈希衍生值。它的工作原理如下。基于您的音频设置和硬件,网站浏览器把播放音频文件的方式模拟为一个正弦函数。这个正弦函数
被转化为一个哈希函数并发送给服务器,作为浏览器指纹识别中的附加熵。
破解方法可以参考:AudioContext Fingerprint Defender
4、硬件WebGL指纹
WebGL指纹的获取,主要有两个方面:
1. 完整的WebGL浏览器报告,其中WebGL Renderer 可以获取gpu信息哦。
2. 生成WebGL图像指纹,最终结果取决于进行计算的硬件设备,因此此方法会为设备及其驱动程序的唯一值
难度指数:★★★★★
主流方法是WebGL报告造假,并且关闭WebGL支持。
硬货:
看到了这篇内参之后,觉得破解没有问题的,因为会c#、python,而且一直很牛逼的,研究了1个礼拜就把所有的指纹全都破解了,我要去群里吼一声,割韭菜去,欧耶!!!

但是,码迷想说的是,百度对于点击识别归根结底是硬件背后的用户的真实性,甚至跨终端的用户身份融合百度也很拿手。那么快排不同技术用户的真实性,我们简单从3个方面来判定:
1. 如果某指纹信息从未见过,那么是百度新临时用户
2. 如果某指纹信息频繁出现,那么是百度恶意刷点击用户
3. 如果某指纹信息有历史,行为正常,那么是百度正常用户
全随机指纹肯定会导致大量的新用户点击,但是一个网站,不可能完全由临时用户组成,所以哪些指纹应该全随机,哪些指纹应该半随机,是现在快排系统的必须迭代之路。
二十、SEO内参(20) 网站秒收策略:基于时效性算法促进内容快速收录
编者按(2023):
已经被收录&索引的页面,在某些条件下(点击累计到某个阈值、301跳转触发、快照投诉、网站故障恢复等),会触发索引更新的流程,导致页面重新收录。
反推技术利用触发[快照投诉]造成索引更新,给大家来蜘蛛的假象。其实反推对新增收录作用不大,因为索引更新需要有原始页面存在,而反推的页面大部分没有原始页面。
时效性算法起来的站点,初期权重高流量少,但是确实会引流蜘蛛,缩短流量站的起站周期。
配合时效性内容,再针对高搜索需求的关键词,大批量生成高质量页面,事半功倍。
一定不要做黄反相关、涉Z的热搜关键词
今天分享一个网站秒收策略,基于时效性算法,可以有效缩短内容快速收录流程。
好多朋友说因为百度熊掌号推送接口的下线,现在收录非常难,所以为了达到秒收可谓无所不用其极,看了大家的网站秒收策略,各种“吃快餐”的方法招式都憋出来了。
什么秒收蜘蛛池、link反推技术、快照反推技术各类杂七杂八的大招闪耀登场。

码迷之前关于反推技术公众号文章曾经说过,无论是反推还是蜘蛛池本质上只是推蜘蛛爬虫队列的调度影响,而并未涉及到任何后续程序(内容判重、质量判定),所以从6月份反推技术的推出到目前为止,你也没见到几个站因为反推起飞了。
反倒是大家当韭菜的热情高涨,一茬接一茬。
码迷花了1000块钱买了反推算法,还花了一天优化了反推技术的泛推送算法,一台机器一天跑下来才能破译2000个左右的反推地址,配合打码平台以及百度站长后台cookie, 只有50%左右的能反推成功。
昨天新站推送完成之后,今天只有25个蜘蛛。
费了这么大力气推送,你就来25个蜘蛛??
话说这反推推技术,还不如我用随机内链来的直接。

现象:何为时效性内容?
我们先从游戏站说起,随手一个流量较好游戏站,你会发现绝大部分有“资讯”、“新闻”类的相关频道。
但是你看他内容,又会发现基本是基于复制粘贴的采集。
新闻性质的标题只会有短暂的排名,远远不如长尾词稳定,另外采集也不利于网站信任度的提升。
所以做新闻资讯这类的内容看起来性价比极低,这也正是很多站长纳闷的地方,甚至很多站长坚决抵制采集。
但是更神奇的是这些游戏资讯,虽然是采集,但是并未影响目标网站的收录,也并未影响网站的整体排名。
相反,这些采集的资讯内容甚至都是带出图的,明显是获得了百度的认可。
原因:采集的内容为何过百度?
五脸懵逼的站长们开启了热烈的讨论:
A站长说:人家权重高啊,你有那么高权重你也可以采!
B站长说:人家有其他原创内容撑着,已经过了百度信任度了,可以采!
C站长说:百度一点也不保护原创权益,内容好歹也是小编们花了功夫的,我最恨别人采集我的内容了!!烦!
D站长说:你采集你上涨,我采集我下降,5555

不同的采集源头,不同的采集内容加工方式,会导致不同的结果。
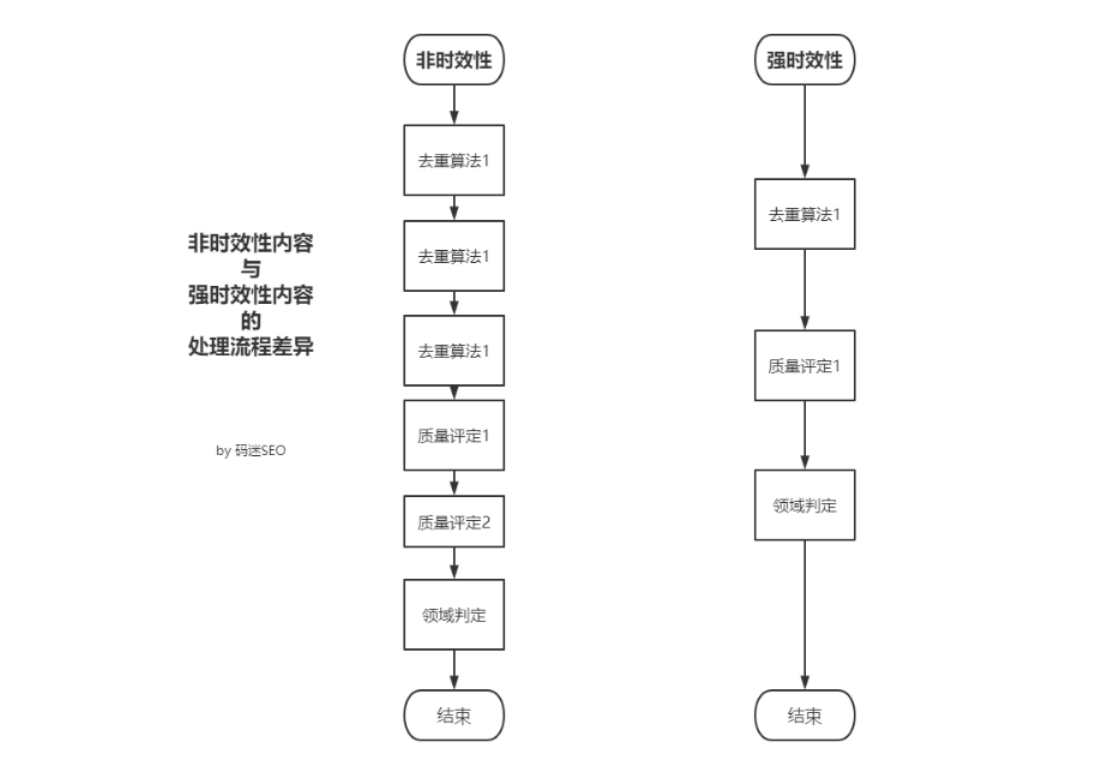
我们知道,百度对网页处理的流程非常复杂,类似于下图(图片出自《SEO内参(一):百度搜索引擎的工作原理及流程》)。
从原创检测、到内容质量评定、以及各种链接处理,整个流程下来3天到1个月不等。
那么问题来了,新闻类型的页面,如果还是走的正常的处理流程,那今天的新闻最早也要在三天后才能在百度里面搜索到。
这显然不符合时效性的要求。
那百度怎么办?
也就是说新闻、资讯等时效性较强的内容,必然与非时效性内容有不同的处理方式。
这就是根本所在!
1. 内容处理周期更短。
2. 内容处理步骤也更少。
3. 排名处理的步骤一个更更少。
再举一个例子,一些灰色行业,比如零距离用泛目录站,为了促进收录,会非常努力的把内容包装成为具有时效性的新闻资讯,目的就是为了搭上时效性算法的快车道。

原理:时效性秒收根本因素
并非所有内容都原创就是好网站,原创+时效混合搭配才是好策略。
时效性采集简单来说就是内容可采集又能来点流量。
码迷在《SEO内参(四) 从SEO流量站套路到百度资源分配策略解析》强调过百度资源分配策略的重要性。
百度资源分配策略主要思想就是物以致用,没有点击就没有爬虫,没有爬虫就没有收录。
而时效性采集不仅是相对低成本生成内容的方式,更是无排名站强制点击的手段之一。
时效性内容非常容易培养出蜘蛛习惯,拿到天级监控资格,从而达到秒收的效果。
当然,时效性内容如果一旦做了,就要长期来做,药不能停了,一停就容易掉排名。
套路:如何做时效性内容
除了游戏行业,像泛娱乐、电子评测类、女装类、股票类,配合时效性内容促进排名收录,已经是行业站的必备手段了。
如果你的网站长期的更新原创内容,但是蜘蛛来的少,或者一直没有排名。
那么你应该考虑做一些时效性内容的内容了。
1. 寻找行业时效内容。
网站时效性是搜索引擎判定网站需求覆盖度的指标之一,不同行业的比重不同。
比如软件站中游戏新版本的发布、娱乐站中娱乐人物热点事件新闻、时尚站对明星穿搭的跟踪报道、电子产品导购站队新显卡的评测说明,都是非常关键的内容点。
2. 定时监控稀有新闻源站点。
为啥是稀有新闻源站点,因为在保证内容具有时效性的同时,内容的稀有性也很重要。
比如行业前三的网站,发布内容后1天内,会有10个以上的网站采集转载,那么你采集了以后,百度肯定觉得也不香啊。
所以寻找那些定时更新,但是内容飘红比较少的站点就行了。
3. 采集后内容处理。
码迷之前提到过百度原创检测算法有三种,那么针对时效性内容,只跑其中的一种简单的就行了。
普通内容质量性要求很高,需要做相关性判定、领域判定、通顺度判定等,但是时效性内容可以只要过了标题相关性就可以放行。
所以怎么去做采集后的内容处理,码迷就讲到这里。
二十一、SEO内参(21) 细数搞原创文章的奇葩招数,咱都想不到啊
编者按(2023):
用ChatGPT吧,SEO老人们
正文开始:
因为SEO是玄学,所以大家招数都很多,尤其是在搞SEO文章的时候,小伙伴们都是天选骄子,不仅复制粘贴大法练得炉火纯青,还能憋出一万种方法搞定原创。
风口上的猪为什么会飞,因为顺势而为。 所有的招式,都有它出生的时代。码迷SEO根据招数出现的时间,结合当时的算法背景,咱们一个一个来讲。
招式1:多篇采集组合
流行年限:2016~2019
方法说明:
首先,采集的对象一般为百度百科、搜狗百科、360百科等等,多篇组合为一篇,然后组合成10w+以上的文章开怼搜索引擎。

其次,为了提高搜索爬虫的爬取频率,缩短收录时间,泛域名站群、百度批量推送工具、熊掌号批量推送工具应运而生。
虽然说2017年百度已经推出了飓风算法,严厉打击恶劣采集,但是百度的去重算法还是比较粗糙,仅能识别单篇文章与单篇文章之间的对比(有兴趣的可以去看一下SEO内参飓风算法一章),而且采集组合后的文章往往内容更加丰富,所以采集组合上站很快,起站很爽。
采集组合SEO效果好,是人就能挣到钱,各路培训开始大行其道。但是好景不长,2019年年中百度飓风3算法上线了,喵的原创检测级别竟然达到了句子级,所以采集组合方式开始衰弱。新的招式呼之欲出,百花齐放。
招式2:多篇采集+伪原创洗洗
流行年限:2019~2021
方法说明:
首先,根据关键词到批量采集文章,形成初始语料。
其次,对已经采集的文章进行双重翻译。就是把中文翻译成英文,在翻译成中文。或者把中文翻译成日文,再翻译成中文。
最后,再去组合相似的3~5篇文章,形成一篇新的文章。
洗稿的方式并不限于双重翻译,某8的智能改写,各行其道的AI伪原创工具,要么基于同义词字典替换,要么是双重翻译。
但是伪原创搞得不好用户体验就不如原文了,所以伪原创是个技术活。
其次,双重翻译还要做软件对接接口,对于咱们这些不会撸代码的小白来讲太不友好了,所以众多大师的奇葩原创算法在2019年中开始萌发壮大。
招式3:多篇采集+句子重组
流行年限:2019~2021
方法说明:
飓风三算法发布后,2019年底有一波旅游、房地产、股票的网站非常猛,比如重庆旅游网、淘房T网,内容却非常奇葩(PS因为之前网站都关站找不到了,意思跟大家说明白即可)。
首先,采集百科或者竞品的网站。
其次,以逗号、句号、问号为分割点,把文章切分成小段句子。
最后,把字数少于20字的句子剔除,只留下长句子,然后把长句子重新组成一篇新文章。

算法虽然粗暴,但是3个月上PR6,还能维持半年+不死。有条件的话,再配合一波点击,让搜索引擎认为用户想要的内容就是这样的内容了。
码迷SEO群里好多人现在也这样玩,也搞的风声水起。要不是疫情打击了旅游业等很多行业,估计搞到现在还香喷喷。
招式4:小说语料+强插关键词
流行年限:2020至今
方法说明:
绝大多数人应该见到过类似于笔趣阁的小说泛站页面。大致的运行原理是准备大量的小说语料,可以做成段落,也可以做成句子级别。然后再重新组合为新文章。因为新文章缺乏相关性,再在文章里面插入相关词(相关词不限于百度下拉词,相关搜索词)即可。
如此一来,句子拼凑可以过飓风3算法,然后强插关键词可以过相关性算法,还是有效果哦。
类似笔趣阁的算法,句子段落拼凑,很多大师级的SEOer也搞过不少,但是这种站点2020年中之前还凑合用,2021年貌似百度算法有升级,绝大部分网站只有20天左右的效果。
最后:
搜索引擎算法在变,码迷观察最近半年采集组合的页面获得排名的机会越来越少,反而小而美,能直达内容答案的页面更容易获得排名。
一方面,句子的通顺度、逻辑性、前后段落语境相关性,已经实实在在的纳入到站点考核当中。
另一方面,点击率越多用户体验越好(某度就是这样认为的),组合文又长又臭谁愿意看啊。
所以,采集还是要采的,但是不一定要去组合了。
多说一句:任何知识都有它的两面性,在SEO中,少吃亏少踩坑就是宝贵的财富。
二十二、SEO内参(22) 头条流量站套路,小白一年起10个流量过万的网站
编者按(2023):
头条采集站目前依然可行,闲鱼上有配套的“头条采集软件”,100元以内就能搞定。
既然内容可以用头条采集解决,那关键词肯定是核心中的核心啊,本文中也提及了靠谱的筛词方法。
ChatGPT不香吗,闲鱼上AI批量生成软件也不到100元。
正文开始:
现在把最近的压箱底SEO玩法拿出来分享给码迷SEO群的同仁们,价值不到9001元的头条精品站套路,小白可操作,一年起10个流量过万的网站不是问题,非常适合低成本引流。
别看SEO流量已经被很多媒体渠道蚕食,其实SEO赛道上的人也越来越少。
其次,现对于抖音类这类短效性流量,SEO的自然流量更持久,更省心。
不过在分享开头,还是要申明一下,我分享的任何套路,并不是长期可用的,因为百度的算法一直在迭代。但是其中的思路,我个人感觉依然有价值。
内容会分成4个部分:
第1部分:现阶段搞SEO流量背后的逻辑
第2部分:如何精细化选择长尾词
第3部分:利用信息差批量化搞文章方法
第4部分:发布到个人网站
第1部分:现阶段SEO选词背后的逻辑
如果一个行业,人群聚集在短视频、社群渠道上更多,就不要做网站搞SEO;而且这几年由于某度自有流量池的强化,大家看移动端,首屏几乎都被爱采购、精选专业问答、百度推广,好看视频霸占,尤其是医疗行业,没有钱怼就不要做了。
所以,如果没有财力物力,就避免与某度自家的流量硬钢,但这并不代表SEO没法做。
首先,因为某度垄断的流量更倾向于高竞争大词,而那些长尾小词就是漏网之鱼。
其次,由于目前小白SEO从业者的逃离,随着网站的倒闭,第二第三页的流量获取更加容易。
然后,搜索首页结果体验太垃圾了,已经让部分用户培养成不看第一页的习惯了。
比如:“英国大学有哪些” 这个词,首屏基本是他们自己的流量。
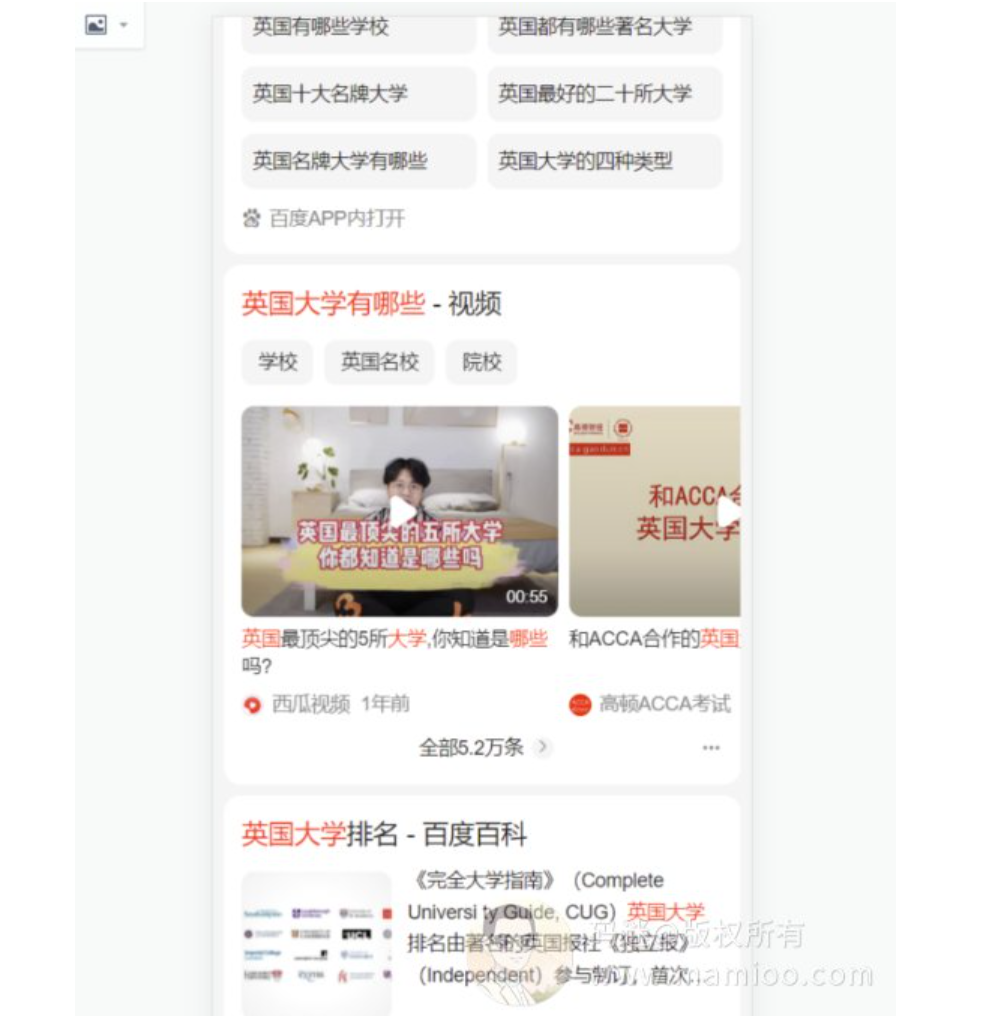
但是 “英国物理好的大学”,这类稍微长尾的词,首屏就有几家非百度系流量,那么这类可做。
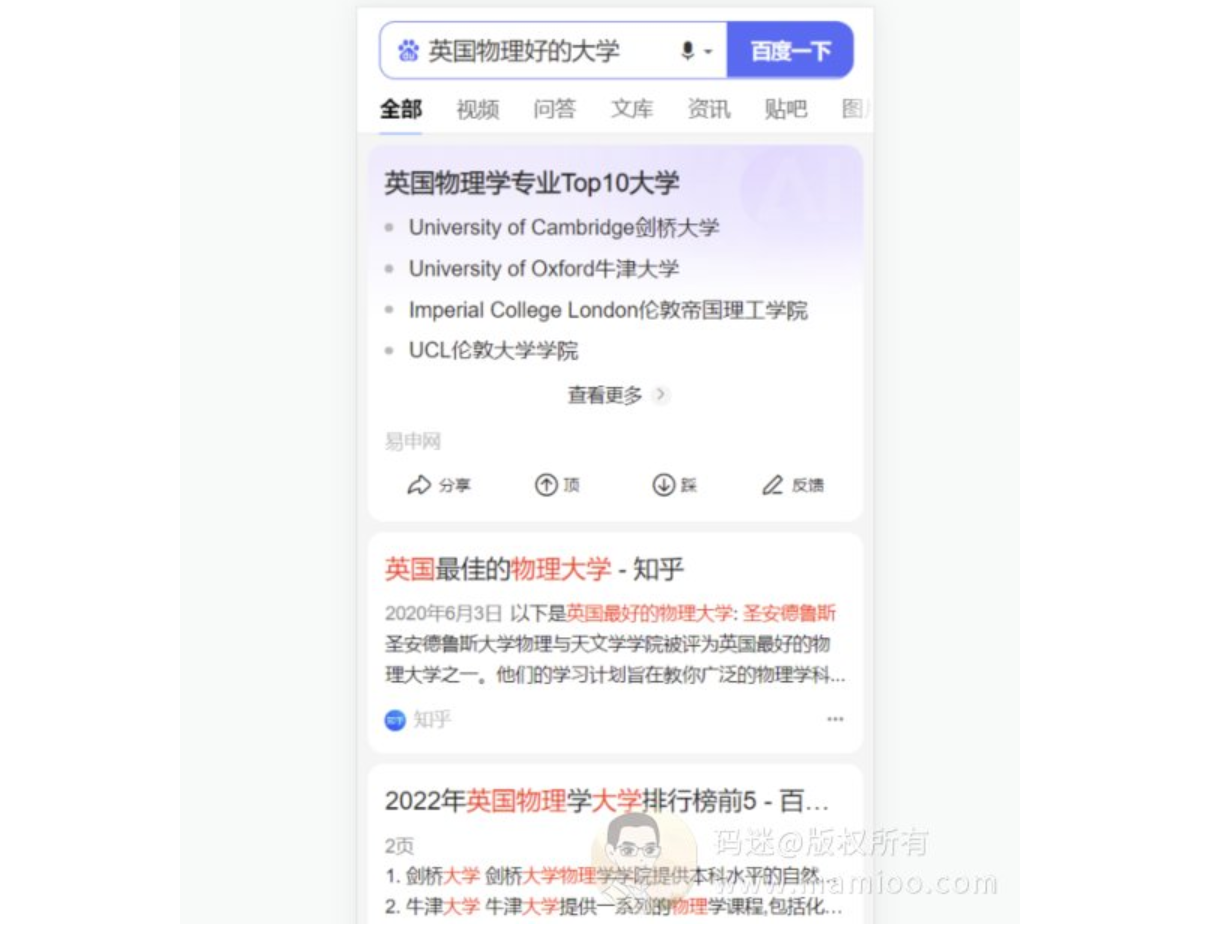
所以说,我们方向是,选择竞争小的行业,选择多做那些主观性偏强的长尾行业词,事实也证明了确实如此。
第2部分:如何精细化选择长尾词
一个合格的关键词,要有人搜索(有移动流量),又要避开竞争(避开百度系)。方法如下:
第1步:把主行业词切分为行业小词(以劳动纠纷律师为例)
结合自己的业务需求,把主业务切分为子业务,然后通过子业务通过自己的专业知识去挖掘业务词根。

我这里一般一个主业务分析出200个左右的词根就可以了。
第2步:通过业务词根 一个一个 查询长尾词。
我使用的是站长之家的星网大数据,用5118的也可以。具体的使用方法圈友的文章有很多介绍的。这里只提两点:
(1)竞价过多的不要
(2)没有移动搜索量的不要
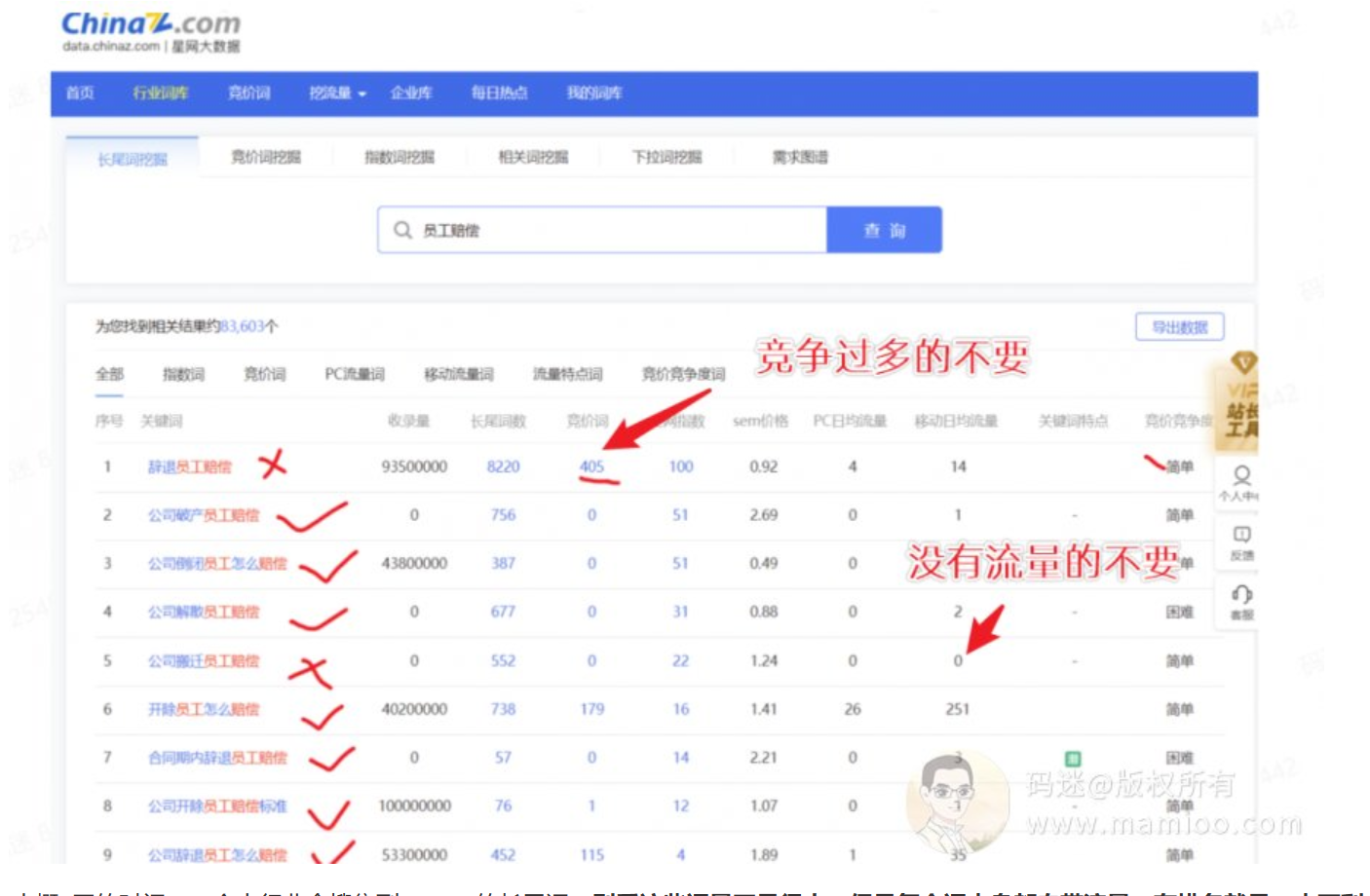
快的话,大概2天的时间,一个大行业会搜集到2k~10k的长尾词。别看这些词量不是很大,但是每个词本身都自带流量,有排名就是一本万利。
然后,接下来我们就围绕着这些长尾词做内容了。
第3部分:利用信息差批量化搞文章方法
信息差不仅存在于人与人之间,也存在于搜索引擎之间。比如说,百度百家号的内容目前被头条收录的很少,同样的头条号的内容目前被百度收录的也很少。
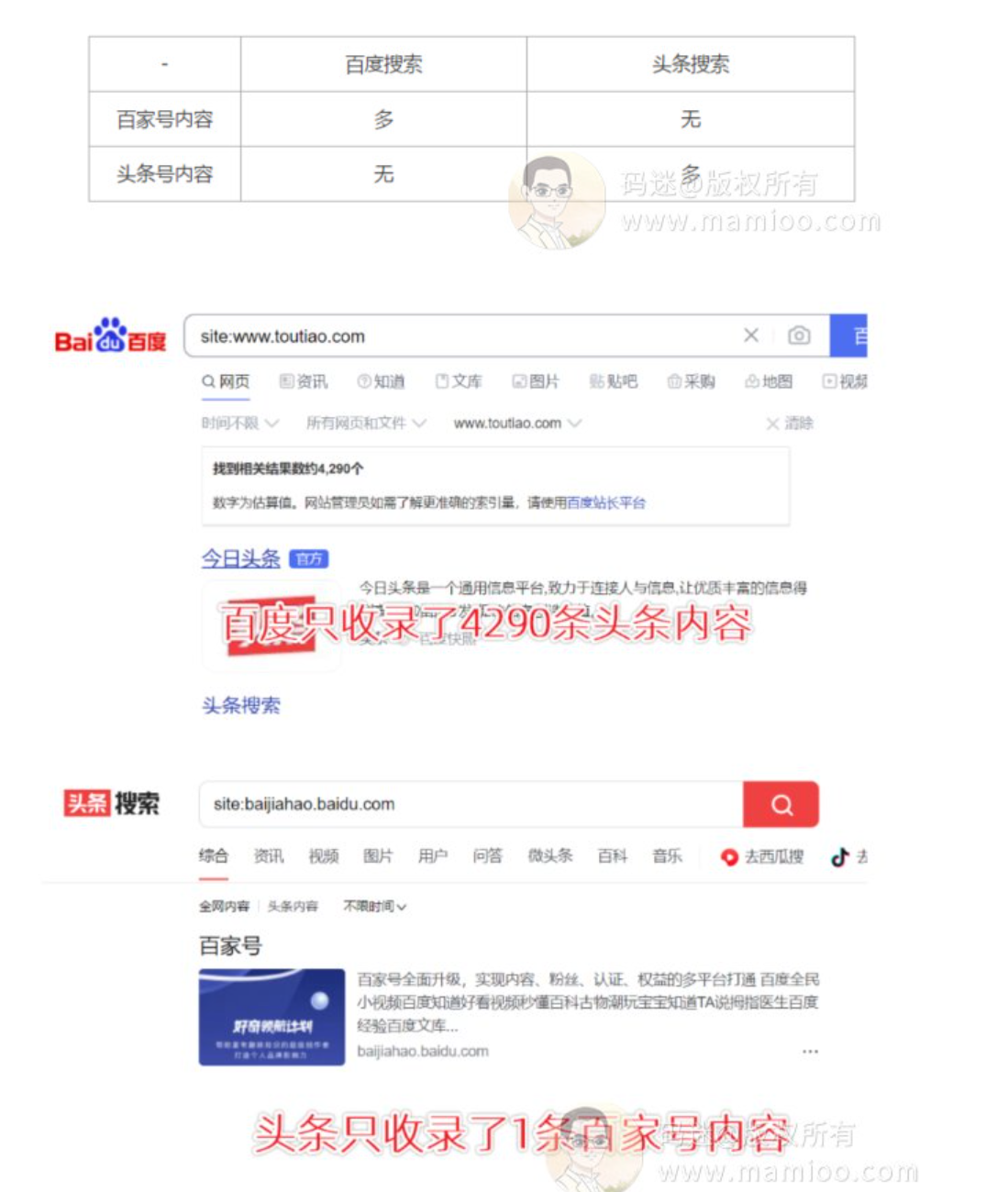
这里大家可以思考一下,以此类推企鹅号、大鱼号、微信公众号是否也可以做网站的内容来源?
这里再提示一下,比如头条系的悟空问答,百度收录了2300多万。
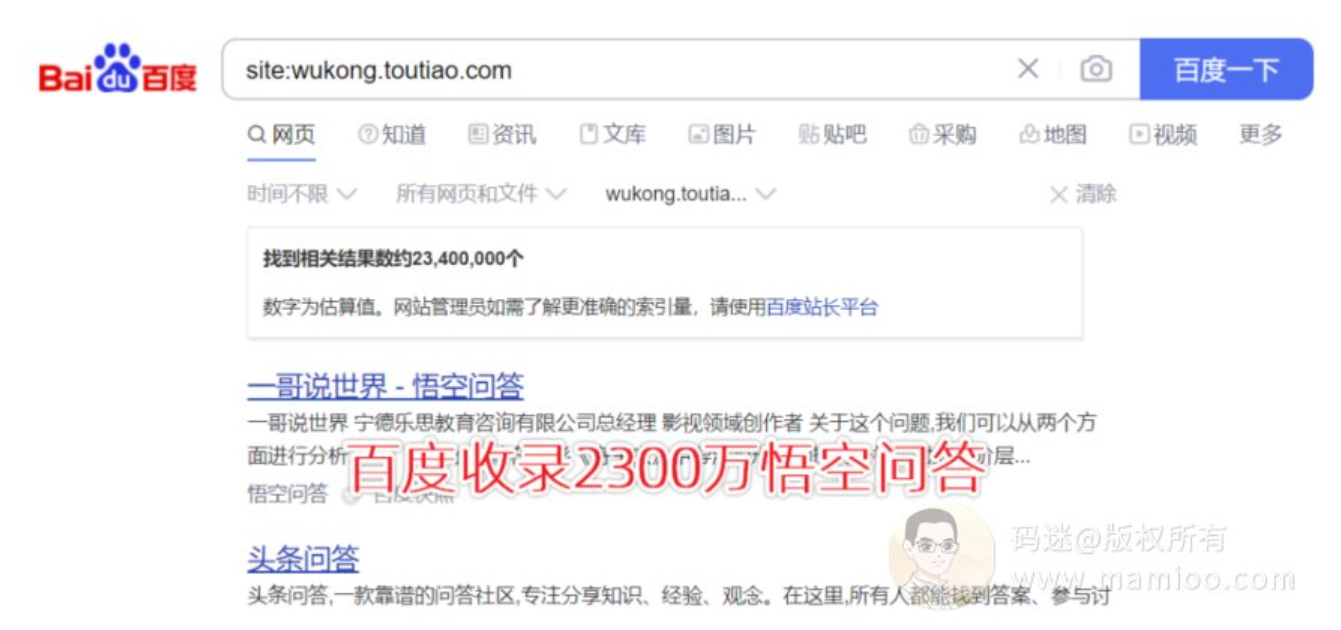
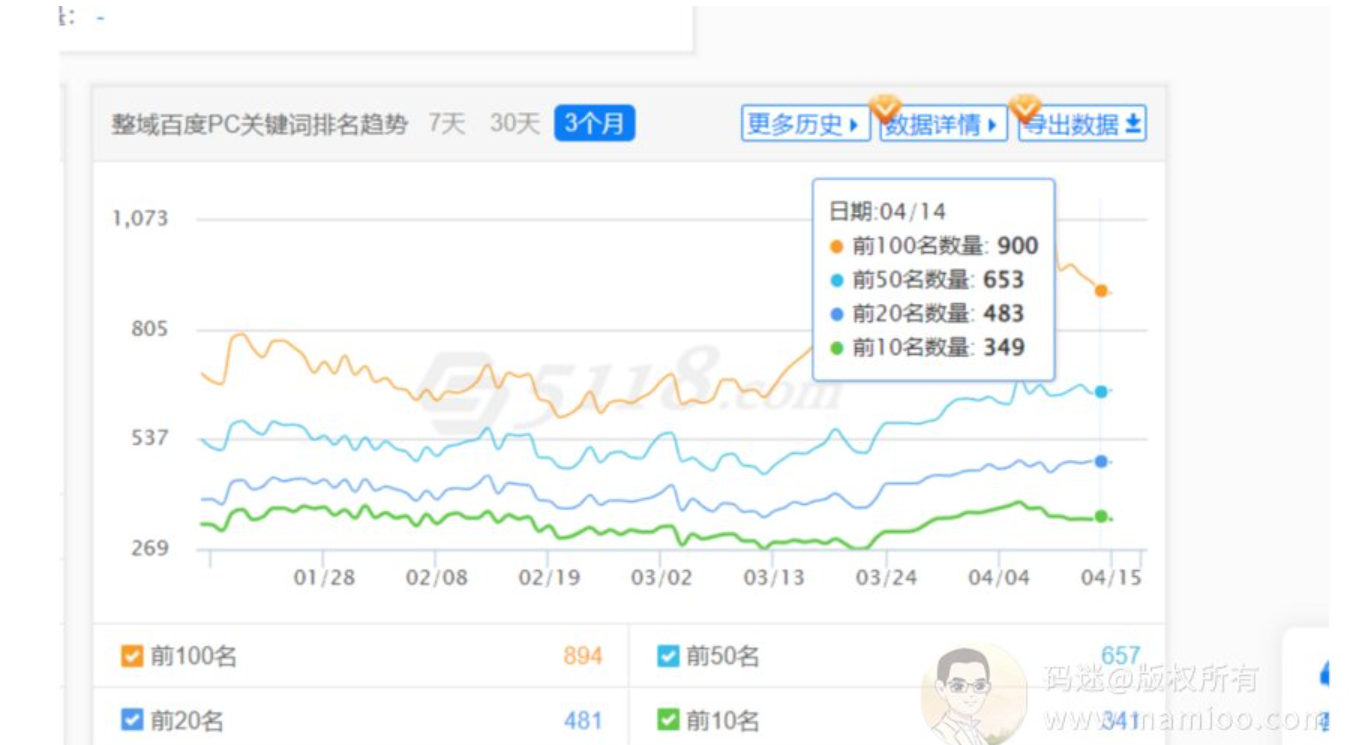
但是我们通过5118查看wukong.toutiao.com的排名数据,前十名才300来个关键词而已。说白了肥水不流敌人田,某度不愿意给头条系导流量而已。
那么设想一下,如果你不是头条,但是你的网站却有如此丰富的内容呢。
好了,下面我把详细的步骤全盘托出,有编程能力的朋友可以搞批量化。
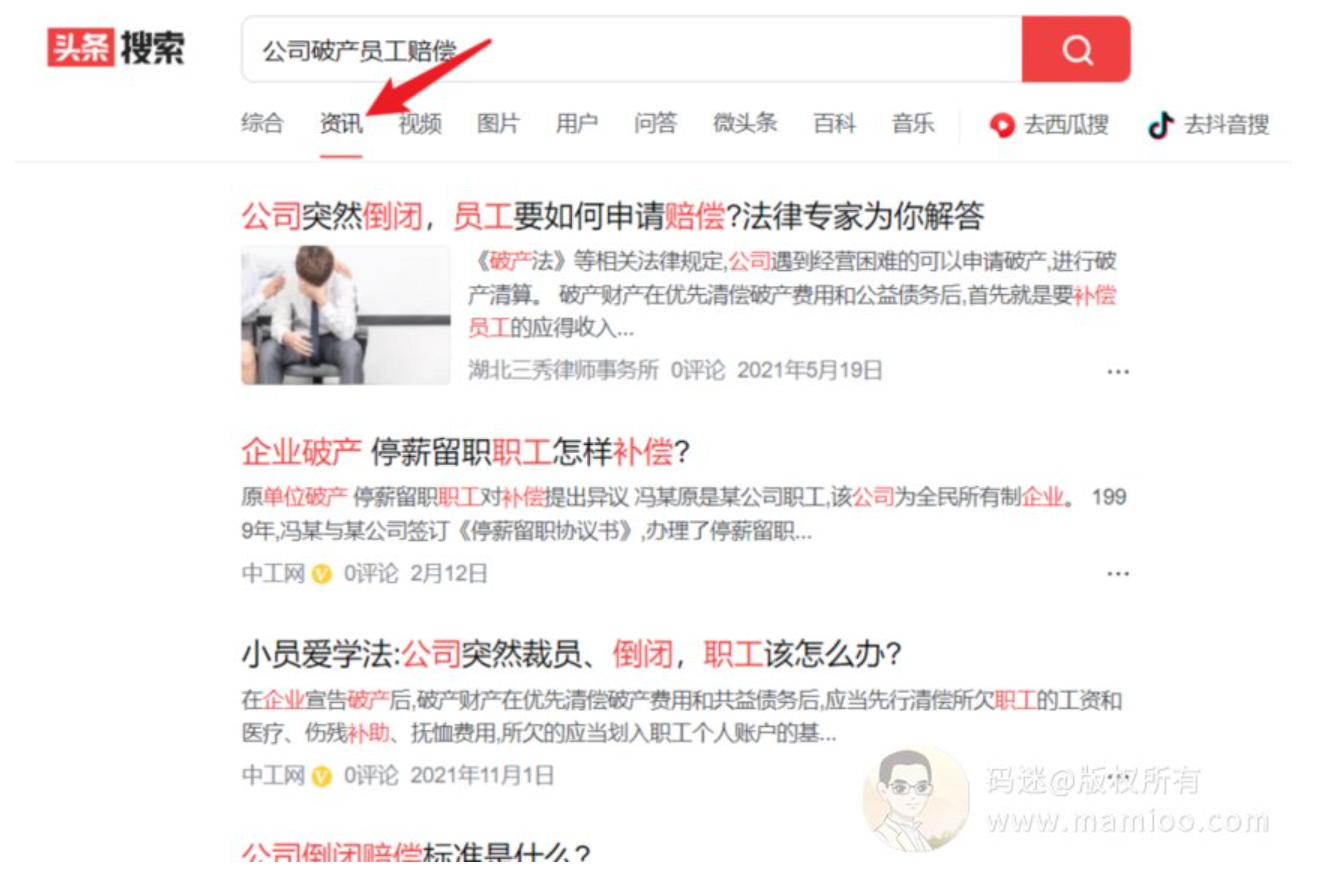
第1步:用长尾词搜头条的资讯
第2步:搜集内容
选择搜索结果的前3的某条号内容,找出里面内容字数最多的那篇文章作为CAI集目标,再把里面的内容剔除图片,只保留文字即可。
重点说明一下,一定不要使用人家的图。
第3步:换标题
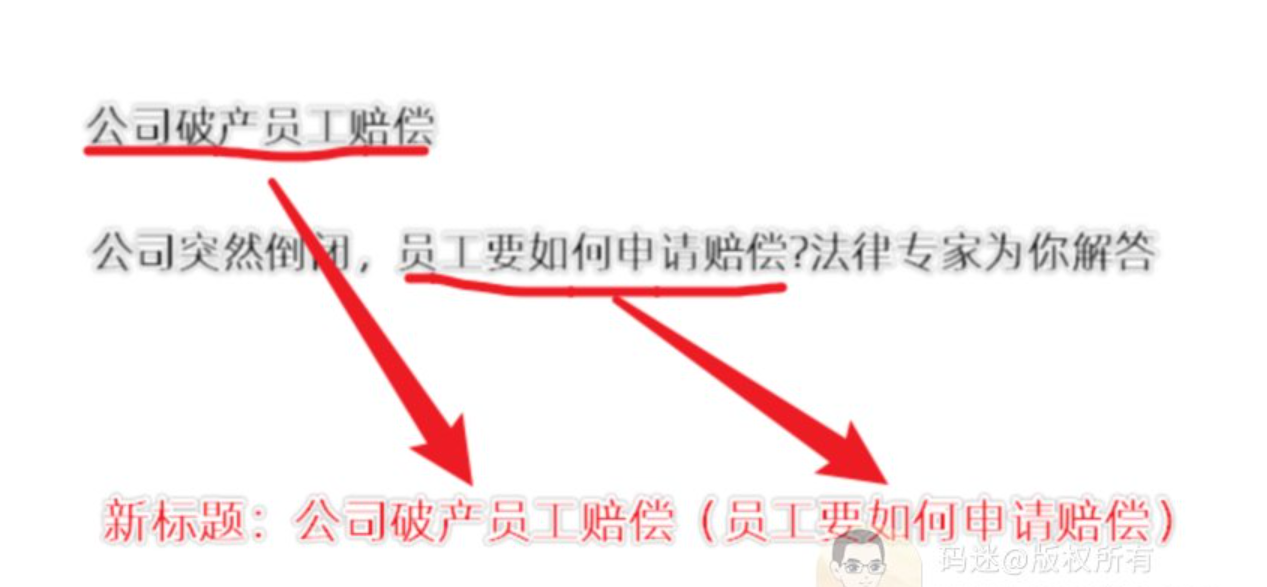
我这边的方法是:新标题=长尾词+头条内容原标题的核心句子。
比如 长尾词是 【公司破产员工赔偿】,头条原标题是《公司突然倒闭,员工要如何申请赔偿?法律专家为你解答》,那么新标题就是:《公司破产员工赔偿(员工要如何申请赔偿)》。
生成新标题的算法不同人有不同的算法,各有千秋,但是长尾词一定要放在前面。
最后是这样一个效果:
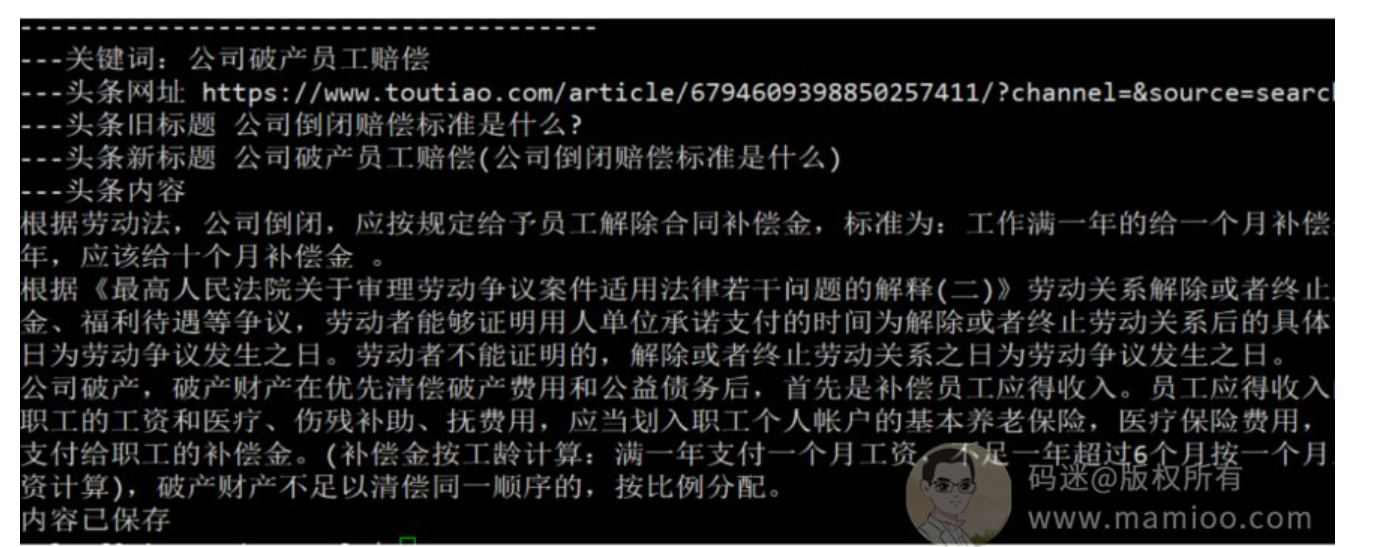
第4步:发布到网站
尽量不要用公司的网站,因为搬运有风险,操作需谨慎。
总结一下下:
如果用一句话总结这个模式,就是找2000+个长尾流量词,从头条找内容,换标题,发布到我们网站中。
是不是很简单?做SEO目前就是这么简单粗暴,只要百度肚子里面没有的,粗暴怼就行了。我们随后用自动化程序,每天给每个网站发200篇左右的内容,坚持6~12个月,每天每个站就会带来1w+的流量。
但简单的模式背后,包含了许多研究和细节。我觉得从这个案例中,能总结如下一些做内容和流量的思路。
1、优质的长尾词
选词非常非常重要,要静下心来寻找自带流量竞争度小的长尾词。因为不同于短视频追求“爆点”标题,自带流量的SEO标题才能细水长流。不要看有些SEO同行20w30w的用垃圾词怼搜索引擎,他们的产出比就是shit好吗?
2、多找信息差
人有盲点,搜索引擎也有盲点,有围栏就有信息差。把海外youbube优质视频搬运到国内平台,或者搬运到TikTok,把微头条搬运到企鹅号,甚至要有人把明星微博内容做成视频搬运到抖音、西瓜、好看视频。与此同时,去水印、删头减尾、画面剪裁、调色、加滤镜,调速等生态工具应有尽有,即使没有的也可以花钱开发。
3、他会成功你也会成功
你跟我一样,都面对同样的渠道平台,都是处在相同的抖音算法、百度算法、头条算法环境。如果您复制了他的成功套路,你也大概率会成功。但是“凡人”往往热衷于套路的技术细节,把周边工具使用烂熟于心,却拘泥于相同的地盘,跟同门在红海中厮杀;而有“灵根”的修士往往会把套路应用到类似的流量口,一路攻城略地,发现蓝海。
2年前我跟我的SEO启蒙老师请教“一年出3套课,年入百万的培训秘笈”。老师说,一定要真心对待徒弟,把不重要的一定要手把手多教,而重要的要掌握好授渔的分寸,仅此而已。
以上。
二十三、SEO内参(23) 如何评估行业流量,实现SEO利润最大化
编者按(2023):
爱站词云(ciku.aizhan.com) 星网大数据(data.chinaz.com) 都可以查看词库数据量,词越多,意味着流量越多。
如果一个行业最大的网站PR=5,你很难再做一个PR6的站,但你可以做一堆PR4的站。
做不到PR6不要紧,但用站群去垄断某个行业的搜索流量并不难。
正文开始:
今天下午一个20来岁富婆让我教她做宠物站,现在做网站不就是3个抄吗?抄词库、抄内容、抄模板多简单,但是富婆自己不搞,非要我教才行。
在金钱加美色的双重打击下,道德败坏的他只能安排上了。码迷SEO的思路分3步,第1步先通过词根找同行大站,第2步通过宠物大站再找相似的中小网站,第3步初步评估整体的流量大小和打法。
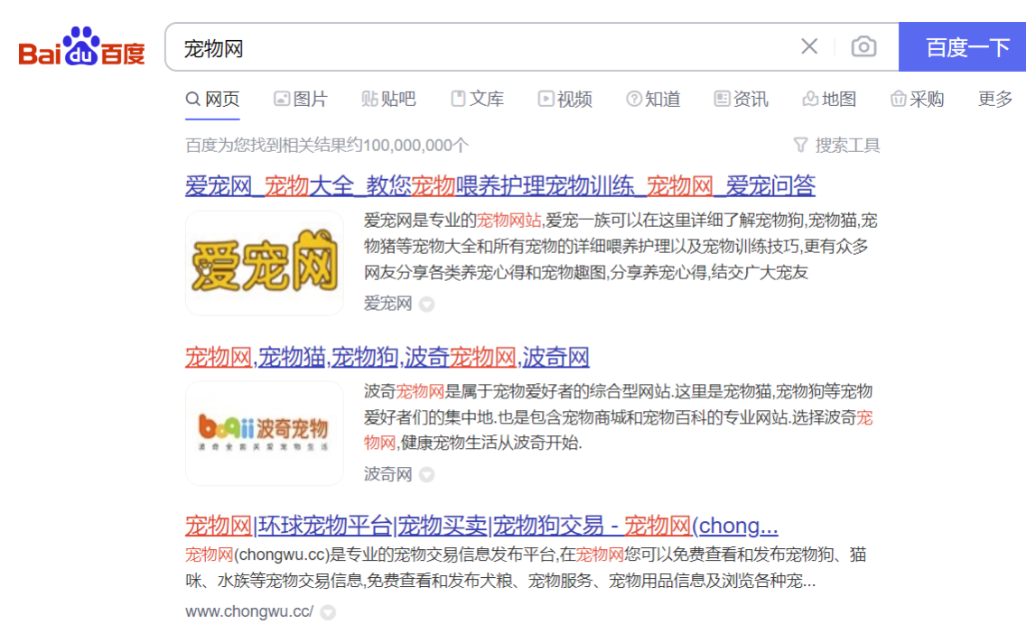
第一、通过行业词根找网站
通过百度搜索“宠物网”,“宠物狗”等,就可以挖到 几个宠物站,如爱宠网、波奇网、萌狗网等。
第二、通过宠物大站再找相似的中小网站
有两个思路,一个是通过爱站词库找网站:ciku.aizhan.com
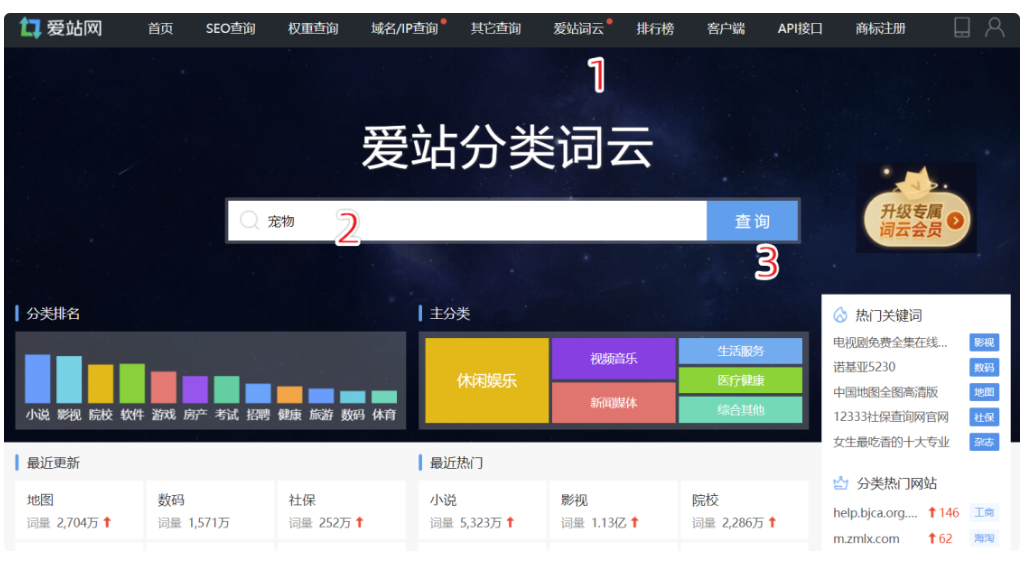
我们到宠物分类词库的页面,可以看到,爱站收录了571个宠物站,相关词在137万左右。
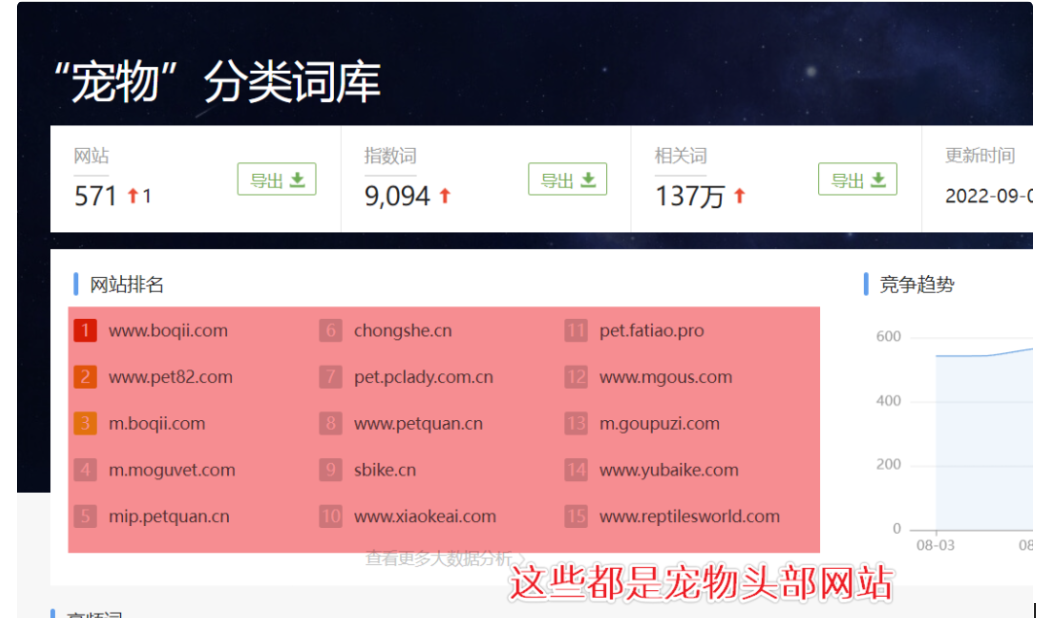
如果爱站没有对应的词库,那就从站长工具星网词库里面找:data.chinaz.com
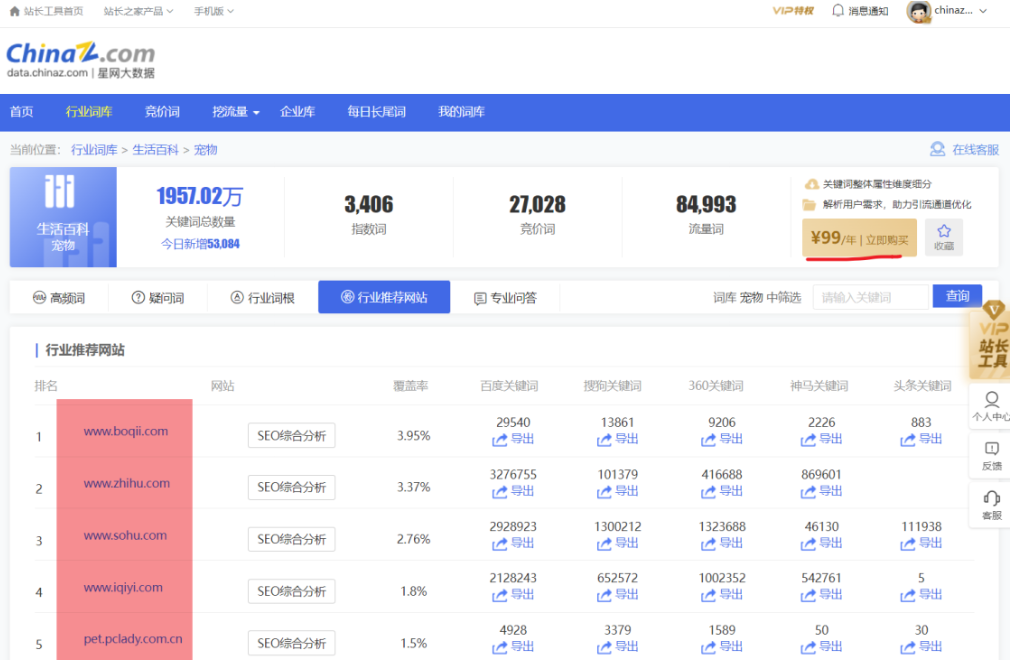
宠物词库每年99,也不贵。
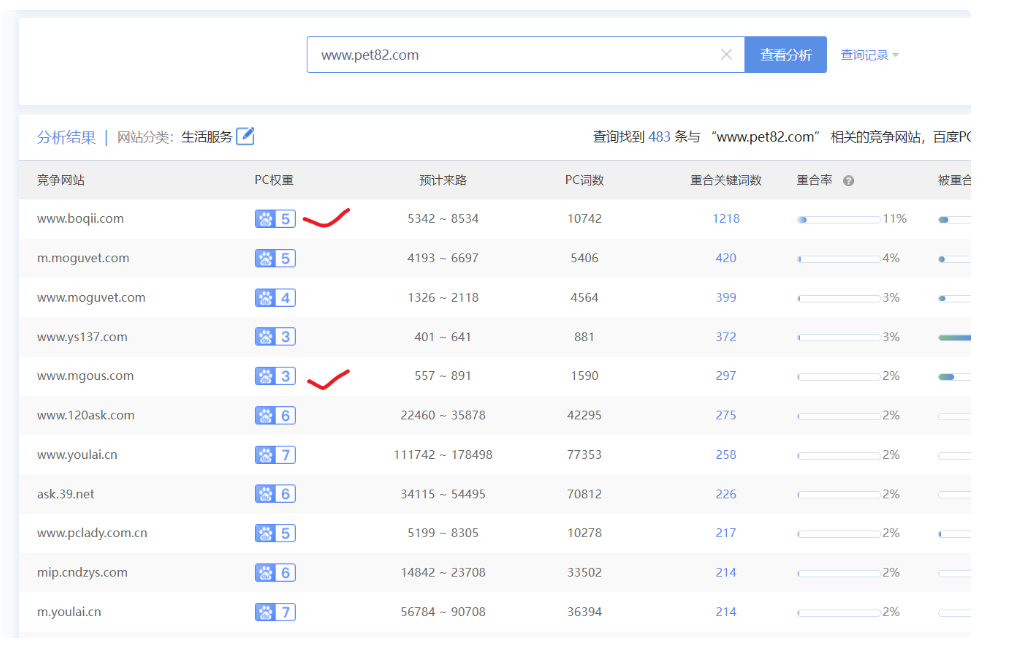
如果爱站,ChinaZ都没有对应的词库,这里还有四个《相似网站查询》工具可以挖据词库相似的网站,

第3步 初步评估整体的流量大小和打法
以站长工具宠物行业词库为参考:data.chinaz.com,如图:
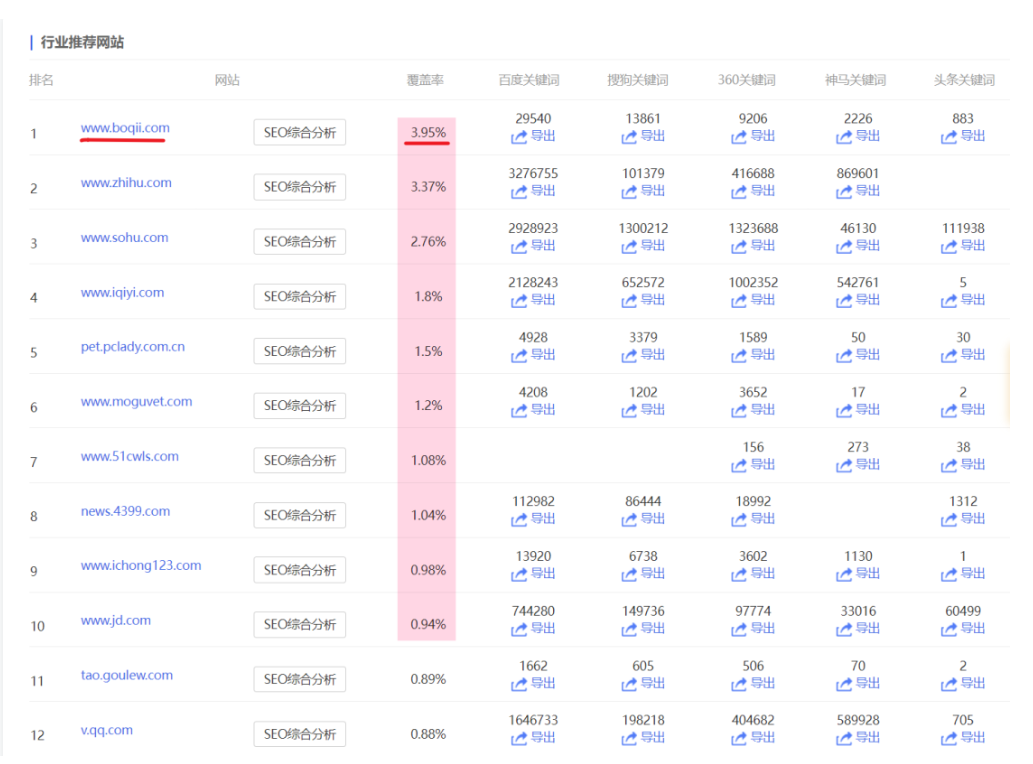
宠物第一大站是波奇网,预估流量为51,506 ~ 82,276IP,按中位数66000算,他的词库覆盖率为3.95%,那么
宠物全网流量 ≈ 60000÷3.95% = 167万。
那么咱的网站有没有机会获得点流量呢,统计一下几个行业TOP10覆盖率如下。
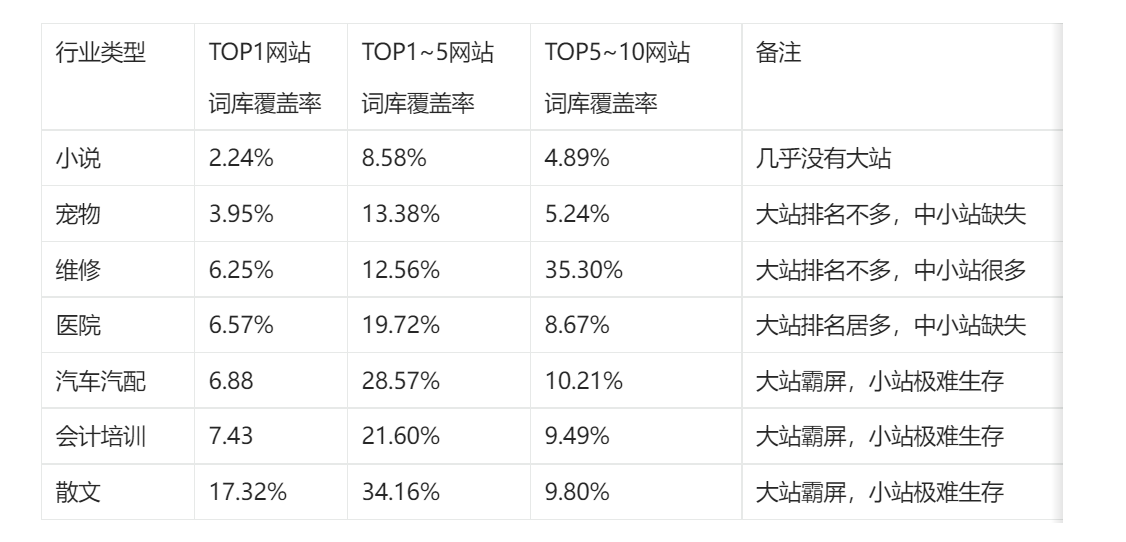
数据原理:
1、TOP1~5的网站词库覆盖率越高,说明百度倾向于给大站流量机会,但是咱们没有机会。
2、TOP5~10的网站词库覆盖率越高,说明机会均等,咱们可以玩玩。
3、TOP1网站的词库覆盖率,说明了咱干到顶了,能拿多少的流量。
解析一下以上表格:
以散文行业为例,top1~5 占据了34.16%的流量,远超过 宠物 行业的13.38,那么就是散文行业 百度更倾向于给大站排名,小站要想获得排名比较难或者周期会很长。
散文、汽车、医院、会计 top1~5 都占据了大约2成以上的流量,这就是大站霸屏,小站极难生存。
维修、小说、宠物 相对来讲还算凑合,但也意味着行业多多少少有点问题,因为没有寡头垄断。
数据结论:
1、宠物行业,大站有那么几个,但是中小站也很少,竞争不大,流量可以搞到手,我们可以去做。
2、如果做到顶了,获得65000个流量已经是顶天了。
再深度思考一下:
1、为什么宠物行业的中小网站词库占比较小,莫非是头部网站苟且吃肉喝汤,中小型网站连汤底子都没有?
2、或者宠物行业中小型网站盈利模式不长久,前仆后继死亡。
然后我搜了一下新闻:
我去,宠物行业果然有大坑,投资宠物行业不好赚钱,赶紧跟富婆说:
二十四、SEO内参(24) 增加收录的核心操作方向是什么?
本文选自码迷杂谈。
之前老码发过一篇《网站秒收策略:基于时效性算法促进内容快速收录》,现在已经两年多了,现在泛娱乐站大多数依然在采用时效性算法来促进收录,具体的操作方法铁子们可以到码迷SEO官网去参考。
时效性算法只是增加收录的操作之一,有同学说老子做的是机械类型的站点,没法加时效类内容啊,有没有其他的操作点啊?
然后家人们开始盘点了起来:原创、伪原创、AI原创、提高内容质量、加外链、内链布局等等等。
好吧,太乱了,也太复杂了,大家讨论完之后又不知道如何下手了。
先说结论:增加收录的核心操作方向是针对高需求低竞争的流量词产出合理质量的内容。
1、决定收录的上游是需求的多少
搜索派多少个爬虫去爬咱们的网站、每隔多长时间爬一下咱们的网站不是胡来的,每个搜索引擎都会按照行业的需求量的大小分派对等的蜘蛛量级。
比如,我们从爱站词云上对比一下 作文、健身 两个行业。
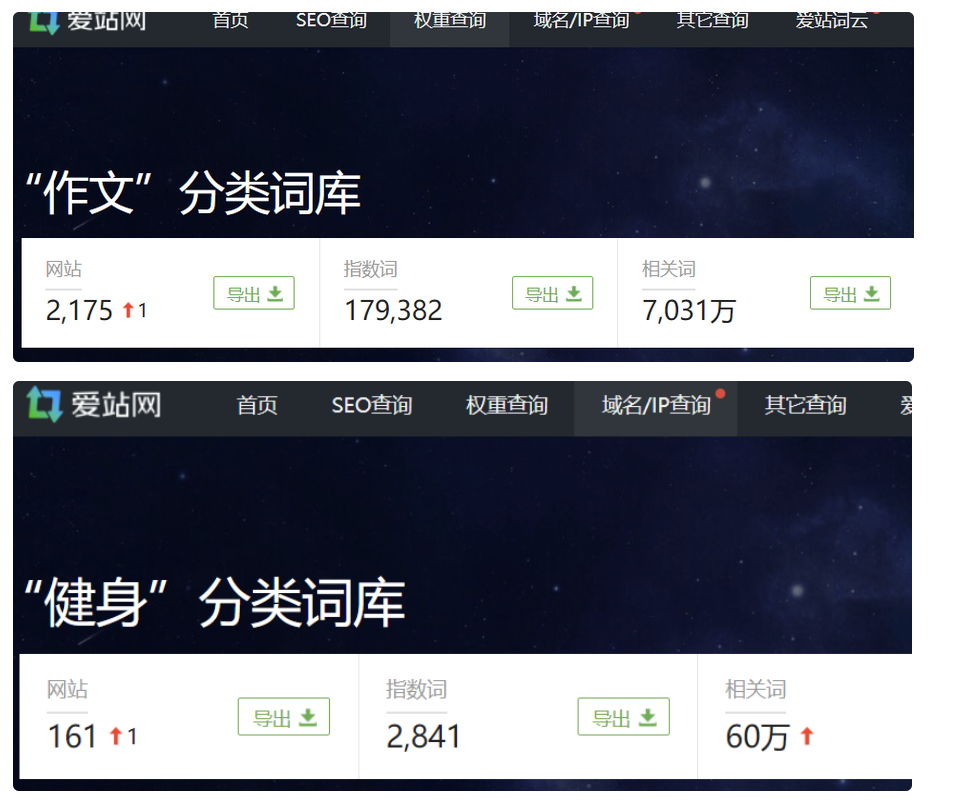
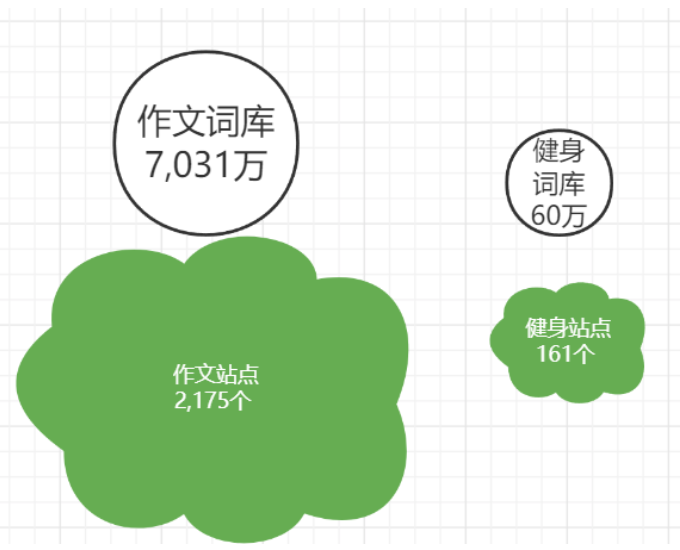
作文站单个站点平均词库在3万+,而健身站平均词库只有4千个不到。
所以:
1、一个健身站要想在几个月内有几十万收录难啊
2、一个健身站要想在10年内几十万收录也难啊
3、一个健身站要想有几十万收录,请先让搜索引擎认为健身行业搜索需求很大很大。
2、决定收录的下游是网站内容是否有竞争力
之前在论坛上看到一段话,觉得非常有道理的样子。

但是搜索本质上是一个竞争算法,如果大家的内容都摆烂,百度总不能给用户一个空白页面吧。
所以不管你纯采集,还是替换、打乱伪原创等,只要你做的词其他站玩的少或者竞争度够LOW,百度就会降低内容审验门槛,给一部分坏坏的网站留下了操作空间。
所以内容质量不是越好越收录,你所在的行业内容图多,你的内容也要图多,你所在的行业文字多,你的内容就没有必要加图,你所在的行业采集多,你的内容为啥不采集呢?所以内容长度、内容原创度、内容图文丰富度合理即可。
综上
因为在百度体系下,不同行业的搜索算法有不同的策略,收录算法也是如此,所以,针对高需求低竞争的流量词产出合理质量的内容,即是增加收录的核心操作方向。
二十五、SEO内参(25) 链接算法:主题敏感的Pagerank算法
一、原生PageRank算法
首先,PageRank算法的核心思想是,一个好的网站,有好的内容,自然就有大量的粉丝网站做外链,PR自然就高高的。具体两个子算法如下:
1、一个网页收到的其他网页指向越多,说明网页越重要,越牛逼。

2、当一个牛逼的网页指向一个网页,说明这个被指向的网页也很牛逼。
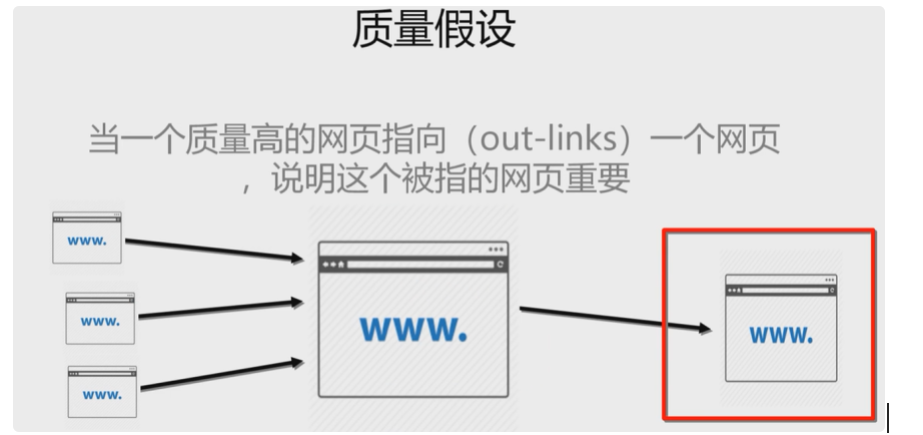
但是这就出现一个问题,一个垃圾网页靠刷外链就能获得好的权重,所以这个链接靠谱还是不靠谱呢,就产生了《主题敏感的Pagerank算法》。
二、主题敏感的Pagerank算法
前面提到,PageRank忽略了主题相关性,导致结果的相关性和主题性降低,也就是锚文本均可以对超链接指向的页面 内容进行高度概括,并相当程度上反映出该页面的内容。
但是,咱人都不老实啊,所以互联网上存在大量的超链作弊行为,锚文本与超链接指向页面之间不再总 是内容高度相关,当搜索引擎基于锚文本来获取搜索结果时,甚至还 有可能出现与查询序列内容不相关而排名却很高的网页。
所以百度在2010年前后上线了基于《主题敏感的Pagerank算法》。有兴趣的可以参考百度的专利《 CN201010620055.4 一种用于确定超链接的锚文本可信度的分析设备和方法》
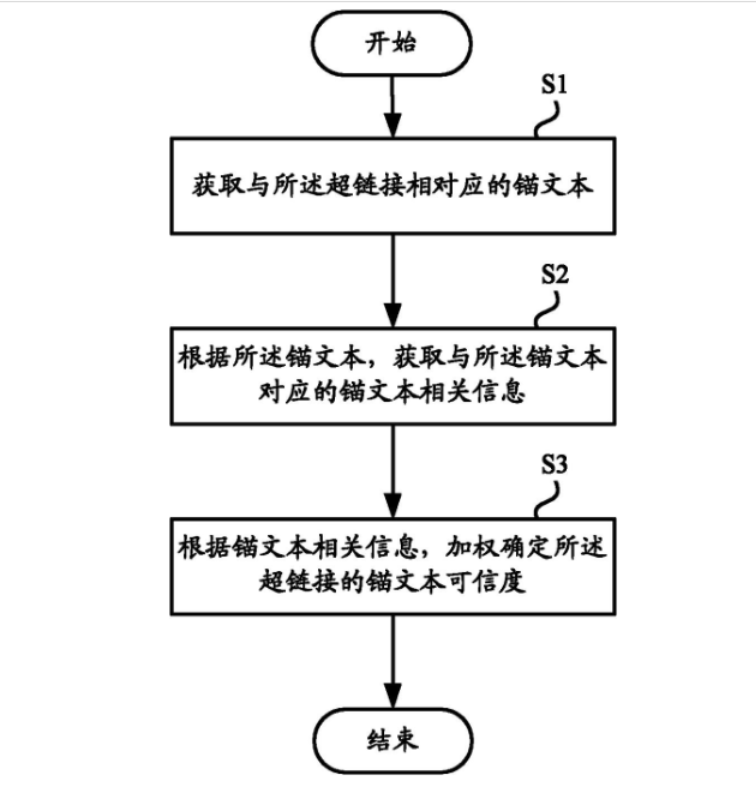
1、首先,遍历某个网页所有的入链链接,根据锚文本做主题分类。
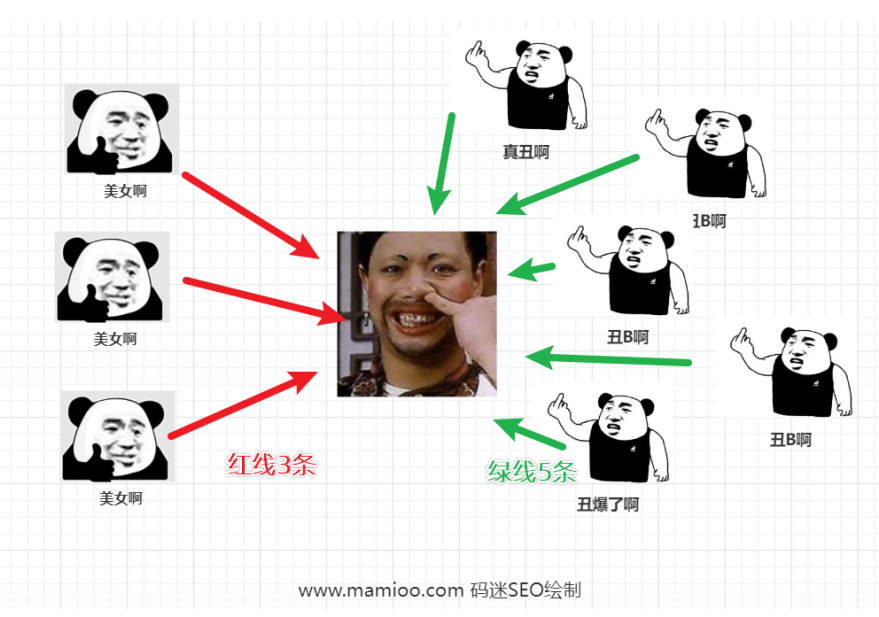
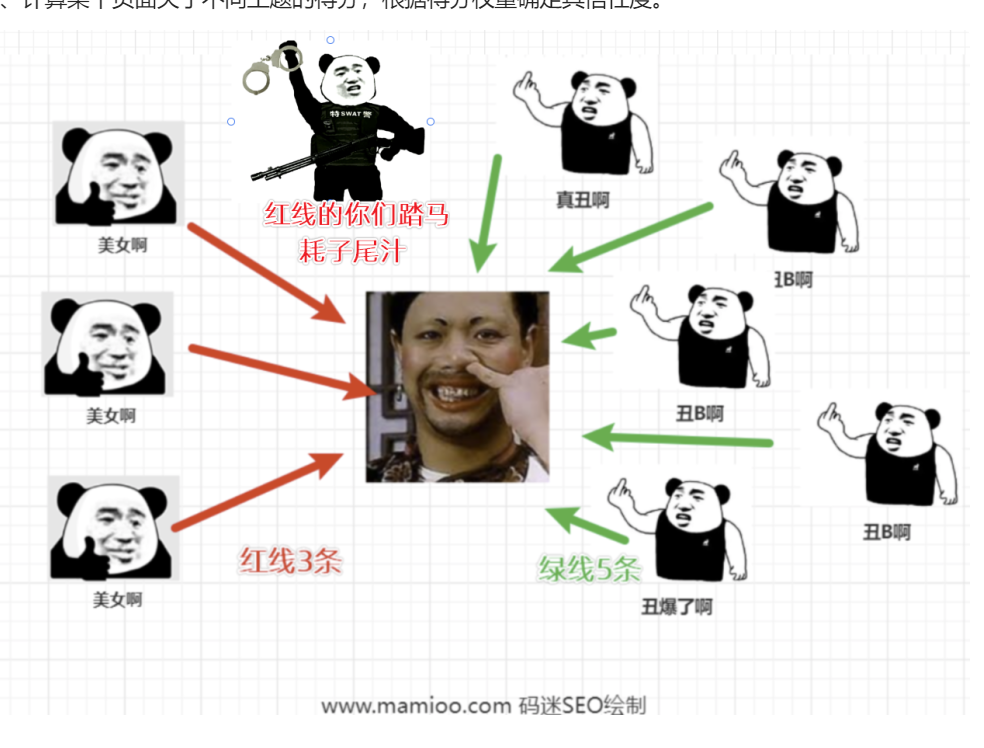
2、计算某个页面关于不同主题的得分,根据得分权重确定其信任度。
三、PageRank的缺点及应用
PageRank算法的缺点主要有两个。
1、太容易被作弊了
比如:卢松松的超级SEO外链工具
还有的通过黑K技术,批量入侵他人网站,挂海量黑链。还有把网站挂到蜘蛛池。
2、信任加权脱离实际页面内容
主题敏感的Pagerank算法尽管能解决相关性信任度问题,但是无法解决内容质量问题。
比如通过链接农场的方式,对某个页面加海量的相关性锚文本(也可以是301跳转),就能骗取搜索引擎的信任,达到篡改标题的效果。
其次,PageRank的缺点还存在加权方向是单向,缺乏时效性,所以还有一大波链接算法在2010~2012年前后陆续上线。
二十六、SEO内参(26) 链接算法:HITS信任度算法
编者按(2023):
略微烧脑
无论是谷歌还是百度,网站初期的外链很重要的。
网站起来后,内链更重要
正文开始:
链接分析无非为两种,一种为PR权重分析算法,通过主题敏感的PageRank算法,让搜索引擎感知到某个网站在某个专业领域的链接权重。另外一种为链接信任度算法,码迷认为HITS算法、TrustRank算法、黑链识别等算法,让搜索引擎感知到某个链接信任度,从而提高链接分析算法的健壮性。
路人甲:老码,你能不能说点人话啊,上面这个自然段听不懂!!
OK, 我们开始。
一、信任度提升算法(HITS算法)
在《SEO内参》里面,我常常用“女友的电话薄”来做例子。
话说老王女友这几天老是接到大明星的电话,比如李某峰、吴签,还有钢琴王子李某迪也时不时来嘘寒问暖,老王顿时觉得女友高大了起来,嗯,这就是PageRank算法。

那反过来说,如果女友的电话薄里面,同时存放了三个大明星的手机号码,那这个女友大概率也来头不小啊。
这就是HITS算法的假设核心:
核心1:一个好的“权威”页面会被很多好的“非权威”页面指向;
核心2:一个好的“非权威”页面也会指向很多好的“权威”页面;

二、HITS算法应用
1、同行业高权重网站的互链很宝贵,要珍惜。
2、HITS算法是用来增加权威信任度的,要大胆的干。
3、即使同行高权重网站不鸟你,你网站上也应该挂上同行业高权重的单链,不吃亏啊
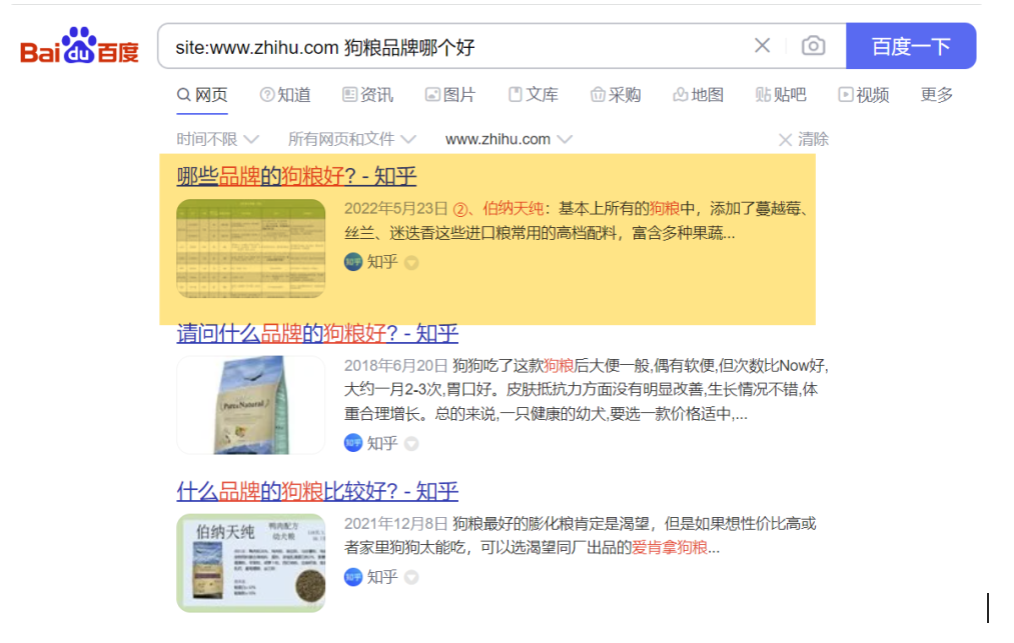
4、在单个内容质量合理的前提下,加10个以内高权重网站的高质量相关内页,对单页排名很有帮助。
5、比如你的网站有个内页是讨论狗粮品牌的,你到知乎、新浪、163这类高权重网站上搜集高质量相关内页,把他链接放到你的网站上,真的有效果。
三、信任度降低算法(TrustRank算法)
前面提到的HITS算法并不会降低您的网页信任度,甚至单纯的PageRank算法也只是会增加权重,这就导致了存在时间越久的网站,PR就越来越大,而新网站PR就增长的很慢,天下不公,这就麻烦了。
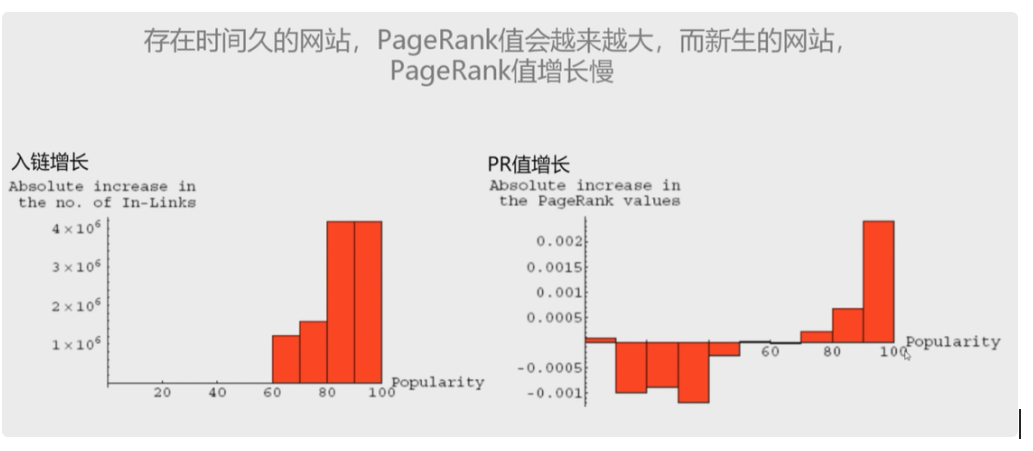
所以,新的TrustRank算法就来打补丁了。TrustRank算法有1个基本假设,3个衰减算法。
1、基本假设
信任度好的页面往往不会指向一个垃圾页面(Spam Page)
简单的说,乖乖女是不会存哪些坏蛋的电话号码的,但是如果乖乖女的电话薄里面都是从李某峰、李某迪到吴签之类的,那大概率也不是好姑娘。
2、衰减算法
信任传递衰减:信任页面授予的可信度随着距离的增加而衰减
信任时间衰减:指向消失后,可信度随着时间的流逝而衰减
信任分裂衰减:一个信任页面指向的网页越多,则每个网页分到的信任值越少
简单的说
1、信任度在空间时间上都是逐渐衰减的,做了坏事不要紧,每个人都有改过自新的机会。
2、每个网页会有一个初始信任值,出链越多,汤肉越少。
TrustRank算法的玩法
1、基本玩法
a、不要给降权的网站做友情链接,也不要给黄赌毒四害网站做友情链接。
b、至少每半个月检测一下友链是否降权,同时检测自己的网站是否有黑K入侵,挂了黑链。发现后尽早除之。
c、新站也是有初始信任度的,只要内容正规、收录正常、非降权网站,也是可以做友链的,新站可以和新站换。
d、导出链接过多(>50)的不换,权重还比我低的其实可以换。
e、友情链接不必注重相关性。
f、黄赌毒
2、高级玩法
a、有日收、周收的网站,无论权重如何,应该积极做友情链接
b、没有日收、周收的,比我低的权重网站,链接最多保留2~3个月
c、保持我方首页友情链接在30~40个之间即可,多则删之(对方下不下链无所谓)
3、高高级玩法
a、花钱给竞争对手做100+的四害网站单链,竞争对手会感谢你八辈子的
b、有流量的内页信任度不要浪费,应该多给未收录的高质量网页加推荐链接(侧栏底栏均可)
c、A站有流量的内页可以给F站未收录的高质量网页做推荐链接,但是F站不要给A做反链
d、A、B、C、D、E站有流量的内页可以给F站未收录的垃圾网页做推荐链接,这叫真正的蜘蛛池
e、A、B、C、D、E站没有流量的内页给F站未收录的垃圾网页做推荐链接,这叫假的蜘蛛池
综上,除了以上算法还有黑链检测算法,具体的大家可以查看百度专利《CN201210049496.2 一种检测黑链的方法和装置》。
另外相关性链接分析算法如HillTop算法还有不少,大家可以自行探索。
二十七、SEO内参(27) 对于秒收、日收、周收的几个小窍门
废话不说,直接上干货。
1、秒收日收也分行业
热搜文章及其他时效性内容(新闻、票务等),相对容易达到日收、秒收。
其他行业要达到日收很难,一般周收、月收就不错了
时效性较差的行业,即使网站量级很大也不一定周收,反而每7~30天索引大更新。
PS:非泛内容站,达不到秒收日收不重要,索引稳步上涨就是好事。
2、多发时令节日相关内容
有搜索量才有收录的后劲,
作文行业,如母亲节、父亲节、国庆节都会有大量的搜素需求,谁上新内容谁收录刚刚滴
教育行业,高考、开学、择校都是时令性搜索量变大的时候,同时要求内容最最新,所以要把今年的内容提前准备好。
价格、分数线等时效性内容,一定要在标题中加入 【最新】【年份】
3、内链玩法
有流量的内页不要浪费,应该多给未收录的高质量网页加推荐链接(侧栏底栏均可)、
A站有流量的内页可以给F站未收录的高质量网页做推荐链接,但是F站不要给A做反链
瑞文系的网站为啥子都这么牛逼,人家真正把内链搞明白了。
4、敏感关键词库
政Z类、黄DD、体育、彩漂、菠菜类的词,一定要做清理。一旦被搜索引擎监控到了,掉日收是分分钟的事情。

5、企业备案加保障
有保障可以大幅提高网站信任度,该上就上
二十八、SEO内参(28) 揭秘快速收录的背后黑帽手法原理
百度搜索引擎指定链接24小时内快速收录,有索引,标题可匹配到,无效全额退款。不知道大家遇到过没有。看到之前有的人高收录,开始的时候10元每条,现在涨到150元一条。当然这波人的套路一定是先付款后做收录,不收录就退款。
先说原理:百度快照更新的时机
通常情况下,百度对于已经收录索引,快照更新由几个因子触发。
1、爬虫根据网页更新频率大致预估更新周期,周期性抓取网页。
2、某网页访问人次积累到一定阀值,爬虫会有审查性复查该网页合规。
3、快照被投诉后,爬虫会有审查性复查该网页是否合规。
4、当某网页外链积累到一定阀值,爬虫会有审查性复查该网页合规。
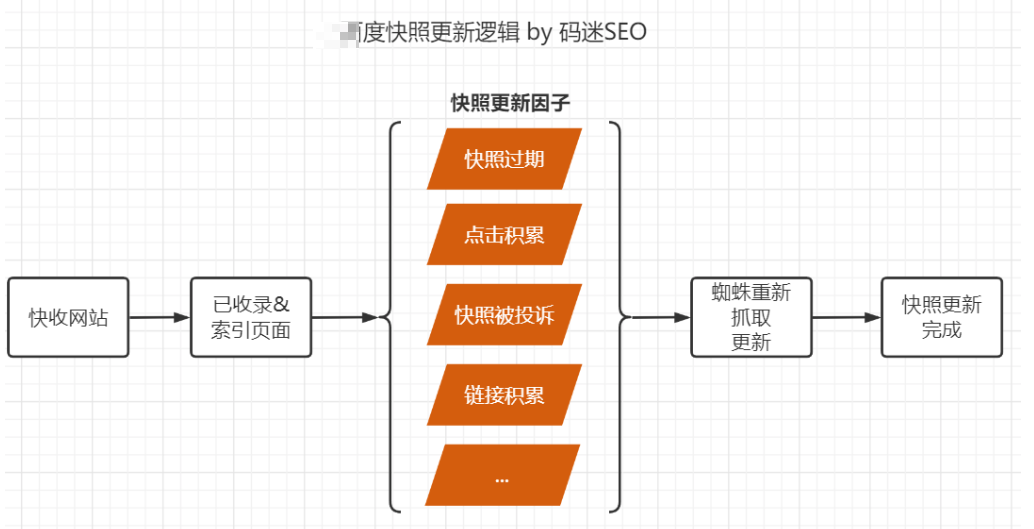
那么重点在“网页合规”这块,通常高信任度的域名、有点击量的网页已经收到用户的认可,那么新版快照的形成必然走快收的流程,而不是初次收录复杂的流程。
所以,机会来了。
步骤1:准备1个有日收或者快收权限的网站
快收网站不是必要的,只要能达到日收,说明在百度眼里,这个网站是有一定信任度的,具备走快速收录通道的必要条件。
步骤2:创造快照更新的触发因子
如果快照不自动更新,那就人为干预,创造条件呗,如下图:
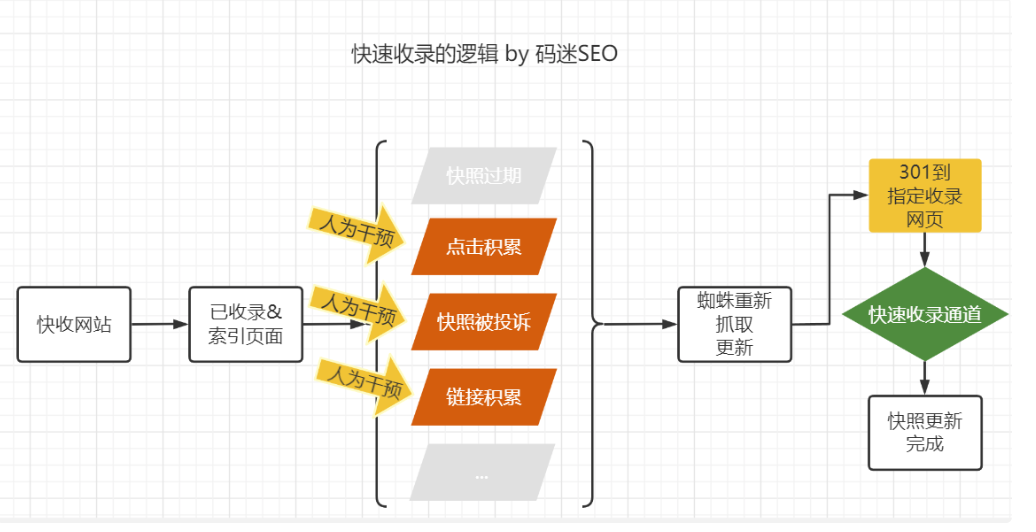
1、通过点击的方式促进快照更新,这个大家一般不用。
2、快照投诉
这个是快收最流行的手段,在过去3年,站长们都风靡于利用快照漏洞去提交url进行收录,有的站长会把新的url封装成快照链接进行提交(已经失效),后来演变成通过反推算法猜网址进行投诉。

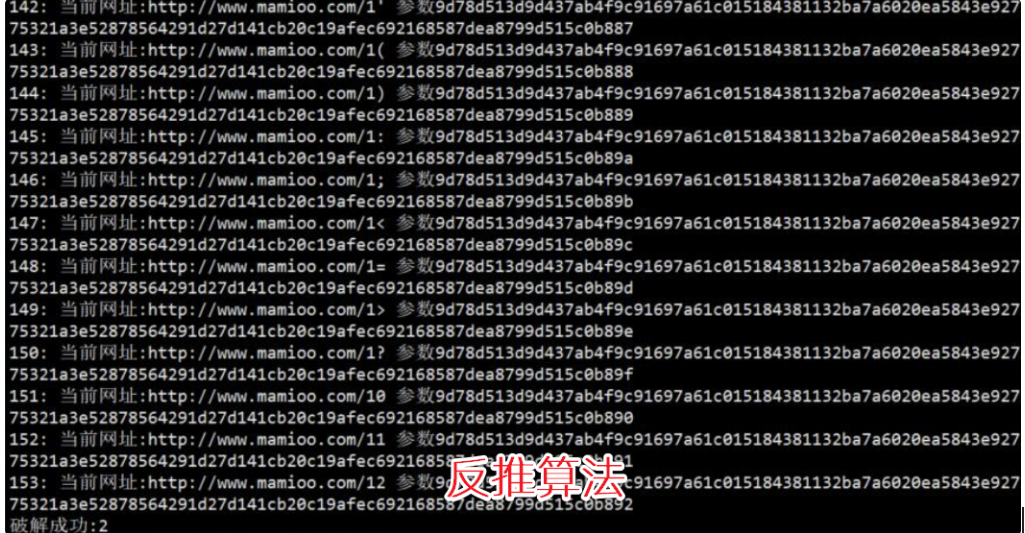
被站长们搞出花样之后,百度工程师估计是为了封堵快照漏洞,搜索快照功能已经在2022年8月份下架了。这就蛋疼了。
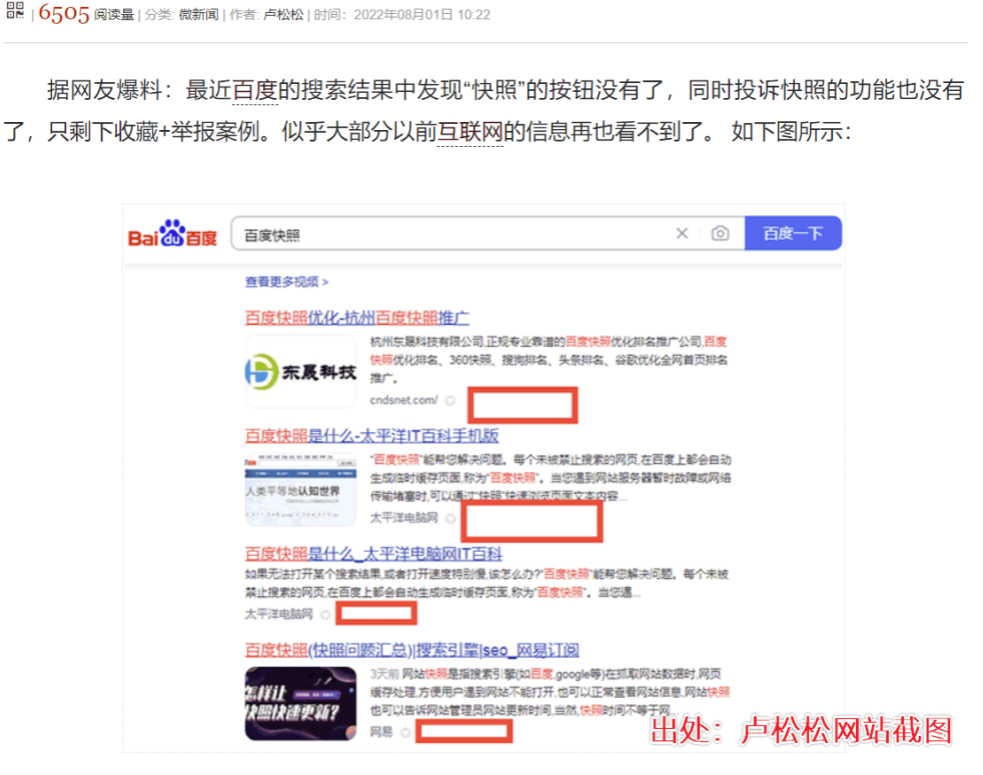
3、链接积累
链接积累的意思是,当一个页面网址被多个网页指向,大大大概率会迎来快照更新蜘蛛。就是针对快收网站的某个页面,挂一波蜘蛛池或者外链,也有几率推进快照更新了。
步骤3:爬虫劫持
如果第2步搞定,终于来蜘蛛了,而且这个蜘蛛抓取后,咱前面说了,大概率是走快速收录通道了。所以301到指定要被收录的网址就行了。
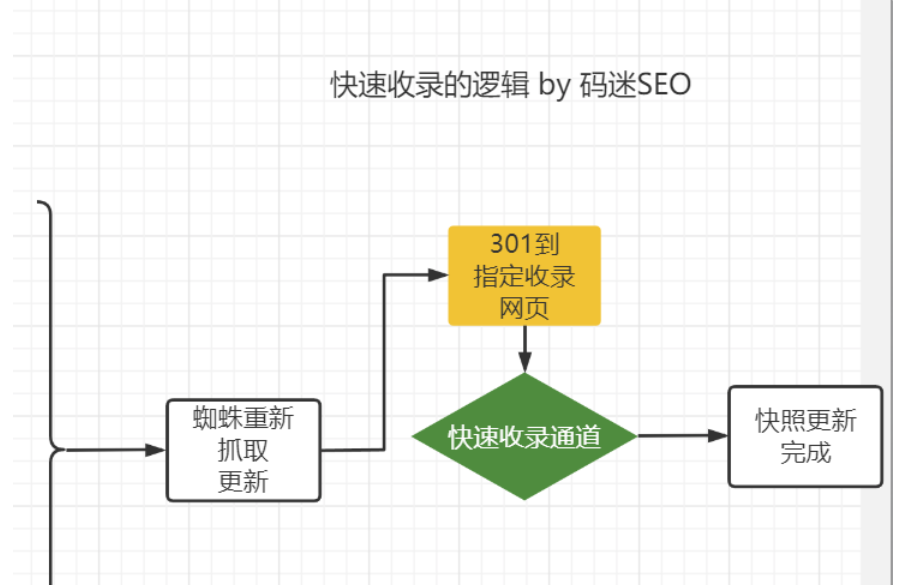
理论是美好的,但是实操来讲,咱要有一个快收权限的网站,这个是成本一;其次待收录的网站页面的代码质量、内容质量、服务器稳定性、行业合法性都是不可控的,所以推10次能有1次收录也要看天意了。。
二十九、SEO内参(29) 外推以及搜索留痕黑帽手法解析
外推留痕算是黑帽SEO手法的两种手段,手法非常类似,所以码迷SEO就放到一块儿说。
外推留痕本来是一种非常中立的SEO技术,但是用的人大量发布垃圾信息,所以硬生生变成了大家口中的黑帽SEO技术。外推留痕在百度、谷歌、搜狗上依然有效果,在头条、360等平台效果不大(审核太严或者体量不足)。
一、什么是外推
百度百科:外推是SEO中的一种,又称为站外推广。 主要是通过在分类信息网站、论坛、B2B、博客等平台来发布与自己所要推广的产品有关系的信息。
现实中:是通过直接在微博、知乎、知名论坛等平台来发布垃圾信息的手段。
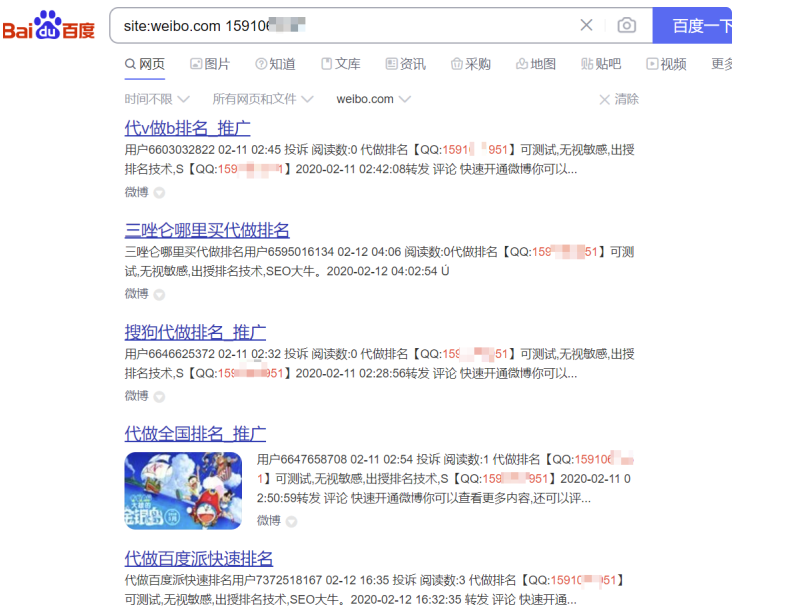
二、什么是留痕
知乎:我们说的搜索留痕大部分是指利用某些网站的搜索功能,大量产生带有自己广告关键词的页面,使其被百度收录,同时利用这些网站在百度上的权重让自己的关键词快速参与排名,达到引流拓客的效果。
三、外推与搜索留痕现状
从2021年中,百度方面加大了内容合规的审查力度,大部分境外网站已经无法再用外推与搜索留痕了。比如基情网站github
收录时间,看平台,像微博这类秒收站,发完后既有收录,其他平台半个月~几个月不等。
搜索结果页留痕时间,一般在7天内了,留痕太明显了,半天就没了。
搭配优质蜘蛛池,可以大幅度提高站点收录速度。
四、外推的核心逻辑
外推、留痕的核心逻辑就是搞定收录!
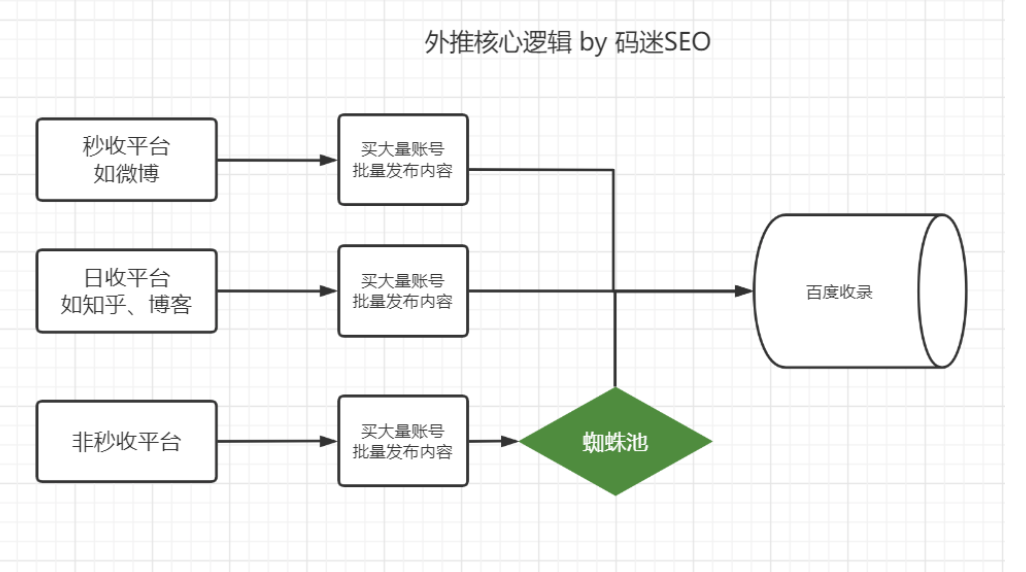
1、第一个逻辑,如何在被判定为营销信息之前搞定收录。
有的平台发了内容后,直接收录,达到秒收的效果,比如某些高权重的微博账户、某些高权重的知乎账号。所以,做外推,要搜罗大量的账号,在发内容的过程中也会不断废掉账号。
2、第二个逻辑,积极发现审核门槛宽松且收录快的论坛。
有些新上的平台能达到日收的效果,而且内容审核比较宽松,比如一些技术博客、售后服务论坛等。比如前一段时间某度的AI论坛被恶意营销灌水,但是机会是转瞬即逝的,管理员发现后,就直接删帖了。
3、第三个逻辑,没有日收的平台如何搞定收录
一般会用优质蜘蛛池,那种干干净净没有挂太多垃圾链接的蜘蛛池。
最后:
市面上不存在长久使用的外推搜索留痕软件,大部分都是深度定制的,这类软件见光死。
多行善事,必得善缘,众生皆安。
三十、SEO内参(30) 限时ChatGPT工具 软件 资料 领取
注意:
所有软件均免费,同时没有售后支持
科学上网这件事,您自行百度解决
要偷偷留私房钱的,看下图
1、ChatGPT批量生成工具(带双标题)尝鲜版
提取码:6666
备注:
本软件不支持跑在梯子上,因为容易封号!!!因为大部分梯子共享一个IP会导致OPENAI封号!!!不提供售后支持,也不提供有偿付费支持。

2、百度SEO核心专利整理
提取码:6666
3、头条采集程序(带双标题)
提取码:6666
自动采集+聚合(原创度非常好)
利用群发工具可实现自动发布文章
操作简单,只需放好关键词,一行一个,双击运行即可
u地址转错 【TYkriVwSJnMHm7wLLwkzNFekakiiRUjh4m】转错请联系TeleGram:【@TrxEm】